spark内存模型
在spark里面,内存管理有两块组成,一部分是JVM的堆内内存(on-heap memory),这部分内存是通过spark dirver参数executor-memory以及spark.executor.memory来进行指定;
另外一部分是堆外内存(off-heap memory),堆外内存默认是关闭,需要通过spark.memory.offheap.enabled以及spark.memory.offheap.size来进行开启以及设置大小;堆外内存在可以实现回收迅速(GC是周期性回收),同时扩大了JVM的可控内存。

内存管理有两类,分别是分别是executor以及storage,前者是在计算的时候shuffle等操作需要占用的内存,后者则是在RDD缓存所占用的内存空间。
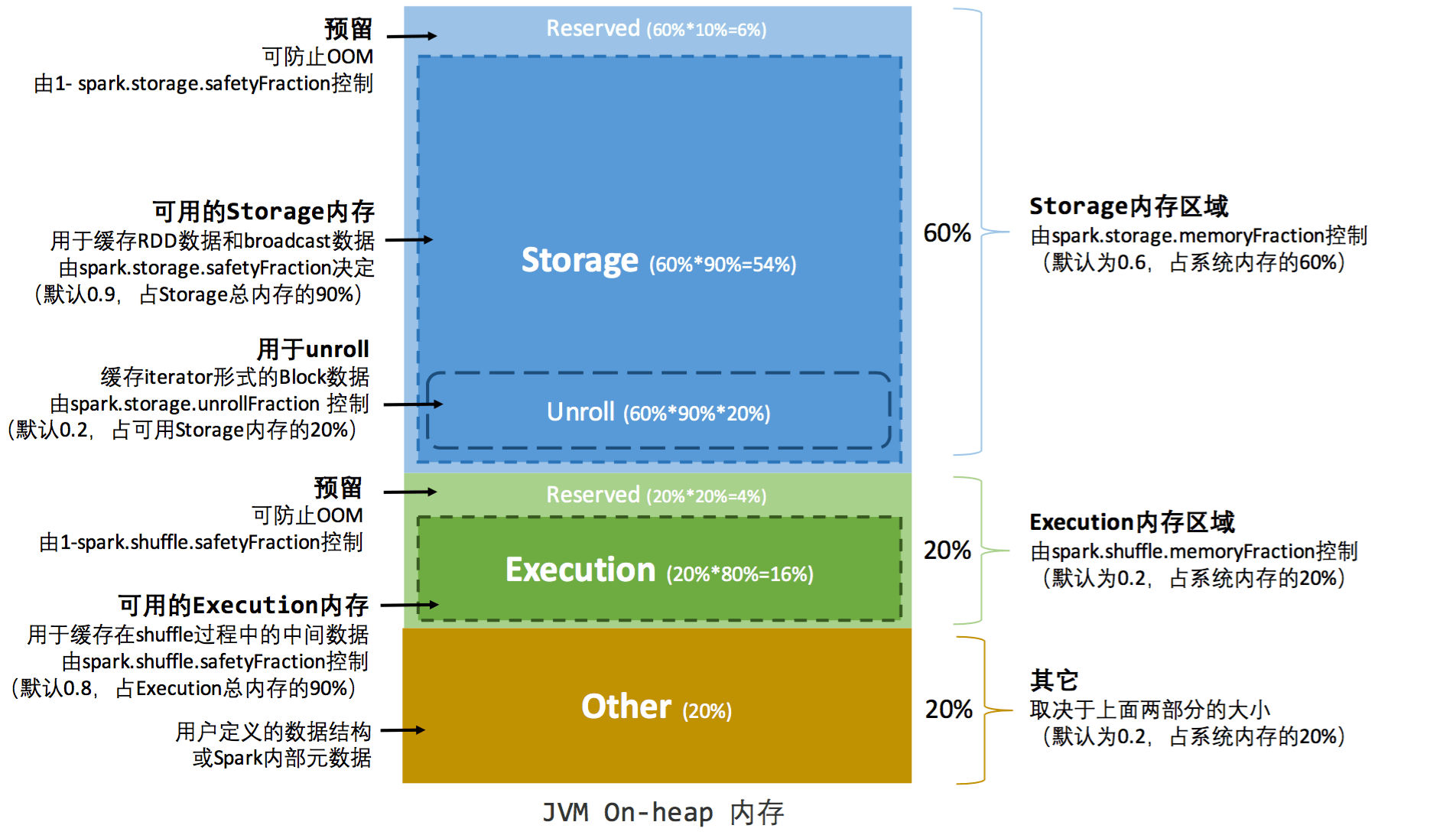
内存分配有两种类型,分别是静态内存分配,和统一内存分配,这两种内存分配类型的差别就在于storage和executor连着内存的分界线,静态内存分配是executor以及storage两者内存是静态的,根据公式计算出来;统一内存管理则不具体做划分根据各自需要;如果两者都不够用,则序列化到内存中;如果某一个方内存不够,总内存还有余富,则自动扩充内存。
对于内存分配之storage域而言,主要是用于RDD的缓存,在缓存的时候可以指定存储策略;另外当RDD被cache之后,存储空间将会有不连续的空间变为连续空间,这个过程称之为unroll;这部分内存的管理是通过 LinkedHashMap来进行空间管理;作为缓存,如果内存空间不够了,将会基于LRU策略进行淘汰(Eviction),对于淘汰的block如果配置缓存策略中包含磁盘策略,则会序列化到物理磁盘进行保存,这个过程称之为落盘(Drop)。
对于内存分配之executor域而言,每个Task将会分配到当前分配大小的[1/2N~1/N](这里强调当前是因为如果分配类型是统一内存管理将会动态变化)大小的空间,executor域的内存主要是shuffle使用,这里包括了两个场景,shuffle write和shuffle read,write占用内存策略比较复杂,如果是普通排序,主要是用的堆内内存,如果是Tungsten排序,则是堆外内存结合堆内内存(如果堆外内存不够)的方式(前提是配置了对外内存);对于shuffle read而言,主要是用的堆内内存。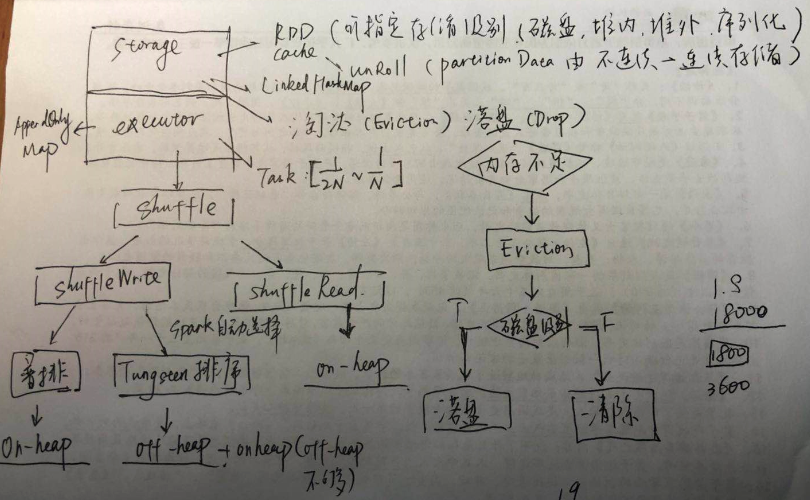
参考:
https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html
spark内存模型的更多相关文章
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型
摘抄自:https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/ind ...
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型[转]
概述 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在 ...
- 【Spark调优】内存模型与参数调优
[Spark内存模型] Spark在一个executor中的内存分为3块:storage内存.execution内存.other内存. 1. storage内存:存储broadcast,cache,p ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- Spark计算模型
