Python -- Scrapy 命令行工具(command line tools)
结合scrapy 官方文档,进行学习,并整理了部分自己学习实践的内容
Scrapy是通过 scrapy 命令行工具进行控制的。 这里我们称之为 “Scrapy tool” 以用来和子命令进行区分。 对于子命令,我们称为 “command” 或者 “Scrapy commands”。
Scrapy tool 针对不同的目的提供了多个命令,每个命令支持不同的参数和选项。
默认的Scrapy项目结构
在开始对命令行工具以及子命令的探索前,让我们首先了解一下Scrapy的项目的目录结构。
虽然可以被修改,但所有的Scrapy项目默认有类似于下边的文件结构:
scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
spider1.py
spider2.py
...
scrapy.cfg 存放的目录被认为是 项目的根目录 。该文件中包含python模块名的字段定义了项目的设置。例如:
[settings]
default = myproject.settings
使用 scrapy 工具
您可以以无参数的方式启动Scrapy工具。该命令将会给出一些使用帮助以及可用的命令:
Scrapy X.Y - no active project Usage:
scrapy <command> [options] [args] Available commands:
crawl Run a spider
fetch Fetch a URL using the Scrapy downloader
[...]
如果您在Scrapy项目中运行,当前激活的项目将会显示在输出的第一行。上面的输出就是响应的例子。如果您在一个项目中运行命令将会得到类似的输出:
Scrapy X.Y - project: myproject Usage:
scrapy <command> [options] [args] [...]
创建项目
一般来说,使用 scrapy 工具的第一件事就是创建您的Scrapy项目:
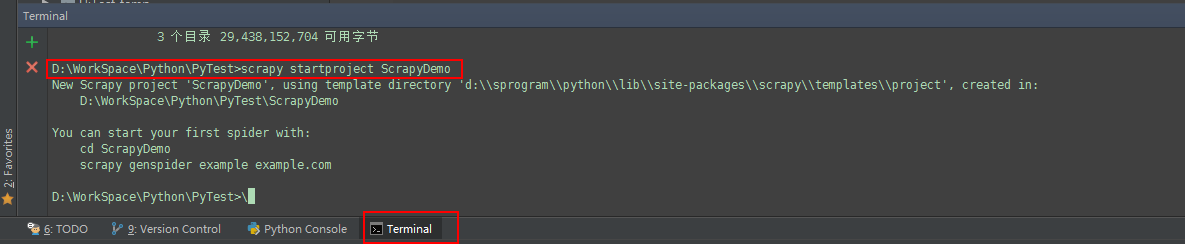
scrapy startproject ScrapyTest

该命令将会在 ScrapyTest目录中创建一个Scrapy项目。
接下来,进入到项目目录中:
cd ScrapyTest
这时候您就可以使用 scrapy 命令来管理和控制您的项目了。
简单加一句,在pycharm 中的终端同样支持windows命令操作。
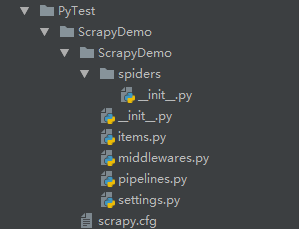
创建后的项目结构如下,此时还没有创建spider
控制项目
您可以在您的项目中使用 scrapy 工具来对其进行控制和管理。
比如,通过命令行或是终端在项目下创建一个新的spider:
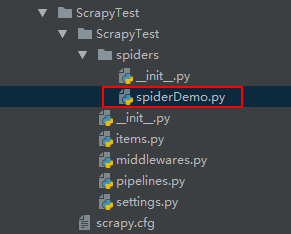
scrapy genspider spiderDemo domainTest

创建后的目录结构如下
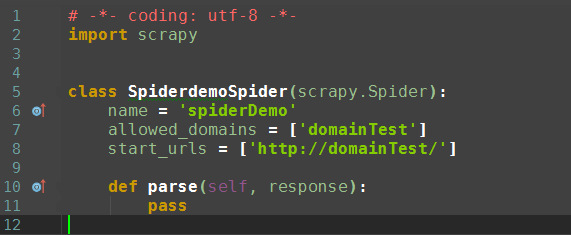
自动生成的代码如下
有些Scrapy命令(比如 crawl)要求必须在Scrapy项目中运行。 您可以通过下边的 commands reference 来了解哪些命令需要在项目中运行,哪些不用。
另外要注意,有些命令在项目里运行时的效果有些许区别。 以fetch命令为例,如果被爬取的url与某个特定spider相关联, 则该命令将会使用spider的动作(spider-overridden behaviours)。 (比如spider指定的 user_agent)。 该表现是有意而为之的。一般来说, fetch 命令就是用来测试检查spider是如何下载页面。
可用的工具命令(tool commands)
该章节提供了可用的内置命令的列表。每个命令都提供了描述以及一些使用例子。您总是可以通过运行命令来获取关于每个命令的详细内容:
scrapy
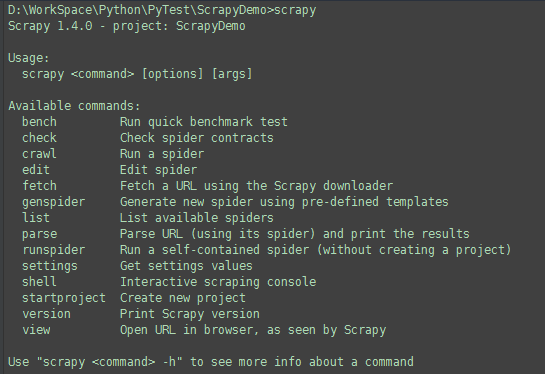
