Spring Batch事务处理
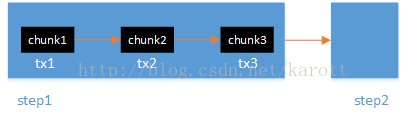
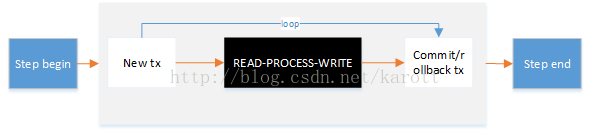
<batch:tasklet><batch:chunk /><batch:no-rollback-exception-classes><batch:include class="com.xx.batch.DefRuntimeException"/></batch:no-rollback-exception-classes></batch:tasklet><batch:tasklet><batch:transaction-attributes isolation="READ_COMMITTED" propagation="REQUIRES_NEW" timeout="300"/><batch:chunk reader="defItemReader" processor="defItemProcessor" writer="defItemWriter" commit-interval="10"/></batch:tasklet><batch:job id="jobId" restartable="true"></batch:job><batch:chunk skip-limit="20"><batch:skippable-exception-classes><batch:include class="com.xx.batch.ExceptionClass" /></batch:skippable-exception-classes></batch:chunk><batch:chunk skip-policy="defSkipPolicy"></batch:chunk><batch:chunk retry-limit="20"><batch:retryable-exception-classes><batch:include class="com.xx.batch.ExceptionClass" /></batch:retryable-exception-classes></batch:chunk><batch:chunk retry-policy="defRetryPolicy"></batch:chunk>
Spring Batch事务处理的更多相关文章
- Spring Batch 中文参考文档 V3.0.6 - 1 Spring Batch介绍
1 Spring Batch介绍 企业领域中许多应用系统需要采用批处理的方式在特定环境中运行业务操作任务.这种业务作业包括自动化,大量信息的复杂操作,他们不需要人工干预,并能高效运行.这些典型作业包括 ...
- Spring batch学习 (1)
Spring Batch 批处理框架 埃森哲和Spring Source研发 主要解决批处理数据的问题,包含并行处理,事务处理机制等.具有健壮性 可扩展,和自带的监控功能,并且支持断点和重发.让程序员 ...
- spring batch(二):核心部分(1):配置Spring batch
spring batch(二):核心部分(1):配置Spring batch 博客分类: Spring 经验 java chapter 3.Batch configuration 1.spring ...
- Spring Batch基本概念
Spring batch主要有以下部分组成: JobRepository 用来注册job的容器 JobLauncher 用来启动Job的接口 Job ...
- Spring Batch在大型企业中的最佳实践
在大型企业中,由于业务复杂.数据量大.数据格式不同.数据交互格式繁杂,并非所有的操作都能通过交互界面进行处理.而有一些操作需要定期读取大批量的数据,然后进行一系列的后续处理.这样的过程就是" ...
- spring batch资料收集
spring batch官网 Spring Batch在大型企业中的最佳实践 一篇文章全面解析大数据批处理框架Spring Batch Spring Batch系列总括
- Spring Batch学习笔记三:JobRepository
此系列博客皆为学习Spring Batch时的一些笔记: Spring Batch Job在运行时有很多元数据,这些元数据一般会被保存在内存或者数据库中,由于Spring Batch在默认配置是使用H ...
- Spring Batch学习笔记二
此系列博客皆为学习Spring Batch时的一些笔记: Spring Batch的架构 一个Batch Job是指一系列有序的Step的集合,它们作为预定义流程的一部分而被执行: Step代表一个自 ...
- 初探Spring Batch
此系列博客皆为学习Spring Batch时的一些笔记: 为什么我们需要批处理? 我们不会总是想要立即得到需要的信息,批处理允许我们在请求处理之前就一个既定的流程开始搜集信息:比如说一个银行对账单,我 ...
随机推荐
- linux之间文件传输(之scp)
linux的scp命令 linux 的 scp 命令 可以 在 linux 之间复制 文件 和 目录: ==================scp 命令==================scp 可以 ...
- 基于matplotlib的数据可视化 - 热图imshow
热图: Display an image on the axes. 可以用来比较两个矩阵的相似程度 mp.imshow(z, cmap=颜色映射,origin=垂直轴向) imshow( X, cma ...
- MongoDB 学习笔记(9)--- Limit与Skip方法
MongoDB Limit() 方法 如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的 ...
- Oracle 12C -- Identity Columns(标识列)
Identity Columns很适合数据库中需要"surrogate keys"的场景.依赖sequence产生器,每行的标识列会被赋予一个自增或自减的值.缺省,标识列在创建的时 ...
- Android水波纹特效的简单实现
我的开源页面指示器框架 MagicIndicator,各位一定不要错过哦. 水波纹特效,想必大家或多或少见过,在我的印象中,大致有如下几种: 支付宝 "咻咻咻" 式 流量球 &qu ...
- 豆瓣上9分以上的IT书籍-编程语言篇
我当要学习某些技术时,第一时间就是去找相关的书籍.而豆瓣读书是我主要的参考依据,主要是它的评分基本比较靠谱,对于技术书籍,一般来说评分在8分以上就是不错的书籍了,而达到9分就可以列入"必读& ...
- 跟我学SharePoint 2013视频培训课程——排序、过滤在列表、库中的使用(10)
课程简介 第10天,SharePoint 2013排序.过滤在列表.库中的使用. 视频 SharePoint 2013 交流群 41032413
- Python 文件 read() 方法
概述 Python 文件 read() 方法用于从文件中读取指定的字符数,如果未给定或为负则读取所有. 语法 read() 方法语法如下: fileObject.read([size]) 参数 siz ...
- 【转载并整理】JAVA解析或生成xml的四种方法
参考文章 1:http://blog.csdn.net/clemontine/article/details/53011362 2:http://www.jb51.net/article/98456. ...
- Android Developers:绘制9-patch图片
绘制9-patch图片工具让你使用可见即可得(WYSIWYG)编辑器轻松创建Nine Patch图像. 关于介绍Nine-path图片和它是如何工作的,请在2D Graphics的文档中查阅关于Nin ...