Sample Means(耶鲁大学教材)
Sample Means
The sample mean 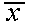 from a group of observations is an estimate of the population mean
from a group of observations is an estimate of the population mean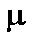 .
.
Given a sample of sizen, consider n independent random variables
X1,X2, ..., Xn, each corresponding to one randomly selected observation. Each of these variables has the distribution of the population, with mean
and standard deviation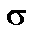 . The sample mean is defined to be
. The sample mean is defined to be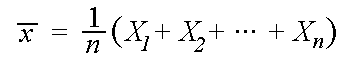 .
.
By the properties of means and variances of random variables, the mean and variance of the sample mean are the following:
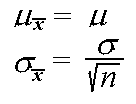
Although the mean of the distribution of is identical to the mean of the population distribution, the variance is much smaller for large sample sizes.
For example, suppose the random variable X records a randomly selected student's score on a national test, where the population distribution for the score is normal with mean 70 and standard deviation 5 (N(70,5)). Given asimple
random sample (SRS) of 200 students, the distribution of the sample mean score has mean 70 and standard deviation 5/sqrt(200) = 5/14.14 = 0.35.
Distribution of the Sample Mean
When the distribution of the population is normal, then the distribution of the sample mean is also normal. For a normal population distribution with mean and
standard deviation, the distribution of the sample mean is normal, with mean
and standard deviation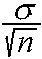 .
.
This result follows from the fact that any linear combination of independent normal random variables is also normally distributed. This means that for two independent normal random variablesX and
Y and any constants a and b, aX + bY will be normally distributed. In the case of the sample mean, the linear combination is
=(1/n)*(X1 + X2 + ... Xn).
For example, consider the distributions of yearly average test scores on a national test in two areas of the country. In the first area, the test scoreX is normally distributed with mean 70 and standard deviation 5. In the second area, the yearly
average test scoreY is normally distributed with mean 65 and standard deviation 8. The differenceX - Y between the two areas is normally distributed, with mean 70-65 = 5 and variance 5² + 8² = 25 + 64 = 89. The standard deviation is the square
root of the variance, 9.43. The probability that areaX will have a higher score than area
Y may be calculated as follows:
P(X > Y) = P(X - Y > 0)
= P(((X - Y) - 5)/9.43 > (0 - 5)/9.43)
= P(Z > -0.53) = 1 - P(Z < -0.53) = 1 - 0.2981 = 0.7019.
Area X will have a higher average score than area Y about 70% of the time.
The Central Limit Theorem
The most important result about sample means is the Central Limit Theorem. Simply stated, this theorem says that for a large enough sample sizen, the distribution of the sample mean
will approach a normal distribution.This is true for a sample of independent random variables from
any population distribution, as long as the population has a finite standard deviation.
A formal statement of the Central Limit Theorem is the following:
If is the mean of a random sampleX1, X2, ... , Xn of size
n from a distribution with a finite mean and a finite positive variance²,
then the distribution ofW = 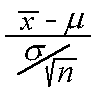 isN(0,1) in the limit as n approaches infinity.
isN(0,1) in the limit as n approaches infinity.
This means that the variable is distributedN(,).
One well-known application of this theorem is the normal approximation to the binomial distribution.
Example
Using the MINITAB "RANDOM" command with the "UNIFORM" subcommand, I generated 100 samples of size 50 each from the Uniform(0,1) distribution. The mean of this distribution is 0.5, and its standard deviation is approximately 0.3. I then applied the "RMEAN" command
to calculate the sample mean across the rows of my sample, resulting in 50 sample mean values (each of which represents the mean of 100 observations). The MINITAB "DESCRIBE" command gave the following information about the sample mean data:
Descriptive Statistics Variable N Mean Median Tr Mean StDev SE Mean
C101 50 0.49478 0.49436 0.49450 0.02548 0.00360 Variable Min Max Q1 Q3
C101 0.43233 0.55343 0.47443 0.51216
The mean 0.49 is nearly equal to the population mean 0.5. The desired value for the standard deviation is the population standard deviation divided by the square root of the size of the sample (which is 10 in this case), approximately 0.3/10 = 0.03. The calculated
value for this sample is 0.025. To evaluate the normality of the sample mean data, I used the "NSCORES" and "PLOT" commands to create a normal quantile plot of the data, shown below.
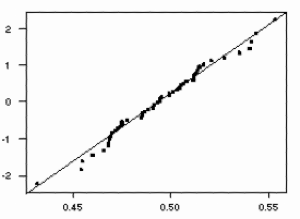
The plot indicates that the data follow an approximately normal distribution, lying close to a diagonal line through the main body of the points.
Sample Means(耶鲁大学教材)的更多相关文章
- Joel在耶鲁大学的演讲
Joel Spolsky是一个美国的软件工程师,他的网络日志"Joel谈软件"(Joel on Software)非常有名,读者人数可以排进全世界前100名. 上个月28号,他回到 ...
- 如何获得大学教材的PDF版本?
