MVCC&PURGE&分布式事务
Ⅰ、MVCC介绍
consistent non-locking read,通过行多版本控制的方式读取当前执行时间点的记录
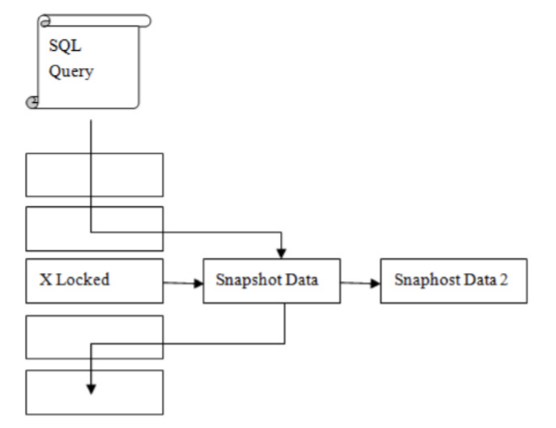
默认情况下innodb select没有任何锁,读到的记录在更新就通过undo读之前版本,serializable时候读会被阻塞,因为它默认加一个lock in share mode
--->like oracle
原理
undo && read_view
通过read_view判断一条记录是否可见,不可见(在更新被锁住)就通过undo回滚到之前版本,之前的版本再读trx_id,还不可见再回滚,rc只要回滚一个版本,rr可能要回滚很多版本,最大trx_id是持久化的,保存在共享表空间中
其实理解下就是事务在不在活跃列表中,在的话这个事务对记录做的动作就不可见需要找记录的前镜像(rc总是读最新的非锁定版本,rr总是读最老的非锁定版本,后续会有专门的文章说明)
举个栗子
session1:
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
(root@localhost) [test]> begin;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> update t set a = a + 1 where a = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 2 |
+------+
1 row in set (0.00 sec)
session2:
(root@localhost) [test]> begin;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
第一个会话开启事务更新记录,不提交,此时记录是被锁住的
新开一个会话去select 这条记录,并不会因为有锁而阻塞,读到的是原来的记录
此时commit之后,之前版本的undo是不能被马上回收的,因为其他线程可能还在引用之前版本的undo,真正的回收undo是purge线程做的
Ⅱ、purge线程
2.1 purge介绍
purge的作用是删除undo,真正删除一条记录(完成update和delete)
delete from table where pk=1;
在page中只是标记为删除,page上并没有真正的删除
相关参数:innodb_purge_threads 默认是1,5.7中设大一点,4或者8,都是ssd性能比较好
5.5之前所有的purge操作都是master thread做的
默认只有一个purge thread
innodb_purge_threads={0|1}
5.6
N purge thread
innodb_purge_threads={4}
2.2 purge具体过程
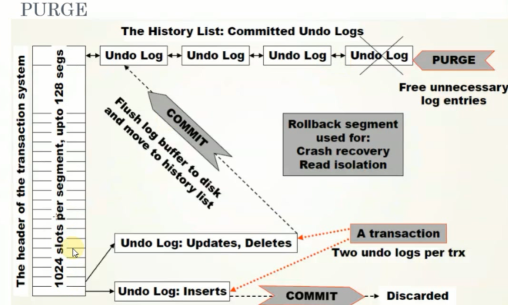
1024个槽------1024个undo回滚段,每个槽对应不同的undo日志
一旦事务提交,undo就放到hitory list中
tips:
因为记录不是有序的,所以purge操作需要大量离散读取操作
2.3 线上常见问题
undo不断增大,不能有效回收,导致系统空间不断增大,
最主要的原因有两个:
索引没有添加
检查slow log
存在大事务
拆大为小
其实就一点,一个事务执行时间很长,那对应的undo就不能回收,至少要commit完成后才能回收
另外回滚比提交慢非常多,commit很快,rollback需要的时间就是事务执行的时间,逻辑回滚
tips:
目前MySQL已经支持在线回收undo,详见阿里数据库内核月报
Ⅲ、分布式事务
之前我们谈到binlog和redo的一致性是通过一个内部的xa事务保证的,这里简单聊下外部的分布式事务
3.1 看下简单语法
(root@localhost) [test]> xa start 'a'; -- 开启一个分布式事务
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> insert into t values(2000);
Query OK, 1 row affected (0.09 sec)
(root@localhost) [test]> insert into t values(3000);
Query OK, 1 row affected (0.00 sec)
(root@localhost) [test]> xa end 'a'; -- 结束
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> xa prepare 'a'; -- 写prepare
Query OK, 0 rows affected (0.03 sec)
(root@localhost) [test]> xa recover; -- 看一眼,有一个分布式事务
+----------+--------------+--------------+------+
| formatID | gtrid_length | bqual_length | data |
+----------+--------------+--------------+------+
| 1 | 1 | 0 | a |
+----------+--------------+--------------+------+
1 row in set (0.00 sec)
(root@localhost) [test]> xa rollback 'a'; -- 回滚
Query OK, 0 rows affected (0.01 sec)
(root@localhost) [test]> xa recover; -- 再看下,没了
Empty set (0.00 sec)
这是再单实例上模拟的,意义不大
真正应用程序中两个实例做分布式事务,需要两边的prepare都成功才能最终提交
3.2 分布式事务的不完美
- client退出导致prepare成功事务丢失
- MySQL Server宕机导致binlog丢失
- 外部XA prepare成功不写日志
Ⅳ、事务编程
4.1 不好的事务习惯
- 在循环中提交事务,(fsync次数太多)
- 使用自动提交
- 使用自动回滚
create procedure load1(count int unsigned)
begin
declare s int unsigned default 1;
declare c char(80) default repeat('a',80);
while s <= count do
insert into t1 select NULL,c;
set s = s+1;
end while;
end
call load1(1000)
上面这个存储过程的调用,auto commit导致了insert会处罚一千次fsync
正确姿势:
begin;
call load1(1000)
commit;
- 错误的那种如果中间失败回滚都回不了,做不到原子性
- 将事务写到存储过程里面也不好,出错了就不好弄,不能自动回滚,所以存储过程只写逻辑,事务控制应用程序来做
4.2 大事务
事务拆大为小,原因就是binlog在搞鬼,其实不一定是大事务,大的操作都要拆吧
计算利息,拆了批量执行
update account
set account_total = account_total + (1 + interest_rate)
为什么要拆?老生常谈的、
- 写binlog成本大,导致主从延迟
- 避免过大的undo
题外话:
binlog是有点讨厌不像oracle用redo,历史原因,不好说
也有好处,做大数据平台集成非常简单,把MySQL的的数据实时推到大数据平台上太简单,github上一搜一大把项目直接用
MVCC&PURGE&分布式事务的更多相关文章
- MVCC/分布式事务简介
之前我们学习了RocksDB,但这还只是一个最基础的存储引擎.如果想把它在生产环境中用起来,还需要解决很多问题: 如何从单机扩展到分布式? 如何实现事务,并对事务进行并发控制? 用户接口能不能高级一点 ...