scrapy <command> -h scrapy genspider -h
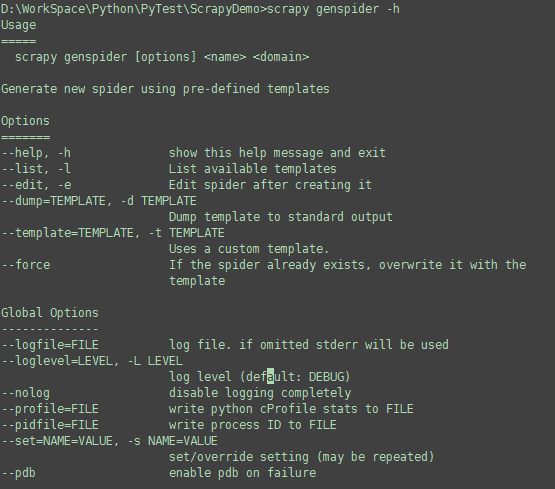
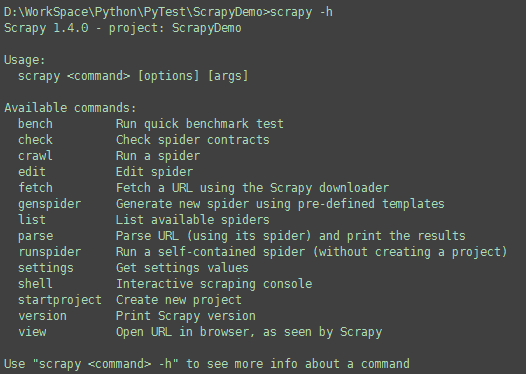
您也可以这样查看可用的命令:
scrapy -h
Scrapy提供了两种类型的命令。一种必须在Scrapy项目中运行(针对项目(Project-specific)的命令),另外一种则不需要(全局命令)。全局命令在项目中运行时的表现可能会与在非项目中运行有些许差别(因为可能会使用项目的设定)。
全局命令:
startprojectsettingsrunspidershellfetchviewversion
项目(Project-only)命令:
crawlchecklisteditparsegenspiderdeploybench
startproject
- 语法:
scrapy startproject <project_name> - 是否需要项目: no
在 project_name 文件夹下创建一个名为 project_name 的Scrapy项目。
例子:
scrapy startproject myproject
genspider
- 语法:
scrapy genspider [-t template] <name> <domain> - 是否需要项目: yes
在当前项目中创建spider。
这仅仅是创建spider的一种快捷方法。该方法可以使用提前定义好的模板来生成spider。您也可以自己创建spider的源码文件。
例子:
#使用命令 参数 -l 查看 spider 模板 scrapy genspider -l #输出结果为模板名称
Available templates:
basic
crawl
csvfeed
xmlfeed
查看spider模板源代码
#使用 命令加上参数 ‘-d’,以及模板名称 scrapy genspider -d crawl #输出模板信息 # -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class $classname(CrawlSpider):
name = '$name'
allowed_domains = ['$domain']
start_urls = ['http://$domain/'] rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
) def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
#通过命令加参数 -t 模板名称 spiderName [domainName] 创建 spider scrapy genspider -t basic example example.com
Created spider 'example' using template 'basic' in module:
mybot.spiders.example
crawl
- 语法:
scrapy crawl <spider> - 是否需要项目: yes
使用spider进行爬取。
例子:
$ scrapy crawl myspider
[ ... myspider starts crawling ... ] 如下图:执行
scrapy crawl TieBaSpider -o items.json 即可将 爬取的数据存放到items.json文件中
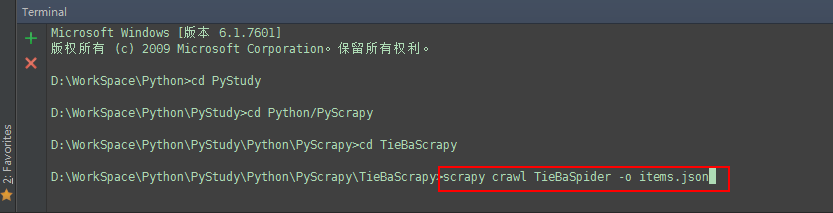
scrapy crawl TieBaSpider -o filename.fileformat(文件格式)
check
- 语法:
scrapy check [-l] <spider> - 是否需要项目: yes
运行contract检查。
例子:
$ scrapy check -l
first_spider
* parse
* parse_item
second_spider
* parse
* parse_item $ scrapy check
[FAILED] first_spider:parse_item
