编译Spark源码
Spark编译有两种处理方式,第一种是通过SBT,第二种是通过Maven。作过Java工作的一般对于Maven工具会比较熟悉,这边也是选用Maven的方式来处理Spark源码编译工作。
在开始编译工作前应当在自己的系统中配置Maven环境
参考Linux上安装Maven方案:
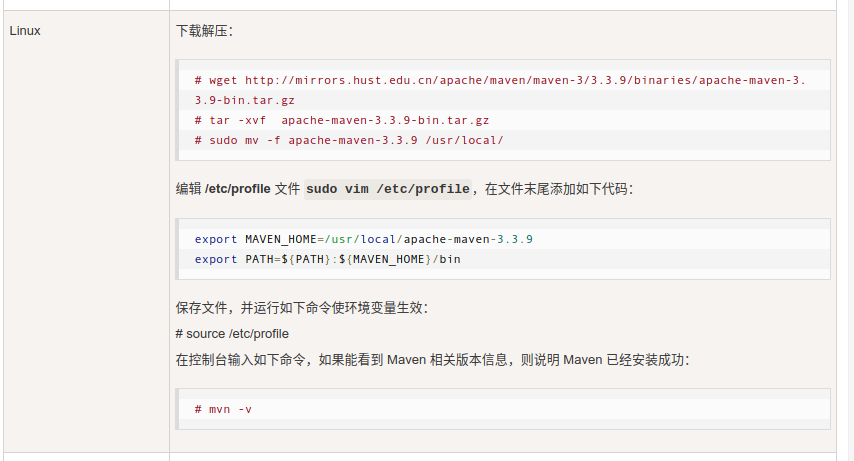
http://www.runoob.com/maven/maven-setup.html
编译的对象也有两种选择,第一个是下载的Apache Spark版本,这种情况不用对Maven的默认配置进行修改即可直接编译成功;第二个是Hortonworks公司所提供的Spark,他们的编译工作使用了hortonworks公司的私人远程远程库,所以需要简单配置一下,具体参考:https://www.cnblogs.com/yuanyifei1/p/9122880.html
打开spark项目根目录下pom.xml,找到repositories节点,添加 <repository>
<id>public</id>
<url>http://nexus-private.hortonworks.com/nexus/content/groups/public</url>
</repository>
如果不配置仓库直接使用mvn -DskipTests clean package编译HDP的spark2源码,会报错找不到jar包。
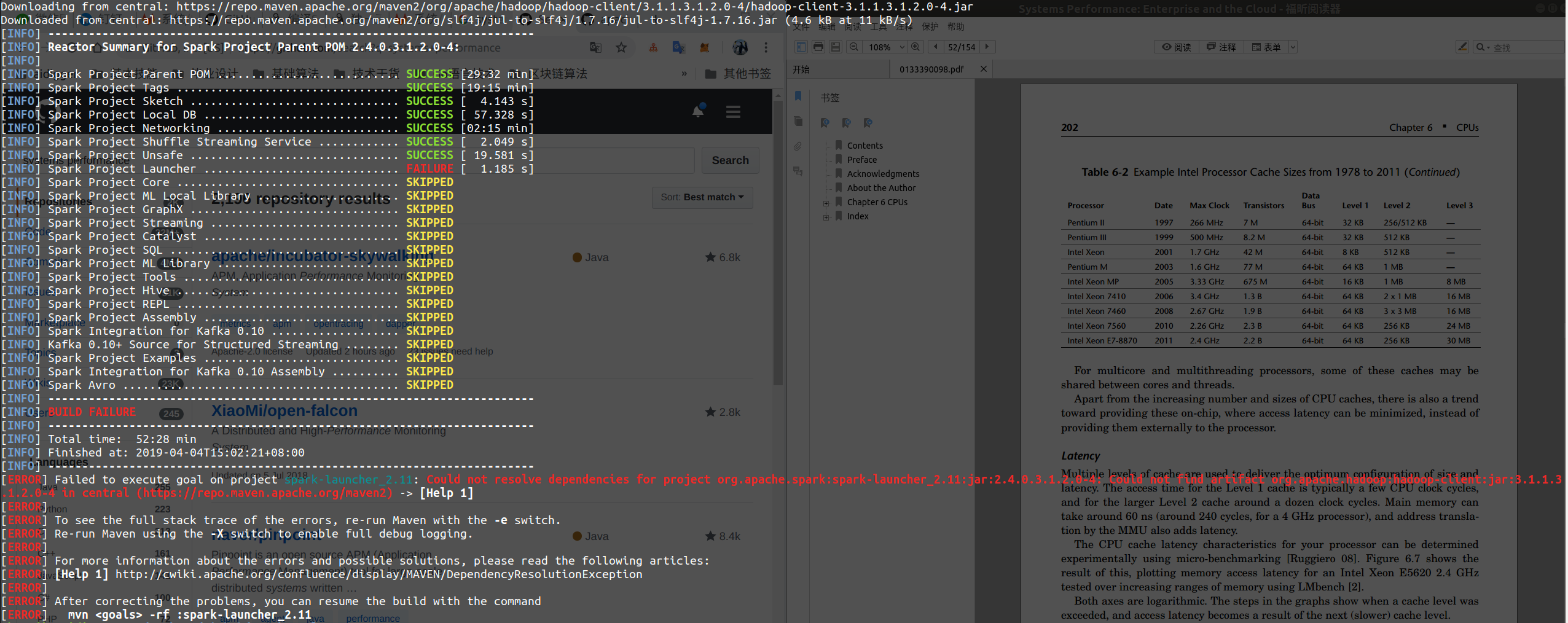
在此基础上将包配置一下。
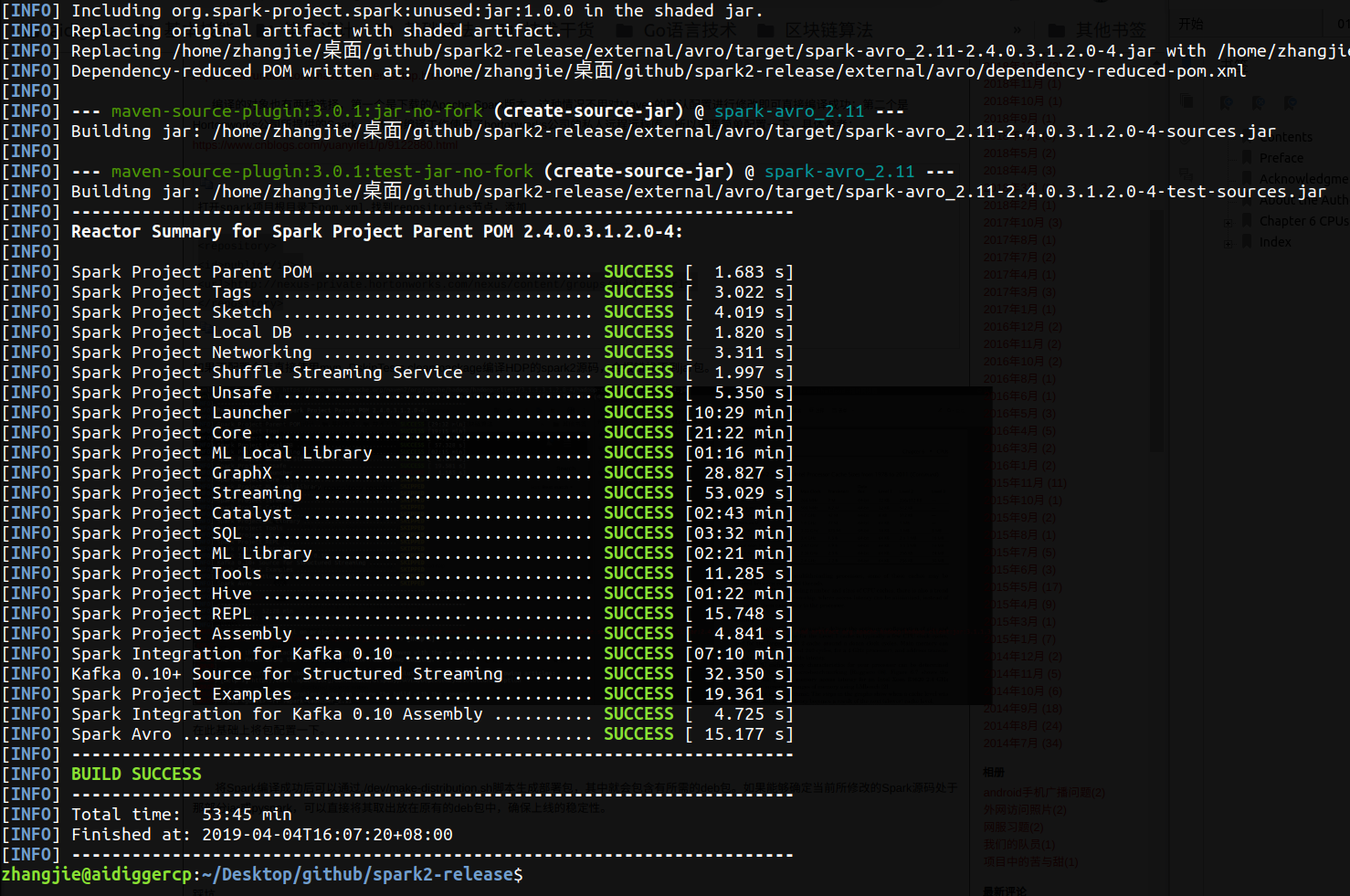
将Spark编译成功后可以通过./dev/make-distribution.sh脚本生成部署包,其中就会包含有所需的deb包。如果能够确定当前所修改的Spark源码处于那部分jar或pyspark,可以直接将其取出放在原有的deb包中,确保上线的稳定性。
将Hortonworks所提供的源码编译打包后需要对其进行安装工作。他们本身是不欢迎对源码进行修改上线的,在安装包中也是配置了GPG校验,在安装工作时需要对加密文件进行破解后安装。
踩坑
main:
[exec] fatal: 不是一个 git 仓库(或者直至挂载点 / 的任何父目录)
[exec] 停止在文件系统边界(未设置 GIT_DISCOVERY_ACROSS_FILESYSTEM)。
[exec] fatal: 不是一个 git 仓库(或者直至挂载点 / 的任何父目录)
[exec] 停止在文件系统边界(未设置 GIT_DISCOVERY_ACROSS_FILESYSTEM)。
[INFO] Executed tasks
[INFO]
[INFO] --- maven-resources-plugin:2.7:resources (default-resources) @ spark-core_2. ---
[INFO] Using 'UTF-8' encoding to copy filtered resources.
[INFO] Copying resources
[INFO] Copying resource
[INFO] Copying resources
[INFO]
