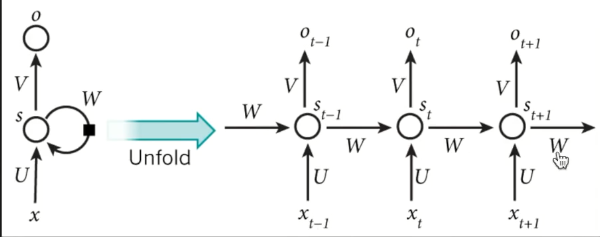
2.2RNN
RNN
RNN无法回忆起长久的记忆
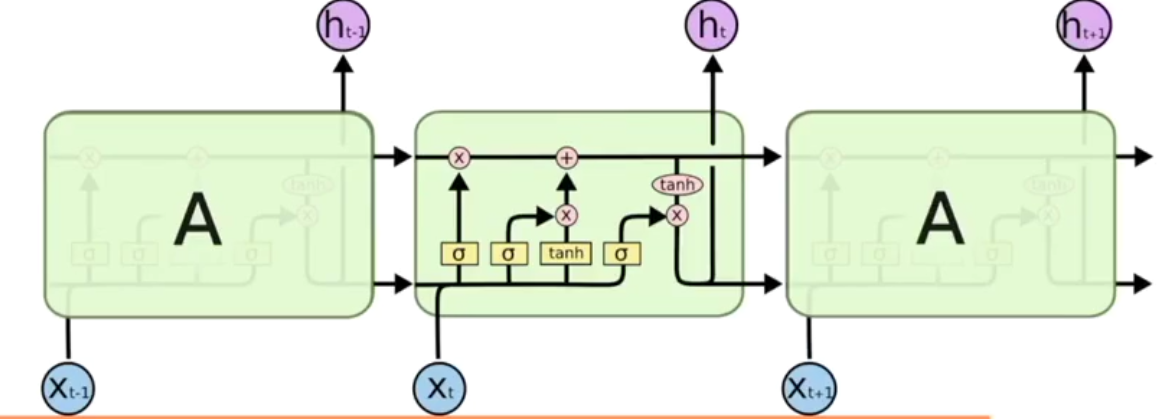
LSTM
(long short Term memory长短期记忆)解决梯度消失或弥散vanishing 和梯度爆炸explosion 0.9*n-->0 1.1*n--->无穷大
在RNN中增加了Gate
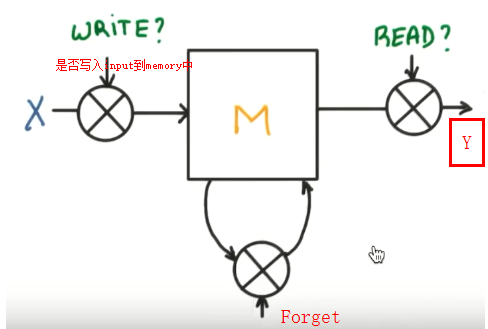
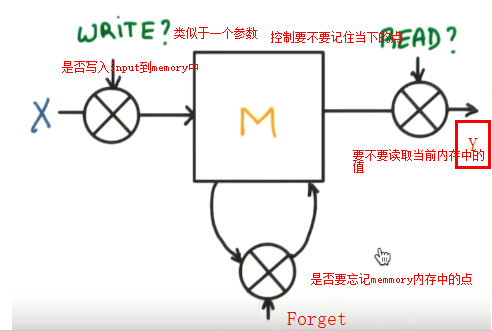
案例

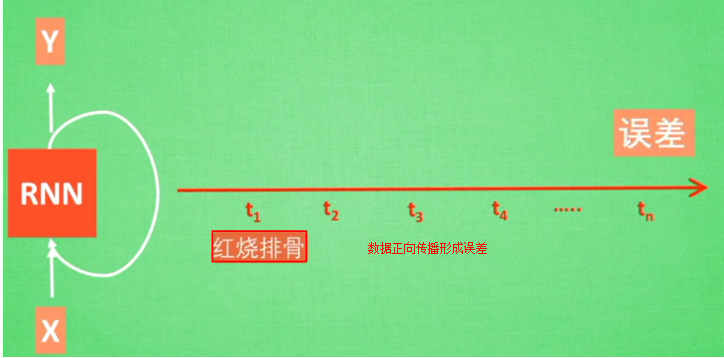


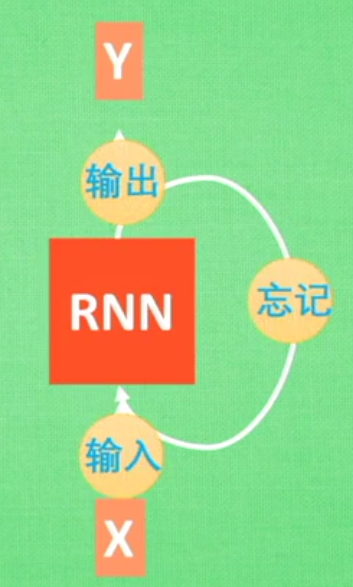
所以RNN无法回忆起长久的记忆。LSTM为了解决该问题多了三个控制器,做到了延缓记忆的功能
