[NN] 对于BackPropagation(BP, 误差反向传播)的一些理解
本文大量参照 David E. Rumelhart, Geoffrey E. Hinton and Ronald J. Williams, Learning representation by back-propagating errors, Nature, 323(9): 533-536, 1986.
在现代神经网络中, 使用最多的算法当是反向传播(BP). 虽然BP有着收敛慢, 容易陷入局部最小等缺陷, 但其易用性, 准确度却是其他算法无可比拟的.
在本文中, $w_{ji}$为连接前一层$unit_{i}$和后一层$unit_{j}$的权值.
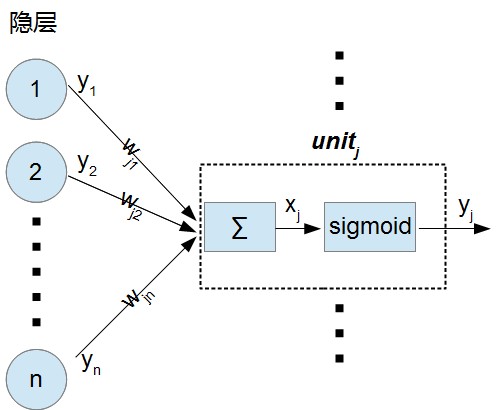
在MLP中, 对于输出层神经元$unit_{j}$, 它的输入$x_{j}$按下式进行计算(忽略偏置):
$x_{j} = \sum_{i} y_{i} w_{ji}$
可以看到它的输入等于前一层所有神经元的输出$y_{i}$和对应连接的加权和, 如上图
而$unit_{j}$的输出按下式计算:
$y_{j} = \frac{1}{1+e^{-x_{j}}}$. 这就是一个非线性变换sigmoid,
对于有监督训练, 期望输出$d$和实际输出$y$现在都是已知的, 定义误差为:
$E=\frac{1}{2}\sum_{c} \sum_{j}(y_{j,c}-d_{j,c})^2$
其中的$c$是输入-输出样本对的标号, $j$是输出层神经元的标号.
为求出$\partial E/\partial w_{ji}$,
我们先求$\partial E/\partial y_{j}$(之后就知道为何如此):
$\partial E/\partial y_{j} = y_{j} - d_{j}$, 此为误差$E$对神经元$unit_{j}$输出的偏导.
由链式法则:
$\partial E/\partial x_{j} = \partial E/\partial y_{j} * d y_{j}/d x_{j}$, 及上面的输入输出的关系式
$d y_{j}/d x_{j} = (\frac{1}{1+e^{-x_{j}}})' = \frac{e^{-x_{j}}}{(1+e^{-x_{j}})^{2}} = y_{j} * (1-y_{j})$
我们可以求出误差$E$对$unit_{j}$的输入$x_{j}$的偏导:
$\partial E/\partial x_{j} = \partial E/\partial y_{j} * y_{j} * (1-y_{j})$
至此, 我们得到了误差$E$对于$unit_{j}$输入$x_{j}$的偏导, 但网络训练的是权值(偏置), 所以我们必须知道$E$对于$w_{ji}$的偏导表达式.
同样由链式法则:
$\partial E/\partial w_{ji} = \partial E/\partial x_{j} * \partial x_{j}/\partial w_{ji}$, 及本层输入和权值的关系式:
$x_{j} = \sum_{i} y_{i} w_{ji}$, 可得 $\partial x_{j}/\partial w_{ji} = y_{i}$, 即:
$\partial E/\partial w_{ji} = \partial E/\partial x_{j} * y_{i}$,
其中$y_{i}$为前一层神经元$unit_{i}$的输出, $y_{j}$为后一层神经元$unit_{j}$的输出.
为了处理中间层, 我们同样是按照链式法则, 对于第i个神经元, 我们可以求得误差$E$对其输出$y_{i}$的梯度(注意这里是$y_{i}$, 不是$y_{j}$):
$\partial E/\partial y_{i} = \partial E/\partial x_{j} * \partial x_{j}/\partial y_{i} = \partial E/\partial x_{j} * w_{ji}$,
考虑到第i个神经元的所有连接, 可以得到:
$\partial E/\partial y_{i} = \sum_{j}\partial E/\partial x_{j} * w_{ji}$ (1)
这里的$\partial E/\partial x_{j}$为误差对于后一层的神经元$unit_{j}$输入$x_{j}$的偏导.