[INFO] --- maven-compiler-plugin:3.7.:compile (default-compile) @ spark-core_2. ---
[INFO] Not compiling main sources
[INFO]
[INFO] --- scala-maven-plugin:3.2.:compile (scala-compile-first) @ spark-core_2. ---
[INFO] Using zinc server for incremental compilation
[warn] Pruning sources from previous analysis, due to incompatible CompileSetup.
[info] Compiling Scala sources and Java sources to /home/zhangjie/spark-2.3./core/target/scala-2.11/classes...
[error] /home/zhangjie/spark-2.3./core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala:: value getLocalProperties is not a member of org.apache.spark.TaskContextImpl
[error] val localProps = context.asInstanceOf[TaskContextImpl].getLocalProperties.asScala
[error] ^
[error] one error found
[error] Compile failed at Dec , :: PM [.814s]
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Spark Project Parent POM 2.3.:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 1.751 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 9.577 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 2.242 s]
[INFO] Spark Project Local DB ............................. SUCCESS [: min]
[INFO] Spark Project Networking ........................... SUCCESS [ 16.155 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 2.053 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 24.178 s]
[INFO] Spark Project Launcher ............................. SUCCESS [: min]
[INFO] Spark Project Core ................................. FAILURE [: min]
[INFO] Spark Project ML Local Library ..................... SKIPPED
[INFO] Spark Project GraphX ............................... SKIPPED
[INFO] Spark Project Streaming ............................ SKIPPED
[INFO] Spark Project Catalyst ............................. SKIPPED
[INFO] Spark Project SQL .................................. SKIPPED
[INFO] Spark Project ML Library ........................... SKIPPED
[INFO] Spark Project Tools ................................ SKIPPED
[INFO] Spark Project Hive ................................. SKIPPED
[INFO] Spark Project REPL ................................. SKIPPED
[INFO] Spark Project Assembly ............................. SKIPPED
[INFO] Spark Integration for Kafka 0.10 ................... SKIPPED
[INFO] Kafka 0.10 Source for Structured Streaming ......... SKIPPED
[INFO] Spark Project Examples ............................. SKIPPED
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: : min
[INFO] Finished at: --24T15::+:
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.:compile (scala-compile-first) on project spark-core_2.: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.:compile failed.: CompileFailed -> [Help ]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help ] http://cwiki.apache.org/confluence/display/MAVEN/PluginExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :spark-core_2.