最近急需一本算法书的配套答案,这本配套单独出售,好像在市面上还买不到,在淘宝上搜索也只是上一个版本,并没有最新版本,让我很无奈.加上平时肯定会有这么一种情况,想看一些书,但买回来也看不了几次,加上计算 ...
- 加州大学伯克利分校Stat2.3x Inference 统计推断学习笔记: Section 4 Dependent Samples
Stat2.3x Inference(统计推断)课程由加州大学伯克利分校(University of California, Berkeley)于2014年在edX平台讲授. PDF笔记下载(Acad ...
- 加州大学伯克利分校Stat2.3x Inference 统计推断学习笔记: Section 3 One-sample and two-sample tests
Stat2.3x Inference(统计推断)课程由加州大学伯克利分校(University of California, Berkeley)于2014年在edX平台讲授. PDF笔记下载(Acad ...
- 世界名校网络课程大盘点,美国大学CS专业十三大研究方向,世界50所知名大学提供开放课程
世界名校网络课程大盘点 加州大学伯克利分校http://webcast.berkeley.edu/ 加州大学伯克利分校与斯坦福大学. 麻省理工学院等一同被誉为美国工程科技界的学术 领袖,其常年位居 ...
- 美国大学排名之本科中最用功的学校top15
美国大学排名之本科中最用功的学校top15 威久留学2016-07-29 13:15:59美国留学 留学新闻 留学选校阅读(490)评论(1) 去美国留学的同学可能都知道USnews美国大学排名, ...
- 斯坦福大学Andrew Ng教授主讲的《机器学习》公开课观后感[转]
近日,在网易公开课视频网站上看完了<机器学习>课程视频,现做个学后感,也叫观后感吧. 学习时间 从2013年7月26日星期五开始,在网易公开课视频网站上,观看由斯坦福大学Andrew Ng ...
- 计算机专业-世界大学学术排名,QS排名,U.S.NEWS排名
2015年美国大学计算机专业排名 计算机专业介绍:计算机涉及的领域非常广泛,其分支学科也是非常多.所以在美国将主要的专业方向分为人工智能,程序应用,计算机系统(Systems)以及计算机理论(theo ...
- 办理卡尔加里大学(本科)学历认证『微信171922772』calgary学位证成绩单使馆认证University of calgary
办理卡尔加里大学(本科)学历认证『微信171922772』calgary学位证成绩单使馆认证University of calgary Q.微信:171922772办理教育部国外学历学位认证海外大学毕 ...
随机推荐
- noip第14课资料
- CentOS 7安装新版RabbitMQ解决Erlang 19.3版本依赖
通过yum等软件仓库都可以直接安装RabbitMQ,但版本一般都较为保守. RabbitMQ官网提供了新版的rpm包(http://www.rabbitmq.com/download.html),但是 ...
- 【spring源码分析】IOC容器初始化——查漏补缺(一)
前言:在[spring源码分析]IOC容器初始化(十一)中提到了初始化bean的三个步骤: 激活Aware方法. 后置处理器应用(before/after). 激活自定义的init方法. 这里我们就来 ...
- LOJ#6387 「THUPC2018」绿绿与串串 / String (Manacher || hash+二分)
题目描述 绿绿和 Yazid 是好朋友.他们在一起做串串游戏. 我们定义翻转的操作:把一个串以最后一个字符作对称轴进行翻转复制.形式化地描述就是,如果他翻转的串为 RRR,那么他会将前 ∣R∣−1个字 ...
- WCF透明代理类,动态调用,支持async/await
我们希望WCF客户端调用采用透明代理方式,不用添加服务引用,也不用Invoke的方式,通过ChannelFactory<>动态产生通道,实现服务接口进行调用,并且支持async/await ...
- C++primer笔记之顺序容器
最近又重新拾起C++primer,发现每一次看都会有不同的体验,但每一次看后因为不常用,忘记得很快,所以记笔记是很关键的一环,咋一看是浪费时间,实际上是节省了很多时间.下面就把这一节的内容做一个简单的 ...
- 测试工具之RobotFramework界面基本功能使用
安装好RobotFramework后,直接在运行或者命令行中执行ride.py即可启动RF 启动完成后的界面如下: 界面很简洁,然后我们开始点击file并创建project: 接下来右键project ...
- shell之实战应用一(查找xml文档中的关键字段)
前几天同事问我一个问题,说如下的文档中,如何把name后面的字段(红色框中的字段)单独打印出来?
- .net core Jenkins持续集成Linux、Docker、K8S
jenkins插件 系统管理 -> 管理插件,安装如下插件. #如果搜索不到去掉Plugin在搜索 GitLab Plugin Gitlab Hook Plugin #使用Gitlab账号做用户 ...
- Set "$USE_DEPRECATED_NDK=true" in gradle.properties to continue using the current NDK integration. 解决办法
1.将 jni 文件夹名改为 cpp: 2.添加 CMakeLists.txt; 3.修改 build.gradle; externalNativeBuild { cmake { path " ...