[04] 高级映射 association和collection
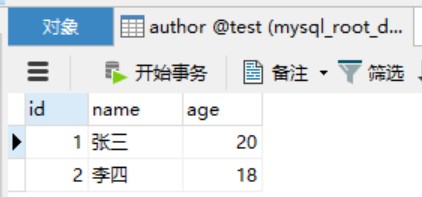
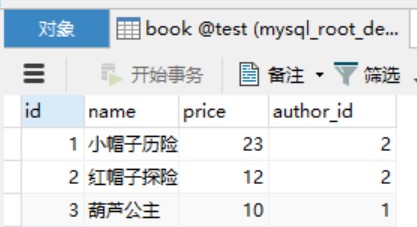
public class Book {
private long id;
private String name;
private int price;
private Author author;
//... getter and setter
}public class Book {
private long id;
private String name;
private int price;
private Author author;
//... getter and setter
}
public class Author {
private long id;
private String name;
private int age;
private List<Book> bookList;
//... getter and setter
}public class Author {
private long id;
private String name;
private int age;
private List<Book> bookList;
//... getter and setter
}
1、association 关联
1.1 method1
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="price" column="price" />
<!--关联属性-->
<association property="author" javaType="dulk.learn.mybatis.pojo.Author">
<!--注:此处column应为book中外键列名-->
<id property="id" column="author_id" />
<!--注:避免属性重名,否则属性值注入错误-->
<result property="name" column="authorName" />
<result property="age" column="authorAge" />
</association>
</resultMap>
<!--嵌套查询,结果映射只能使用resultMap-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper><mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="price" column="price" />
<!--关联属性-->
<association property="author" javaType="dulk.learn.mybatis.pojo.Author">
<!--注:此处column应为book中外键列名-->
<id property="id" column="author_id" />
<!--注:避免属性重名,否则属性值注入错误-->
<result property="name" column="authorName" />
<result property="age" column="authorAge" />
</association>
</resultMap>
<!--嵌套查询,结果映射只能使用resultMap-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>
- property - 关联对象在类中的属性名(即Author在Book类中的属性名,author)
- javaType - 关联对象的Java类型
- id中的column属性,其值应该尽量使用外键列名,主要是对于重名的处理,避免映射错误
- 同样的,对于result中的column属性的值,也要避免重名带来的映射错误,如上例若 a.name 不采用别名 "authorName",则会错误地将 b.name 赋值给Author的name属性
1.2 method2
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<!--author的resultMap-->
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="authorId"/>
<result property="name" column="authorName"/>
<result property="age" column="authorAge"/>
</resultMap>
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--引用author的resultMap-->
<association property="author" resultMap="authorResultMap" />
</resultMap>
<!--注意这里a.id的别名和authorResultMap中相对应-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.id AS 'authorId',
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper><mapper namespace="dulk.learn.mybatis.dao.BookDao">
<!--author的resultMap-->
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="authorId"/>
<result property="name" column="authorName"/>
<result property="age" column="authorAge"/>
</resultMap>
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--引用author的resultMap-->
<association property="author" resultMap="authorResultMap" />
</resultMap>
<!--注意这里a.id的别名和authorResultMap中相对应-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.id AS 'authorId',
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>
1.3 method3
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--使用select属性进行查询关联-->
<association property="author" column="author_id" javaType="dulk.learn.mybatis.pojo.Author" select="findAuthorById"/>
</resultMap>
<!--简化了book的查询语句,不再需要与其他表关联-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT b.*
FROM book b
WHERE b.id = #{id}
</select>
<!--新增了author表的查询语句,将会被调用获取结果并组装给book-->
<select id="findAuthorById" parameterType="long" resultType="dulk.learn.mybatis.pojo.Author">
SELECT *
FROM author
WHERE id = #{id}
</select>
</mapper><mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--使用select属性进行查询关联-->
<association property="author" column="author_id" javaType="dulk.learn.mybatis.pojo.Author" select="findAuthorById"/>
</resultMap>
<!--简化了book的查询语句,不再需要与其他表关联-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT b.*
FROM book b
WHERE b.id = #{id}
</select>
<!--新增了author表的查询语句,将会被调用获取结果并组装给book-->
<select id="findAuthorById" parameterType="long" resultType="dulk.learn.mybatis.pojo.Author">
SELECT *
FROM author
WHERE id = #{id}
</select>
</mapper>
2、collection 集合
<mapper namespace="dulk.learn.mybatis.dao.AuthorDao">
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="age" column="age" />
<!--使用collection属性,ofType为集合内元素的类型-->
<collection property="bookList" ofType="dulk.learn.mybatis.pojo.Book" columnPrefix="book_">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="price" column="price" />
</collection>
</resultMap>
<select id="findById" parameterType="long" resultMap="authorResultMap">
SELECT a.*, b.id AS 'book_id', b.name AS 'book_name', b.price AS 'book_price'
FROM author a, book b
WHERE a.id = b.author_id
AND a.id = #{authorId}
</select>
</mapper><mapper namespace="dulk.learn.mybatis.dao.AuthorDao">
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="age" column="age" />
<!--使用collection属性,ofType为集合内元素的类型-->
<collection property="bookList" ofType="dulk.learn.mybatis.pojo.Book" columnPrefix="book_">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="price" column="price" />
</collection>
</resultMap>
<select id="findById" parameterType="long" resultMap="authorResultMap">
SELECT a.*, b.id AS 'book_id', b.name AS 'book_name', b.price AS 'book_price'
FROM author a, book b
WHERE a.id = b.author_id
AND a.id = #{authorId}
</select>
</mapper>
- 第一种即 column 的值和列名完全一致,如 column="book_id"
- 第二种也就是推荐的方式,在 collection 中使用属性 columnPrefix 来定义统一前缀,在接下来的 column 中就可以减少工作量了,如上例中 columnPrefix = "book_",column = "id",它们的效果等同于 column = "book_id"
[04] 高级映射 association和collection的更多相关文章
- mybatis入门基础(六)----高级映射(一对一,一对多,多对多)
一:订单商品数据模型 1.数据库执行脚本 创建数据库表代码: CREATE TABLE items ( id INT NOT NULL AUTO_INCREMENT, itemsname ) NOT ...
