Crowdsourcing[智能辅助标注]
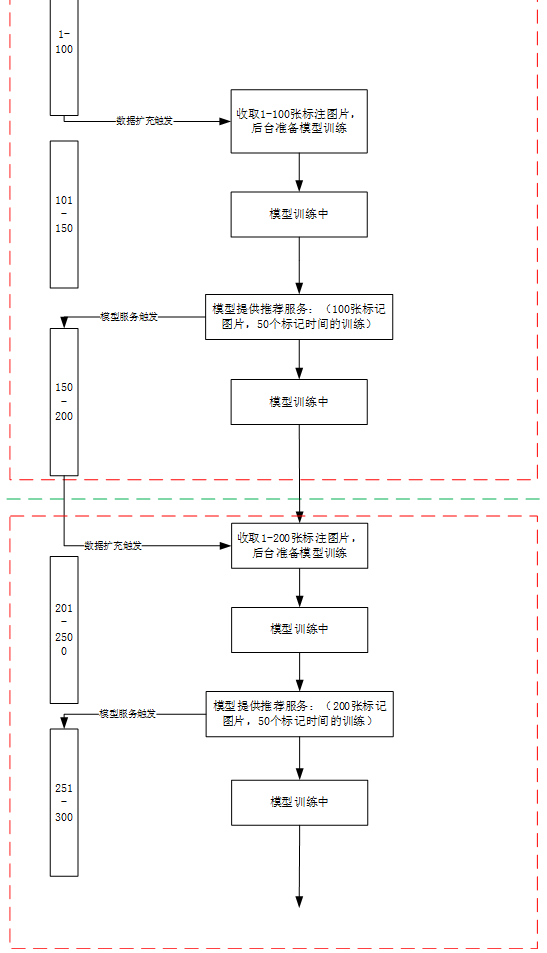
为了实现标注平台智能辅助标注的能力,即上传一个标注任务,开始不提供辅助任务,随着用户标注的进行,后台可以收集一部分的标记数据,然后开启模型训练,并接着提供模型服务功能。然后再收集数据,再不断的训练,然后更新服务端的模型。随着标记的进行,模型的准确度也会越来越高。从而达到随着时间的进行,人工标注会从最开始的从0标注转换成只是对模型预先标注的结果进行校对的目的。
即实现下述目的
其中对应的时序图如下
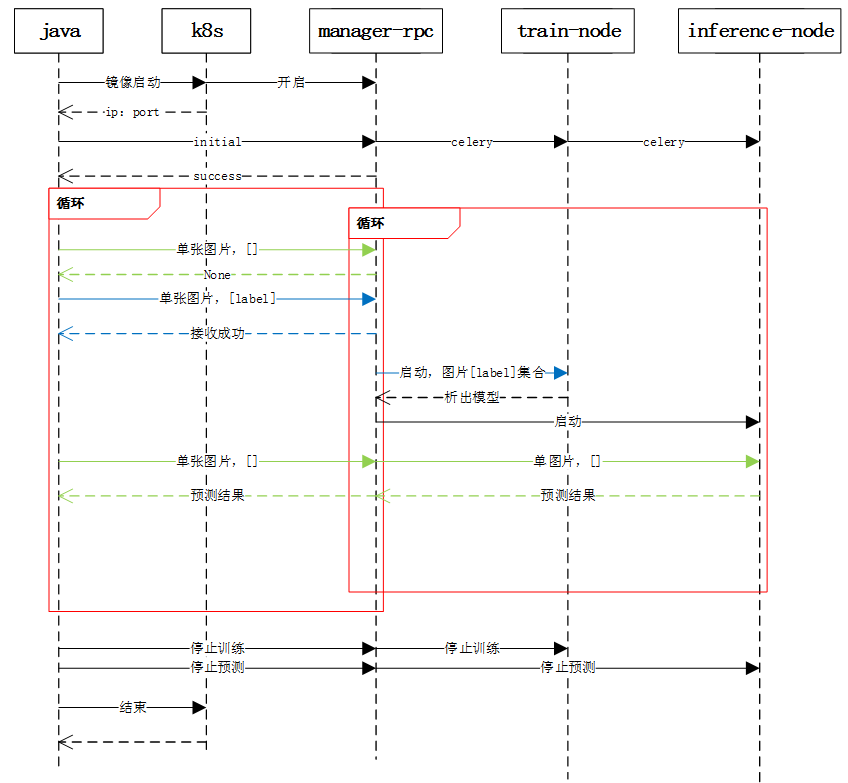
智能辅助标注时序图
这里要考虑的问题是任务之间独立性,即任务之间的模型不能干扰。
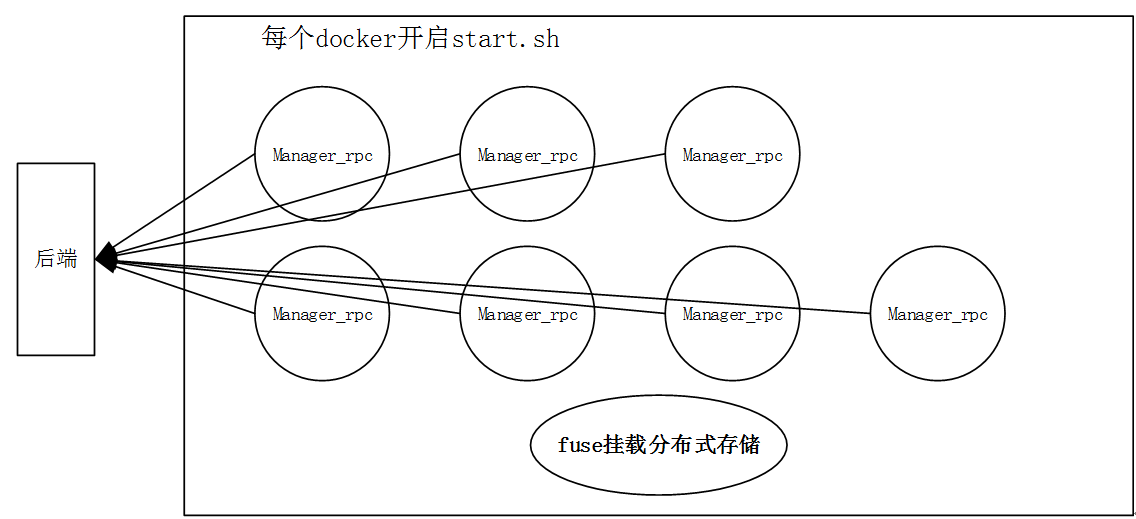
0 申请3(train)+4(inference)个docker(每个docker关联一块gpu),一个分布式存储,并fuse挂载