>>> 'RetailPricex' field is missing [FAILED] first_spider:parse
>>> Returned 92 requests, expected 0..4
list
- 语法:
scrapy list - 是否需要项目: yes
列出当前项目中所有可用的spider。每行输出一个spider。
使用例子:
$ scrapy list
spider1
spider2
edit
- 语法:
scrapy edit <spider> - 是否需要项目: yes
使用 EDITOR 中设定的编辑器编辑给定的spider
该命令仅仅是提供一个快捷方式。开发者可以自由选择其他工具或者IDE来编写调试spider。
例子:
$ scrapy edit spider1
fetch
- 语法:
scrapy fetch <url> - 是否需要项目: no
使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出。
该命令以spider下载页面的方式获取页面。例如,如果spider有 USER_AGENT 属性修改了 User Agent,该命令将会使用该属性。
因此,您可以使用该命令来查看spider如何获取某个特定页面。
该命令如果非项目中运行则会使用默认Scrapy downloader设定。
例子:
$ scrapy fetch --nolog http://www.example.com/some/page.html
[ ... html content here ... ] $ scrapy fetch --nolog --headers http://www.example.com/
{'Accept-Ranges': ['bytes'],
'Age': ['1263 '],
'Connection': ['close '],
'Content-Length': ['596'],
'Content-Type': ['text/html; charset=UTF-8'],
'Date': ['Wed, 18 Aug 2010 23:59:46 GMT'],
'Etag': ['"573c1-254-48c9c87349680"'],
'Last-Modified': ['Fri, 30 Jul 2010 15:30:18 GMT'],
'Server': ['Apache/2.2.3 (CentOS)']}
view
- 语法:
scrapy view <url> - 是否需要项目: no
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现。 有些时候spider获取到的页面和普通用户看到的并不相同。 因此该命令可以用来检查spider所获取到的页面,并确认这是您所期望的。
例子:
$ scrapy view http://www.example.com/some/page.html
[ ... browser starts ... ]
shell
- 语法:
scrapy shell [url] - 是否需要项目: no
以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell。 查看 Scrapy终端(Scrapy shell) 获取更多信息。
例子:
$ scrapy shell http://www.example.com/some/page.html
[ ... scrapy shell starts ... ]
parse
- 语法:
scrapy parse <url> [options] - 是否需要项目: yes
获取给定的URL并使用相应的spider分析处理。如果您提供 --callback 选项,则使用spider的该方法处理,否则使用 parse 。
支持的选项:
--spider=SPIDER: 跳过自动检测spider并强制使用特定的spider--a NAME=VALUE: 设置spider的参数(可能被重复)--callbackor-c: spider中用于解析返回(response)的回调函数--pipelines: 在pipeline中处理item--rulesor-r: 使用CrawlSpider规则来发现用来解析返回(response)的回调函数--noitems: 不显示爬取到的item--nolinks: 不显示提取到的链接--nocolour: 避免使用pygments对输出着色--depthor-d: 指定跟进链接请求的层次数(默认: 1)--verboseor-v: 显示每个请求的详细信息
例子:
$ scrapy parse http://www.example.com/ -c parse_item
[ ... scrapy log lines crawling example.com spider ... ] >>> STATUS DEPTH LEVEL 1 <<<
# Scraped Items ------------------------------------------------------------
[{'name': u'Example item',
'category': u'Furniture',
'length': u'12 cm'}] # Requests -----------------------------------------------------------------
[]
settings
- 语法:
scrapy settings [options] - 是否需要项目: no
获取Scrapy的设定
在项目中运行时,该命令将会输出项目的设定值,否则输出Scrapy默认设定。
例子:
$ scrapy settings --get BOT_NAME
scrapybot
$ scrapy settings --get DOWNLOAD_DELAY
0
runspider
- 语法:
scrapy runspider <spider_file.py> - 是否需要项目: no
在未创建项目的情况下,运行一个编写在Python文件中的spider。
例子:
$ scrapy runspider myspider.py
[ ... spider starts crawling ... ]
version
- 语法:
scrapy version [-v] - 是否需要项目: no
输出Scrapy版本。配合 -v 运行时,该命令同时输出Python, Twisted以及平台的信息,方便bug提交。
deploy
0.11 新版功能.
- 语法:
scrapy deploy [ <target:project> | -l <target> | -L ] - 是否需要项目: yes
将项目部署到Scrapyd服务。查看 部署您的项目 。
自定义项目命令
您也可以通过 COMMANDS_MODULE 来添加您自己的项目命令。您可以以 scrapy/commands 中Scrapy commands为例来了解如何实现您的命令。
COMMANDS_MODULE
Default: '' (empty string)
用于查找添加自定义Scrapy命令的模块。
例子:
COMMANDS_MODULE = 'mybot.commands'
Python -- Scrapy 命令行工具(command line tools)的更多相关文章
- MAC 命令行工具(Command Line Tools)安装
不过升级后安装命令行工具(Command Line Tools)时发现官网没有clt的下载安装包了,原来改了,使用命令在线安装. 打开终端,输入命令:xcode-select --install 选择 ...
- Xcode 命令行工具 Command Line Tools
xcode命令行工具包是一个小型独立包,可供下载独立于Xcode的和允许您执行命令行开发OS X. 在OS X10.9,就以及没有clt的下载安装包了,需要使用命令在线安装. xcode-select ...
- MAC OS 如何安装命令行工具:Command Line Tools
打开终端输入:xcode-select --install 回车 安装好了测试结果:gcc -v 显示如下: xcode-select: note: install requested for com ...