- 【Mybatis高级映射】一对一映射、一对多映射、多对多映射
前言 当我们学习heribnate的时候,也就是SSH框架的网上商城的时候,我们就学习过它对应的高级映射,一对一映射,一对多映射,多对多映射.对于SSM的Mybatis来说,肯定也是差不多的.既然开了 ...
- MyBatis学习--高级映射
简介 前面说过了简单的数据库查询和管理查询,在开发需求中有一些一对一.一对多和多对多的需求开发,如在开发购物车的时候,订单和用户是一对一,用户和订单是一对多,用户和商品是多对多.这些在Hibernat ...
- Mybatis学习记录(六)----Mybatis的高级映射
1.一对多查询 1.1 需求 查询订单及订单明细的信息. 1.2 sql语句 确定主查询表:订单表 确定关联查询表:订单明细表 在一对一查询基础上添加订单明细表关联即可. SELECT orders. ...
- 六 mybatis高级映射(一对一,一对多,多对多)
1 订单商品数据模型 以订单商品数据为模型,来对mybaits高级关系映射进行学习.
- Mybatis(四) 高级映射,一对一,一对多,多对多映射
天气甚好,怎能不学习? 一.单向和双向 包括一对一,一对多,多对多这三种情况,但是每一种又分为单向和双向,在hibernate中我们就详细解析过这单向和双向是啥意思,在这里,在重复一遍,就拿一对多这种 ...
- 高级映射,查询缓存和与spring整合
一.高级映射 -------一对一 这里以订单查询为例,其中有一个外键为user_id,通过这个关联用户表.这里要实现的功能是这个两个表关联查询,得到订单的信息和部分user的信息.order表结构如 ...
- javaMybatis映射属性,高级映射
映射文件的sql属性: id:标识符(一般都是dao层方法名) resultType:sql返回类型 resultMap:放回的映射类型 parameterType:参数类型 useGenerated ...
- mybatis高级映射(一对一,一对多)
mybatis高级映射 一对一关联映射 需求:查询订单信息,关联查询用户信息(一个订单对应一个用户) (1)通过resultType实现 sql语句: select orders.* , USER.u ...
随机推荐
- 《Inside C#》笔记(四) 类
类是对数据结构和算法的封装. 一 类成员 类成员包括以下几类,作者在后面的章节会详细讲解. 字段(用来保存数据,可用static readonly const来修饰).方法(操作数据的代码).属性(用 ...
- 《Inside C#》笔记(二) 初识C#
一 程序的编译.构成 a) 编写C#代码一般用VS,但作者在这儿介绍了使用记事本编写C#代码并编译运行的过程,以便对VS有更深入的认识. 用记事本编写C#代码后,修改文本文件的后缀为.cs,然后用cs ...
- Expo大作战(三十)--expo sdk api之Permissions(权限管理模块),Pedometer(计步器api)
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- webservice偶尔报黄页,解决方案
在system.web节点里加以下代码 <webServices> <protocols> <add name="HttpSoa ...
- ARP单播请求?
在我的理解中,ARP请求是已知对方的IP地址,想要请求对方的MAC地址,用以封装以太网帧头.因此在不知道对方MAC地址的情况下,会广播ARP请求到整个子网,让子网中的所有设备收到这个广播ARP请求报文 ...
- Jmeter参数化方法
用Jmeter测试时包含两种情况的参数:一种是在url中,一种是请求中需要发送的参数. 设置参数值的方法有如下几种: 一.函数助手 用Jmeter中的函数获取参数值,__Random,__thread ...
- NFS服务搭建与配置
启动NFS SERVER之前,首先要启动RPC服务(CentOS5.8下为portmap服务,CentOS6.6下为rpcbind服务,下同),否则NFS SERVER就无法向RPC服务注册了.另外, ...
- banner图片全屏显示
<script> $(function () { function reinitSize() { var window_h = $(window).height(); var window ...
- oracle经验记录
1.添加新User时必须要增加的角色权限:connect.dba.resource 2.添加表空间的语句 create tablespace DEMOSPACE datafile 'D:/test.d ...
- golang类型判断
_.ok:=interface{}(a).(B) 此语句用于判断对象a是否是B类型 也可以判断对象a是否实现了B接口 package main import "fmt" type ...