我们梳理一下:
对于连接神经元$i$和神经元$j$的权值$w_{ji}$, 主要有3个偏导分子, 输入$x_{j}$, 输出$y_{j}$和权值$ w_{ji}$, 他们的关系如下:
$\partial E/\partial x_{j} = \partial E/\partial y_{j} * y_{j} * (1-y_{j})$ (2)[基于$y_{j}$和$x_{j}$的非线性转换关系式];
$\partial E/\partial w_{ji} = \partial E/\partial x_{j} * y_{i}$ (3)[基于$x_{j}$和$y_{i}$的加权求和公式].
为求得上面的式(3), 我们需要求得$\partial E/\partial x_{j}$, 而为求得$\partial E/\partial x_{j}$, 需要求得$\partial E/\partial y_{j}$.
对于输出层(最后一层), $\partial E/\partial y_{j}=y_{j} - d_{j}$;
对于中间层, $\partial E/\partial y_{i}$按式(1)进行计算, 而式(1)中的$\partial E/\partial x_{j}$是由$\partial E/\partial y_{j}=y_{j} - d_{j}$算出来的. 当我们算出中间层的$\partial E/\partial y_{i}$之后, 把式(2)中的$y_{j}$全部替换成$y_{i}$就可以计算出$\partial E/\partial x_{i}$从而计算出式(3), 注意此时的式(3)中的$y_{i}$应该变为第i个神经元的前一层的对应神经元.
如此迭代, 我们就可以更新所有的权值啦.
权值调整的公式如下:
$\delta w = -\epsilon \partial E/\partial w$
总结:
BP的精髓: 如何通过链式法则求出$\partial E/\partial w_{ji}$
求法:
注意, 以下推导, 统一使用$i$ 作为当前层前一层的神经元下标, $j$ 作为当前层的神经元下标, $k$ 作为后一层神经元下标.
对于最后一层:
$\partial E/\partial w_{ji} = \partial E/\partial x_{j} * \partial x_{j}/\partial w_{ji}$ (1)
其中,
$\partial E/\partial x_{j} = \partial E/\partial y_{j} * \partial y_{j}/\partial x_{j}$ (2)
$\partial x_{j}/\partial w_{ji} = y_{i}$ (3, 已求出, 谢谢背锅侠指正)
式(2)中,
$ \partial E/\partial y_{j} = y_{j} - d_{j}$ (已求出)
$ \partial y_{j}/\partial x_{j} = y_{j} * (1 - y_{j})$ (已求出)
从而计算出误差对[最后一层到倒数第二层的权值]的梯度.
$\partial E/\partial w_{ji} = ( y_{j} - d_{j}) * y_{j} * (1 - y_{j}) * y_{i}$
对于倒数第二层:
唯一变化的只有 $ \partial E/\partial y_{j} $ 的求法. 同样适用链式法则展开:
$ \partial E/\partial y_{j} = \partial E/\partial y_{k} * \partial y_{k}/\partial y_{j}$, 其中 $y_{k}$ 为后一层(最后一层)的第$k$个神经元输出.
由于$\partial E/\partial y_{k} = y_{k} - d_{k}$(非固定, 每层表达式取前一层计算结果),
而$\partial y_{k}/\partial y_{j} = \partial y_{k}/\partial x_{k} * \partial x_{k}/\partial y_{j}$,
其中 $\partial y_{k}/\partial x_{k} = y_{k} * (1 - y_{k})$ (固定的, 每层表达式都一样)
$\partial x_{k}/\partial y_{j} = w_{kj}$ (固定的, 每层表达式都一样)
故$\partial y_{k}/\partial y_{j} = y_{k} * (1 - y_{k}) * w_{kj}$ (固定的, 每层表达式都一样)
从而有 $ \partial E/\partial y_{j} = \partial E/\partial y_{k} * y_{k} * (1 - y_{k}) * w_{kj}$ (非固定, 用于下一层的误差梯度计算)
最终: $\partial E/\partial w_{ji} = \partial E/\partial y_{j} * y_{j} * (1 - y_{j}) * y_{i}$
倒数第三层
可将倒数第二层求出的的$\partial E/\partial y_{j}$作为本层的$\partial E/\partial y_{k}$, 可计算出 $\partial E/\partial y_{j}$, 从而计算出 $\partial E/\partial w_{ji}$.
[NN] 对于BackPropagation(BP, 误差反向传播)的一些理解的更多相关文章
- 神经网络训练中的Tricks之高效BP(反向传播算法)
神经网络训练中的Tricks之高效BP(反向传播算法) 神经网络训练中的Tricks之高效BP(反向传播算法) zouxy09@qq.com http://blog.csdn.net/zouxy09 ...
