大数据Spark与Storm技术选型

先做一个对比:
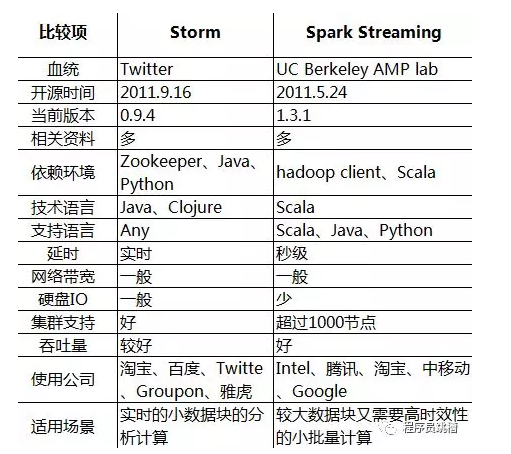
|
对比点 |
Storm |
Spark Streaming |
|
实时计算模型 |
纯实时,来一条数据,处理一条数据 |
准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
|
实时计算延迟度 |
毫秒级 |
秒级 |
|
吞吐量 |
低 |
高 |
|
事务机制 |
支持完善 |
支持,但不够完善 |
|
健壮性 / 容错性 |
ZooKeeper,Acker,非常强 |
Checkpoint,WAL,一般 |
|
动态调整并行度 |
支持 |
不支持 |
再来说说Spark Streaming与Storm的应用场景

先说一下Storm:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择

Spark 呢:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
推荐阅读:
filebeat+kafka+strom+logstash+es 舆情采集系统
微信公众号:
大数据Spark与Storm技术选型的更多相关文章
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
- 【Todo】【读书笔记】大数据Spark企业级实战版 & Scala学习
下了这本<大数据Spark企业级实战版>, 另外还有一本<Spark大数据处理:技术.应用与性能优化(全)> 先看前一篇. 根据书里的前言里面,对于阅读顺序的建议.先看最后的S ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- 大数据Spark超经典视频链接全集
论坛贴吧等信息发布参考模板 Scala.Spark史上最全面.最详细.最彻底的一整套视频全集(特别是机器学习.Spark Core解密.Spark性能优化.Spark面试宝典.Spark项目案例等). ...
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评“2018中国大数据基础软件领域领军企业”,并成功入选中国数字化转型TOP100服务商. 图:大快搜索获评“2018 ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 大数据 --> Spark与Hadoop对比
Spark与Hadoop对比 什么是Spark Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法 ...
- 以慕课网日志分析为例-进入大数据Spark SQL的世界
下载地址.请联系群主 第1章 初探大数据 本章将介绍为什么要学习大数据.如何学好大数据.如何快速转型大数据岗位.本项目实战课程的内容安排.本项目实战课程的前置内容介绍.开发环境介绍.同时为大家介绍项目 ...
随机推荐
- 快速制作U盘启动盘和U盘安装盘的方法
制作U盘启动盘的方法: 1. 安装UltraISO; 2. 安装完成后,用管理员权限打开UltraISO; 3. 打开启动盘文件,一般为ISO文件: 4. 插入U盘: 5. 选择 启动 -> 写 ...
- 分布式文件系统 / MQ / 鉴权(轮廓)
FastDFS的轮廓 / RabbitMQ的轮廓 / JWT和RSA非对称加密的轮廓
- JavaScript的文档对象模型DOM
小伙伴们之前我们讲过很多JavaScript的很多知识点,可以点击回顾一下: <JavaScript大厦之JS运算符>: <JavaScript工作原理:内存管理 + 如何处理4个常 ...
- 超实用的 Nginx 极简教程,覆盖了常用场景
概述 什么是 Nginx? Nginx (engine x) 是一款轻量级的 Web 服务器 .反向代理服务器及电子邮件(IMAP/POP3)代理服务器. 什么是反向代理? 反向代理(Reverse ...
- Git基本命令 -- 基本工作流程 + 文件相关操作
可以先找一个已经被git管理的项目, 我就使用这个项目吧: https://github.com/solenovex/ID3-Editor 基本工作流程 克隆以后呢, 进入该目录查看一下状态: 然后添 ...
- Java IO API记录
文件路径: public static final String FILEPATH= File.separator+"Users"+ File.separator+"xu ...
- struts2整合uploadify插件怎样传参数
关于uploadify3.1,先看下帮助文档中的有些知识. 其中有个onUploadStart方法,我们可以使用这个向后台传参. 下面举个例子, js: <script type="t ...
- Chapter 4 Invitations——2
To my dismay, I found myself the center of attention for the rest of that week. 令我沮丧的是, 我发现我自己剩余注意力的 ...
- 后端不会写页面怎么办?推荐几个好用的前端UI模板、组件对比
前言 下面推荐并对比几个好用的前端UI模板 推荐给以下的人使用: 1.不想重复造轮子的后端 2.不想学bootstrap的后端 3.后端开发想自己写简单页面的 4.偷懒的前端 本文注重手机端,对web ...
- 函数式编程之-F#类型系统
在深入到函数式编程思想之前,了解函数式独有的类型是非常有必要的.函数式类型跟OO语言中的数据结构截然不同,这也导致使用函数式编程语言来解决问题的思路跟OO的思路有明显的区别. 什么是类型?类型在编程语 ...