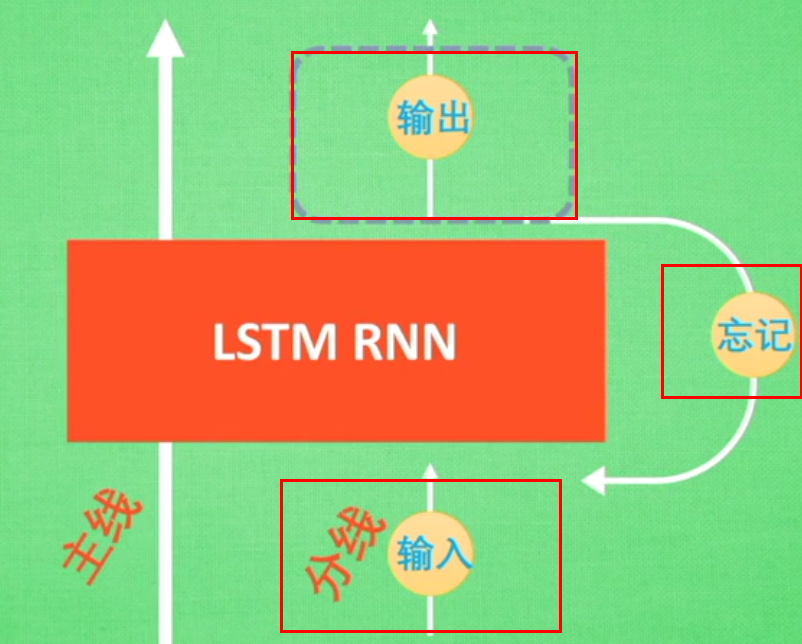
可以从主线和分线两个方面理解。LSTM可以解决延缓记忆问题
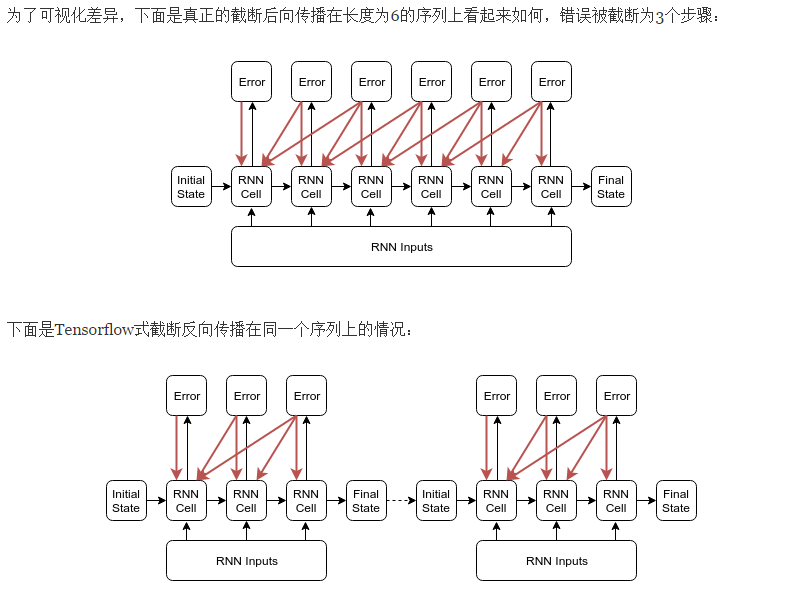
截断的反向传播BBPT
https://r2rt.com/styles-of-truncated-backpropagation.html
Tensorflow的截断反向传播(截断长度为n的子序列)的方法在定性上不同于“反向传播错误最多n步”。
LSTM模拟sin图像解决回归问题代码
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
Run this script on tensorflow r0.10. Errors appear when using lower versions.