- 手写BP(反向传播)算法
BP算法为深度学习中参数更新的重要角色,一般基于loss对参数的偏导进行更新. 一些根据均方误差,每层默认激活函数sigmoid(不同激活函数,则更新公式不一样) 假设网络如图所示: 则更新公式为: ...
- cs231n(三) 误差反向传播
摘要 本节将对反向传播进行直观的理解.反向传播是利用链式法则递归计算表达式的梯度的方法.理解反向传播过程及其精妙之处,对于理解.实现.设计和调试神经网络非常关键.反向求导的核心问题是:给定函数 $f( ...
- BP神经网络反向传播之计算过程分解(详细版)
摘要:本文先从梯度下降法的理论推导开始,说明梯度下降法为什么能够求得函数的局部极小值.通过两个小例子,说明梯度下降法求解极限值实现过程.在通过分解BP神经网络,详细说明梯度下降法在神经网络的运算过程, ...
- 机器学习 —— 基础整理(七)前馈神经网络的BP反向传播算法步骤整理
这里把按 [1] 推导的BP算法(Backpropagation)步骤整理一下.突然想整理这个的原因是知乎上看到了一个帅呆了的求矩阵微分的方法(也就是 [2]),不得不感叹作者的功力.[1] 中直接使 ...
- 【机器学习】反向传播算法 BP
知识回顾 1:首先引入一些便于稍后讨论的新标记方法: 假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络的层数,S表示每层输入的神经元的个数,SL代表最后一层中处理的单元 ...
- 一文弄懂神经网络中的反向传播法——BackPropagation【转】
本文转载自:https://www.cnblogs.com/charlotte77/p/5629865.html 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学习 ...
- 神经网络中的反向传播法--bp【转载】
from: 作者:Charlotte77 出处:http://www.cnblogs.com/charlotte77/ 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学 ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
随机推荐
- gradle 编译 No such property: sonatypeUsername错误解决
No such property: sonatypeUsername for class: org.gradle.api.publication.maven.internal.ant.DefaultG ...
- Linux文件与目录管理(三)
一.Linux文件内容查看 1.cat:由第一行开始显示文件内容 2.tac:从最后一行开始显示,可以看出tac是cat倒着写 3.nl:显示的时候,顺便输出行号 4.more:一页一页的显示文件内容 ...
- Access-Control-Allow-Origin实现跨域访问 跨域
总结:跨域的get,post请求 后台可以设置 Access-Control-*相关的参数,让浏览器支持. // 指定允许其他域名访问 header('Access-Control-Allow-Ori ...
- 通过ReRes让chrome拥有路径映射的autoResponse功能。
前端开发过程中,经常会有需要对远程环境调试的需求.比如,修改线上bug,开发环境不在本地等等.我们需要把远程css文件或者js映射到本地的文件上,通过修改本地文件进行调试和开发.通常我们可以通过以下方 ...
- HDU 2891
DESCRIPTION: 大意是说 先给你n个 同学的 上课时间.一周的第几天,开始和结束的时间点.然后对应q个出去玩的时间.要你给出谁不能出去.如果都能出去就输出none. 开始做的时候觉得每个同学 ...
- TADOTABLE 永久字段的顺序 和 AppendRecord
AppendRecord 方法,添加记录的字段到数据库里时,是按照IDE里永久字段的顺序,不是数据库表里的字段顺序. 自动编号 字段,以nil为值. 日期时间 字段,直接now 写法
- 2.4 C++成员选择符
参考:http://www.weixueyuan.net/view/6336.html 总结: 访问可以通过成员选择符“.”或指针操作符“->”来完成. 通过上一节的学习我们看到:通过对象可以访 ...
- 1.5 C++ new和delete操作符
参考:http://www.weixueyuan.net/view/6331.html 在C语言中,动态分配和释放内存的函数是malloc.calloc和free,而在C++语言中,new.new[] ...
- python 元组(tuple)
面试python我想每个人都会被问一个问题,就是python中的list和tuple有什么区别? 一般情况下,我会回答,list元素可变,tuple元素不可变(书上或者其他的博客都是这么写的),一般情 ...
- http请求报头
客户请求的处理:Http请求报头 创建高效servlet的关键之一,就是要了解如何操纵超文本传输协议(HypeText TransferProtocol, HTTP). HTTP请求报头不同于前一章的 ...