- 分布式事务(一)两阶段提交及JTA
原创文章,同步发自作者个人博客 http://www.jasongj.com/big_data/two_phase_commit/ 分布式事务 分布式事务简介 分布式事务是指会涉及到操作多个数据库(或 ...
- Google关于Spanner的论文中分布式事务的实现
Google关于Spanner的论文中分布式事务的实现 Google在Spanner相关的论文中详细的解释了Percolator分布式事务的实现方式, 而且用简洁的伪代码示例怎么实现分布式事务; Pe ...
- 分布式事务实现-Percolator
Google为了解决网页索引的增量处理,以及维护数据表和索引表的一致性问题,基于BigTable实现了一个支持分布式事务的存储系统.这里重点讨论这个系统的分布式事务实现,不讨论percolator中为 ...
- DTCC 2019 | 深度解码阿里数据库实现 数据库内核——基于HLC的分布式事务实现深度剖析
摘要:分布式事务是分布式数据库最难攻克的技术之一,分布式事务为分布式数据库提供一致性数据访问的支持,保证全局读写原子性和隔离性,提供一体化分布式数据库的用户体验.本文主要分享分布式数据库中的时钟解决方 ...
- 巨杉数据库SequoiaDB】巨杉Tech | SequoiaDB 分布式事务实现原理简介
1 分布式事务背景 随着分布式数据库技术的发展越来越成熟,业内对于分布式数据库的要求也由曾经只用满足解决海量数据的存储和读取这类边缘业务向核心交易业务转变.分布式数据库如果要满足核心账务类交易需求,则 ...
- 数据库内核——基于HLC的分布式事务实现深度剖析
DTCC 2019 | 深度解码阿里数据库实现 数据库内核--基于HLC的分布式事务实现深度剖析-阿里云开发者社区 https://developer.aliyun.com/article/70355 ...
- 硬核!2w 字长文爆肝分布式事务知识点!!
前言 分布式事务,是分布式架构中一个绕不开的话题,而什么是分布式事务?为什么要使用分布式事务?分布式事务有哪些实现方案?更是面试时面试官特别喜欢的一个分布式三连炮!同时用XMind画了一张导图记录分布 ...
- MySQL的本地事务、全局事务、分布式事务
本地事务 事务特性:ACID,其中C一致性是目的,AID是手段. 实现隔离性 写锁:数据加了写锁,其他事务不能写也不能读. 读锁:数据加了读锁,其他事务不能加写锁可以加读锁,可以允许自己升级为写锁. ...
随机推荐
- 【C#】C#线程_基元线程的同步构造
目录结构: contents structure [+] 简介 为什么需要使用线程同步 线程同步的缺点 基元线程同步 什么是基元线程 基元用户模式构造和内核模式构造的比较 用户模式构造 易变构造(Vo ...
- invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
Mac系统升级git会找不到并且报错:xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools) ...
- Delphi目录监控、目录监听
资料地址: 1.https://www.cnblogs.com/studypanp/p/4890970.html 单元代码: (************************************ ...
- hdoj:2071
Max Num Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Sub ...
- 【nodejs】初识 NodeJS(一)
构建一个基础的 http 服务器 需要引用 http 模块,http 模块是 node.js 的内置模块. var http = require('http'); http.createServer( ...
- HTTP 02 HTTP1.1 协议
发送请求: 返回时, content-type 与 HTTP 正文之间有一个空格 HTTP 是不保存状态协议, 也就是说在 HTTP 这个级别, 协议对于发送过的请求或相应都不做持久化处理. 但是, ...
- windows下局域网文件共享,不需要登录账号密码
基于局域网中,有时候需要传输一个大的文件都需要用到U盘,很麻烦,所以优选文件共享.但是有时候会出现需要登录账户密码,所以需要设置第三步,步骤如下: 1.选中要共享的文件夹,右键有一个共享选项,点击出现 ...
- linux shell的here document用法(cat << EOF)
什么是Here Document?Here Document 是在Linux Shell 中的一种特殊的重定向方式,它的基本的形式如下cmd << delimiter Here Docu ...
- Vivado Design Suite用户指南之约束的使用第二部分(约束方法论)
Constraints Methodology(约束方法论) 关于约束方法论 设计约束定义了编译流程必须满足的要求,以使设计在板上起作用. 并非所有步骤都使用所有约束在编译流程中. 例如,物理约束仅在 ...
- python使用微信推送消息
from wxpy import * #该库主要是用来模拟与对接微信操作的 import requests from datetime import datetime import time impo ...