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50
INPUT_SIZE = 1
OUTPUT_SIZE = 1
CELL_SIZE = 10
LR = 0.006 def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
# plt.show()
# returned seq, res and xs: shape (batch, step, input)
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs] class LSTMRNN(object):
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'):
self.add_input_layer()
with tf.variable_scope('LSTM_cell'):
self.add_cell()
with tf.variable_scope('out_hidden'):
self.add_output_layer()
with tf.name_scope('cost'):
self.compute_cost()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost) def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D') # (batch*n_step, in_size)
# Ws (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# bs (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# l_in_y = (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# reshape l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D') def add_cell(self):
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False) def add_output_layer(self):
# shape = (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# shape = (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost) @staticmethod
def ms_error(labels, logits):
return tf.square(tf.subtract(labels, logits)) def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name) def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer) if __name__ == '__main__':
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# relocate to the local dir and run this line to view it on Chrome (http://0.0.0.0:6006/):
# $ tensorboard --logdir='logs' plt.ion()
plt.show()
for i in range(200):
seq, res, xs = get_batch()
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
# create initial state
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state # use last state as the initial state for this run
} _, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict) # plotting 绘制训练sin图像的过程
plt.plot(xs[0, :], res[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.3) #每隔3秒运行一次 if i % 20 == 0:
print('cost: ', round(cost, 4))
result = sess.run(merged, feed_dict)
writer.add_summary(result, i)
程序运行结果
下面的图像是拟合正弦曲线的过程
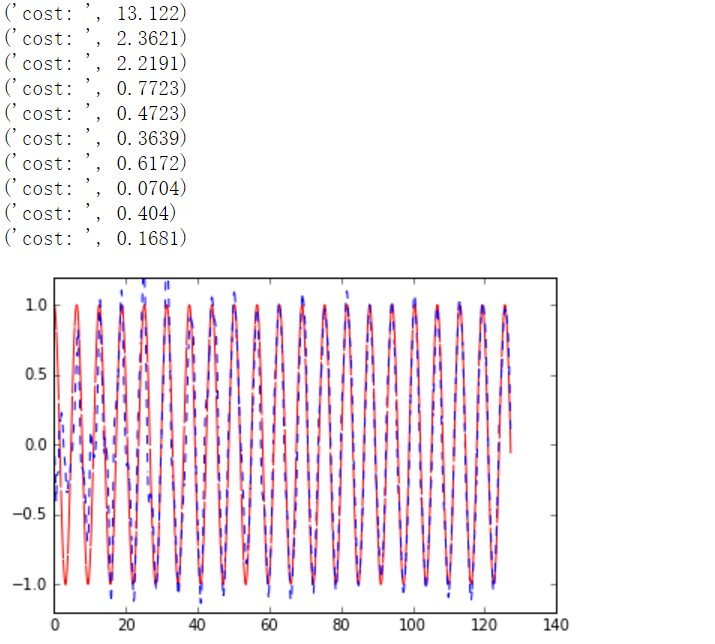
2.2RNN的更多相关文章
- PYTHON深度学习6.2RNN循环网络
#简单的循环网络 #-*-coding:utf-8 -*- from keras.datasets import imdbfrom keras.preprocessing import sequenc ...