原因是修改Scale源码后没有修改干净,遇见这种问题还是要将自己所修改的代码仔细review一波
同时在编译源码是注意路径中不要出现中文名,会导致编译出现卡死的情况;
参考资料:
https://www.cnblogs.com/yuanyifei1/p/9122880.html#undefined
编译Spark源码的更多相关文章
- 编译spark源码及塔建源码阅读环境
编译spark源码及塔建源码阅读环境 (一),编译spark源码 1,更换maven的下载镜像: <mirrors> <!-- 阿里云仓库 --> <mirror> ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- Spark笔记--使用Maven编译Spark源码(windows)
1. 官网下载源码 source code,地址: http://spark.apache.org/downloads.html 2. 使用maven编译: 注意在编译之前,需要设置java堆大小以及 ...
- Windows使用Idea编译spark源码
1. 环境准备 JDK1.8 Scala2.11.8 Maven 3.3+ IDEA with scala plugin 2. 下载spark源码 下载地址 https://archive.apach ...
- window环境下使用sbt编译spark源码
前些天用maven编译打包spark,搞得焦头烂额的,各种错误,层出不穷,想想也是醉了,于是乎,换种方式,使用sbt编译,看看人品如何! 首先,从官网spark官网下载spark源码包,解压出来.我这 ...
- Windows环境编译Spark源码
一.下载源码包 1. 下载地址有官网和github: http://spark.apache.org/downloads.html https://github.com/apache/spark Li ...
- Spark—编译Spark源码
Spark版本:Spark-2.1.0 Hadoop版本:hadooop-2.6.0-cdh5.7.0 官方文档:http://spark.apache.org/docs/latest/buildin ...
- 编译spark源码 Maven 、SBT 2种方式编译
由于实际环境较为复杂,从Spark官方下载二进制安装包可能不具有相关功能或不支持指定的软件版本,这就需要我们根据实际情况编译Spark源代码,生成所需要的部署包. Spark可以通过Maven和SBT ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
随机推荐
- docker的安装和简单配置
docker的安装和简单配置 docker是balabalabala...懒得介绍. 国内安装docker很蛋疼,按照官方配置好了软件源之后,几十MB的安装文件下载要半天,没办法,docker默认的软 ...
- Servlet中清除session
HttpSession sessions = request.getSession(false);//防止创建Session if(sessions == null){ response.sendRe ...
- java二分法搜索
二分法就是要将数据每次都分成两份然后再去找到你想要的数据 在二分法查找时要求传入的数据必须已经有序,假设现在为升序,然后每次将所寻找的值与中间值(数组左边界+(右边界-左边界)/2)作比较,大了则去寻 ...
- vue---mint-ui组件loadmore(上拉加载,下拉刷新)
1. 先安装mint-ui 2. 在main.js中引入mint-ui的css样式和组件 import "mint-ui/lib/style.css"; import {Loadm ...
- position:fixed失效情况
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Tomcat的三种安装方式:解压版、安装版、配置成Windows服务版
https://blog.csdn.net/Jessica_XLF/article/details/81711429
- C# Common Code
DatePicker 控件日期格式化,可以在App.xaml.cs中添加下面代码 方法一 不推荐: Thread.CurrentThread.CurrentCulture = (CultureInfo ...
- 微信小程序超出两行省略号
display: -webkit-box; overflow: hidden; text-overflow: ellipsis; word-wrap: break-word; white-space: ...
- Git简单生成生成公钥和私钥方法
Git简单生成生成公钥和私钥方法 Git配置 Git安装完之后,需做最后一步配置.打开git bash,分别执行以下两句命令 git config --global user.name “用户名” g ...
- 基于centos7+nginx+uwsgi+python3+django2.0部署Django项目
0.序言 本文讲解如何基于centos7+nginx+uwsgi+python3+django2.0把windows上的本地项目部署到云服务器上. 本文服务器上的django项目和虚拟环境的路径将建立 ...