- Scrapy命令行工具简介
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0, 在最初使用Scrapy时,使用编辑器或IDE手动编写模块来创建爬虫(Spide ...
- 二、Scrapy命令行工具
本文转载自以下链接:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/commands.html Scrapy是通过 scrapy 命令行工具 ...
- 使用Scrapy命令行工具【导出JSON文件】时编码设置
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0, 使用scrapy命令行工具建立了爬虫项目(startproject),并使用s ...
- python制作命令行工具——fire
python制作命令行工具--fire 前言 本篇教程的目的是希望大家可以通读完此篇之后,可以使用python制作一款符合自己需求的linux工具. 本教程使用的是google开源的python第三方 ...
- OS X 10.9 Mavericks下如何安装Command Line Tools(命令行工具)
OS X 10.9 Mavericks下如何安装Command Line Tools(命令行工具) 今天OS X 10.9 Mavericks正式发布,免费更新,立即去更新看看效果. 不过升级后安装命 ...
- 如何在OS X 10.9 Mavericks下安装Command Line Tools(命令行工具)
随着OS X 10.9 于 2013年6月10日在旧金山WWDC(world wide developer conference)上发布.是首个不使用猫科动物命名的系统,而转用加利福尼亚的产物. 该系 ...
随机推荐
- 2.TypeScript 基础入门(二)
变量类型的那些事 1.基本注解 类型注解使用:TypeAnnotation 语法.类型声明空间中可用的任何内容都可以用作类型注解. const num: number = 123; function ...
- VS2010/MFC编程入门之五十二(Ribbon界面开发:创建Ribbon样式的应用程序框架)
上一节中鸡啄米讲了GDI对象之画刷CBrush,至此图形图像的入门知识就讲完了.从本节开始鸡啄米将为大家带来Ribbon界面开发的有关内容.本文先来说说如何创建Ribbon样式的应用程序框架. Rib ...
- Codeforces Round #440 (Div. 2, based on Technocup 2018 Elimination Round 2) C. Maximum splitting
地址: 题目: C. Maximum splitting time limit per test 2 seconds memory limit per test 256 megabytes input ...
- Object-C-block
块是对c语言的一种扩展语法 块看起来像函数,不同的是,快可以直接写在函数内部 块能够作为参数传递给函数或者方法 void sayHello(){NSLog(@"hello!");} ...
- Masonry 适配label多行
设置属性后,然后根据文本自动多行显示,无需设置标签高度约束 1 属性preferredMaxLayoutWidth,如:label.preferredMaxLayoutWidth = (WidthSc ...
- Python: 类中为什么要定义__init__()方法
学习并转自:https://blog.csdn.net/geerniya/article/details/77487941 1. 不用init()方法定义类 定义一个矩形的类,目的是求周长和面积. c ...
- bzoj1651 / P2859 [USACO06FEB]摊位预订Stall Reservations
P2859 [USACO06FEB]摊位预订Stall Reservations 维护一个按右端点从小到大的优先队列 蓝后把数据按左端点从小到大排序,顺序枚举. 每次把比右端点比枚举线段左端点小的数据 ...
- YAML配置文件
最近,研究jeeweb这个框架,发现新版本中的配置文件都是用的.yml为后缀的文件,打开一看,和以前的xml和properties语法有很大区别,因此仔细研究一下. 简介: YAML是(YAML Ai ...
- JavaScript中变量提升------Hoisting
原谅链接:http://www.cnblogs.com/damonlan/archive/2012/07/01/2553425.html 因为这个问题很是经典,而且容易出错,所以在介绍一次.哈哈.莫怪 ...
- # 20145106 《Java程序设计》第6周学习总结
教材学习内容总结 来源和目的都不知道的情况下还是可以撰写程序的,有这类需求的时候,可以设计一个通用的dump()方法.dump方法接受inputstream与outputstream实例,分别代表读取 ...