- Auty自动化测试框架第五篇——框架内部的调用支持、自动化安装库与配置说明
[本文出自天外归云的博客园] 本次对Auty自动化测试框架做些收尾工作,由于在scripts文件夹中的脚本会需要调用其他包结构文件夹中的脚本,所以这里需要添加一下框架对于内部脚本间互相调用的支持,这里 ...
- python就业班-淘宝-目录.txt
卷 TOSHIBA EXT 的文件夹 PATH 列表卷序列号为 AE86-8E8DF:.│ python就业班-淘宝-目录.txt│ ├─01 网络编程│ ├─01-基本概念│ │ 01-网络通信概述 ...
- ssrf小记
SSRF(Server-Side Request Forgery, 服务端请求伪造),攻击者伪造服务端发起的请求并执行,从而获得一些数据或进行攻击 一.危害 1.对内网的端口和服务进行扫描,对主机本地 ...
随机推荐
- 教你解锁被锁住的苹果mac电脑的文件跟文件夹,同时也可删除被锁的文件跟文件夹(转)
在Mac OSX 下无法删除的文件可大概分为下列三种情形 1.档案(夹)被锁定 2.文件正在使用中 3.没有权限的档案(夹) 一.「 为什么档案会被锁定 」 1.个人自行替档案加上 2.在拷贝或是整理 ...
- 品鉴同事发来的炸金花的PHP程序代码
今天同事发来了一个炸金花的PHP程序,这个代码实现了两个人通过各自的三张牌进行权重计算,得到分数进行比较得到谁的牌大,我觉得里面还有一些问题,代码如下: <?php /** 每张牌的分值为一个2 ...
- Spring中神奇@aotuWrited
好久没有写博客了,放假就是充电学习的时候,的确一直是这样做的.来给自己一点掌声.我们还是进入今天的主题吧. 我们自己写代码一般会向下面这样干啊,因为这样简单,其余交给spring去做吧.Spring会 ...
- PHP字符串offset取值特性
在PHP的代码基础上,PHP字符串offset取值特性,可以拿来利用,给PHP应用程序带来安全风险. 在PHP中,可以像操作数组一样操作字符串,字符串中的字符可以用类似数组结构中的方括号包含对应的数字 ...
- error: pathspec 'master' did not match any file(s) known to git.
问题描述: 在远程服务器上新建裸仓库git --bare init : git clone裸仓库到本地: 本地新建并切换分支xccdev,git checkout -b xccdev: 从xccde ...
- 你必须知道的10个提高Canvas性能技巧
你还在抱怨自己写的canvas demo徘徊在10帧以下吗?你还在烦恼打开自己写的应用就听见CUP风扇转吗?你正在写一个javascript Canvas库吗?那么下面九点就是你必须知道的! 一.预渲 ...
- (原创)使用mceusb设备,将lirc移植到android笔记
首先说一下大环境和总体步骤: 下载lirc 0.8.7源码,使用ubuntu的setup.sh,配置为mceusb的驱动,同时Compile tools for X-Windows选项去掉,生成con ...
- tp3.2中怎么访问分类及子分类下面的文章
在项目开发过程中,我们可能会遇到在进入文章分类时需要遍历文章分类及文章子分类下面的文章的情况,具体解决步骤如下: 一.为便于理解,这里列出用到的表及字段 文章分类表(article_cate) 文章表 ...
- Android 屏幕适配:最全面的解决方案
转自:https://www.jianshu.com/p/ec5a1a30694b 前言 Android的屏幕适配一直以来都在折磨着我们Android开发者,本文将结合: Google的官方权威适配文 ...
- Android studio修改字体(font)大小(size)
Android Studio 默认编辑器(Editor)的方案(Scheme)是无法修改字体的, 可以Save as, 保存为新的方案(Scheme), 然后更改字体大小; 位置: File-> ...