ASCII 、UTF-8、Unicode都是个啥啊,为啥会乱码啊?
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。

因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:

字符ASCIIUnicodeUTF-8A0100000100000000 0100000101000001中x01001110 0010110111100100 10111000 10101101
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
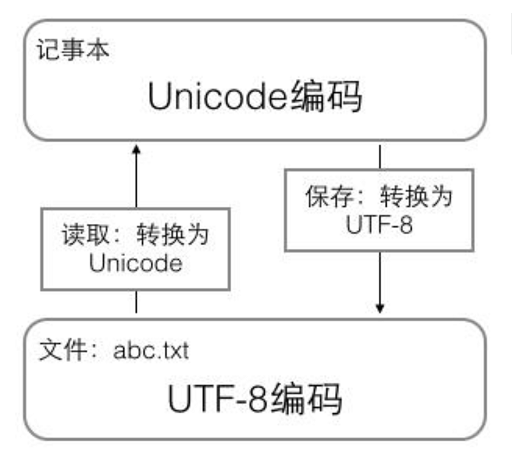
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
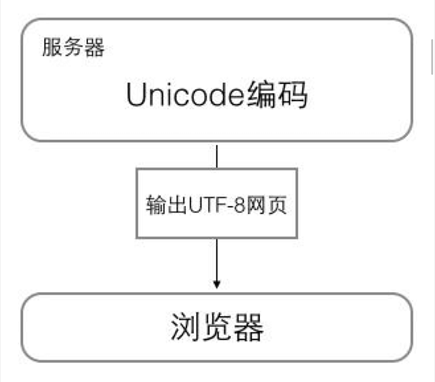
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
ASCII 、UTF-8、Unicode都是个啥啊,为啥会乱码啊?的更多相关文章
- 第48篇 字符编码探密--ASCII,UTF8,GBK,Unicode
原文地址:http://blog.laofu.online/2017/08/22/encode-string/ ASCII 的由来 在计算机的“原始社会”,有人想把日常的使用的语言使用计算机来表示, ...
- 初学者对ASCII编码、Unicode编码、UTF-8编码的理解
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是 255(二进制 11111111=十进制 255),如果要表示更大的整数,就必须用更多的字节. ...
- ASCII码与unicode字符集
问题1:为什么需要字符ASCII码.unicode码等等???它们到底有什么作用? 首先要明白一个事实:在计算机中只能用一系列存储着的0和1,当我们把一个字符存放在计算机时,我们是如何表示常用的字符呢 ...
- ASCII编码和Unicode编码的区别
链接: 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了.Unicode标准也在不断发展,但最常用的是用两个字 ...
- Java基础笔记(六)——进制表示、ASCII码和Unicode编码
Java中有三种表示整数的方法:十进制.八进制.十六进制. 八进制:以0开头,包括0~7的数字.如:int octal=020; //定义int型变量存放八进制数据 十六进制:以0x或0X开头,包括 ...
- 字符编码ANSI和ASCII区别、Unicode和UTF-8区别
ANSI码ANSI编码是一种对ASCII码的拓展:ANSI编码用0x00~0x7f (即十进制下的0到127)范围的1 个字节来表示 1 个英文字符,超出一个字节的 0x80~0xFFFF 范围来表示 ...
- 利用浏览器做好数字进制和ASCII码及Unicode教与学
浏览器是现在个人计算机的标配,一般来说一个PC至少安装一种以上的浏览器.主流网页浏览器有Google Chrome.Internet Explorer.Microsoft Edge.Mozilla F ...
- ASCII码、Unicode码 转中文
ASCII码.Unicode码 转中文 在最近工作中遇到了一些汉字编码转换的处理,可以通过正则表达式及转换字符来实现转成中文 Unicode转换示例 通常为10位编码, 通过digit参数传入 pri ...
- ASCII字符集。扩展ASCII字符集。Unicode字符集分别支持多少个字符?
ASCII字符集.扩展ASCII字符集.Unicode字符集分别支持多少个字符? 256个字符和 65536个字符
随机推荐
- Centos7 中 Node.js安装简单方法
最近,我一直对学习Node.js比较感兴趣.下面是小编给大家带来的Centos7 中 Node.js安装简单方法,在此记录一下,方便自己也方便大家,一起看看吧! 安装node.js 登陆Centos ...
- 使用block的好处
1 使用block 可以轻松地绑定各处代码块,使用delete 结构是分散的,不利于变量之间传值,不像block可以随意地获取变量值. 2.使用block可以方便执行异步代码,作为异步处理回调. In ...
- input标签file文件上传图片本地预览
<input type="file" name="img-up" id="img-up" value="" /&g ...
- react native 淘宝镜像
终端命令 open 打开 .npmrc 插入一行代码 registry=https://registry.npm.taobao.org
- mysql进程文件
- 通俗理解RxJS(一)
自学 Rx 快有一个周了, 它非常适合处理复杂的异步场景.结合自己所学,决定写系列教程. 我认为, Rx 中强大的地方在于两处 管道思想,通过管道,我们订阅了数据的来源,并在数据源更新时响应 . 强大 ...
- Atcoder Tenka1 Programmer Contest 2019 D Three Colors
题意: 有\(n\)个石头,每个石头有权值,可以给它们染'R', 'G', 'B'三种颜色,如下定义一种染色方案为合法方案: 所有石头都染上了一种颜色 令\(R, G, B\)为染了'R', 染了'G ...
- win10如何设置自动睡眠时间(修改电源计划不好用的情况下)
https://answers.microsoft.com/en-us/windows/forum/windows_10-power/windows-10-sleeping-when-set-not- ...
- OGNL mybatis
http://www.mybatis.org/mybatis-3/zh/dynamic-sql.html 动态 SQL MyBatis 的强大特性之一便是它的动态 SQL.如果你有使用 JDBC 或其 ...
- Linux中Postfix邮件接收配置(四)
Dovecot介绍 MRA邮件取回代理也有很多如courier-imap,cyrus-imap和dovecot这三个个工具,下面重点介绍Dovecot: 1.高安全性.据 Dovecot 的作者声称, ...