[TOC] Spark计算模型 Spark程序模型 一个经典的示例模型 SparkContext中的textFile函数从HDFS读取日志文件,输出变量file var file = sc.textF ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
- Spark内存管理之钨丝计划
Spark内存管理之钨丝计划 1. 钨丝计划的产生的原因 2. 钨丝计划内幕详解 一:“钨丝计划”产生的本质原因 1, Spark作为一个一体化多元化的(大)数据处理通用平台,性能一直是其根本性的追 ...
- spark内存概述
转自:https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/spark%E5%86%85%E5%AD%98%E6%A6%82 ...
随机推荐
- 全源最短路径 - floyd算法 - O(N ^ 3)
Floyd-Warshall算法的原理是动态规划. 设Di,j,k为从i到j的只以(1..k)集合中的节点为中间节点的最短路径的长度. 若最短路径经过点k,则Di,j,k = Di,k,k − 1 + ...
- spring boot 学习(八)定时任务 @Scheduled
SpringBoot 定时任务 @Scheduled 前言 有时候,我们有这样的需求,需要在每天的某个固定时间或者每隔一段时间让应用去执行某一个任务.一般情况下,可以使用多线程来实现这个功能:在 Sp ...
- Grep console 设置
Grep console DEBUG 9961B8 INFO 4B5E76 WARN 8A8A00 ERROR 9F6B00 8A7674
- hadoop mysql install (5)
reference : http://dblab.xmu.edu.cn/blog/install-mysql/ http://wiki.ubuntu.org.cn/MySQL #install mys ...
- 自定义div 拖动。键盘上下左右键移动,ctrl+Q控制是否可以移动,ctrl+回车,返回初始状态
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- glusterfs分布式存储
一,分布式文件系统理论基础 1.1 分布式文件系统出现 计算机通过文件系统管理,存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量 ...
- 传递数据后创建后台service来处理事件!
package com.lixu.service; import android.app.Service; import android.content.Intent; import android. ...
- Microsoft Jet 数据库引擎 SQL 和 ANSI SQL 的比较
http://westlife063.blog.163.com/blog/static/129942096201052591210384/ Microsoft Jet 数据库引擎 SQL 和 AN ...
- Linux C 中获取local日期和时间 time()&localtime()函数
1. time() 函数 /* time - 获取计算机系统当前的日历时间(Calender Time) * 处理日期时间的函数都是以本函数的返回值为基础进行运算 * * 函数原型: * #incl ...
- radio属性添加
经常会遇到js控制radio选中和切换的问题 之前一直使用的是checked属性来完成的 但是现在发现这个属性有个大问题 今天就是用js给选中radio的赋值,使用的$().attr("ch ...