1 - 运行start.sh,其中开启manager_rpc.py
1.1– 内置运行init函数:
- i)收集本机ip,可用端口(用于manager_rpc的开启)
- ii)hostname (后续用于rabbitmq)
- iii)开启本机rabbitmq-server
- iv) erlang.cookie(用于后续rabbitmq集群构建)
1.2 基于注册地址,提交本机上述信息,并开启本机manager_rpc
2 基于1.1收集的信息,需要指定哪几台用于train,哪几台用于inference
'''
machines_info:[{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'train'},
{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'train'}
...
{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'inference'}
]
task_category: # 当前任务类别如 “图像分类”
task_extra_info: #当前任务的额外信息如: "多分类”
task_datastore_path当前任务所需要在共享存储上的位置:
映射到每个docker内部位置为:
/home/datastore: (生成下述三个子文件夹,分别为存储服务模型;数据预处理;训练节点恢复模型)
Inference/model-time0
model-time1
Proprecess/
Snapshot/***.ckpt
'''
将上述信息分别发送给这7个manager_rpc的initial

2.1 每个initial接口执行以下行为:
- i)通过接收的参数检测且ping是否能够ping通,划分好机器和坏机器;将好机器列表的[ip,hostname]写入到各自的/etc/hosts
- ii)基于好机器,选取当前对应的train_master,inference_master。选取规则为ip最小的那台
- iii)基于本机检测是否是inference,且非inference_master,则构建rabbitmq集群
- 停止rabbitmq-server;
- 修改erlang.cookie
- 开启rabbitmq-server
- 向inference_master注册构建集群
- iv)开启celery,其中celery按照本机的角色,开启对应的脚本,如果是train,则多开一个数据处理celery
if type == 'train':
sp.run(f'( {binpath}/start_data & )', shell=True)
sp.run(f'( {binpath}/start_{type} & )', shell=True)
- v)返回好机器和坏机器列表,自己节点当前的erlang.cookies,从而保证后台的全局同步,有利于新增节点的erlang.cookies
initial的返回数据
ans = {'rpc':rpc,
'bad_machines_info':badMachinesInfo,
'good_machines_info':goodMachinesInfo,
'master_train':master_train.get('ip',''),
'master_inference':master_inference.get('ip',''),
'erlang_hash':open('/var/lib/rabbitmq/.erlang.cookie').read(),
}
其中每个celery的配置broker和backend为
BROKER_URL = 'amqp://guest:guest@127.0.0.1:5672'
CELERY_RESULT_BACKEND = 'amqp:// '
Vi)开启对应角色rpc
- i)传递共享存储路径
- ii)返回服务角色的rpc

如果是inference_rpc,则自动按照好机器个数,开启fork形式的服务模式,此时集群由rabbitmq-server负责建立
如果是train,则只开启processes=1的主进程服务模式,此时train集群由train_node自己建立,如tensorflow的分布式版本。
master_train节点的Train_rpc接收有标签图片的数据链接,将其通过celery传递给后台worker的train_node,train_node负责下载,预处理等
master_inference节点的Inference_rpc接收无标签图片的数据连接,将其通过celery传递给后台worker的inference_node,inference_node负责下载,预处理,然后将结果通过celery返回,此时每个节点都可以作为master通过整个rabbitmq-server集群将任务分散给其他inference角色的docker.这里的master_inference仅仅是为了rabbitmq的erlang.cookies的同步。
Crowdsourcing[智能辅助标注]的更多相关文章
- 【HMS Core 6.0全球上线】Toolkit,您的智能辅助编程好帮手
HMS Core 6.0已于7月15日全球上线.本次版本中,华为HMS Toolkit向广大开发者推出了智能辅助编程助手SmartCoder,帮助开发者轻松高效地集成HMS Core,开发新功能,创建 ...
- Visual Studio 2022有趣又强大的智能辅助编码
工欲善其事,必先利其器 作为一名.Net开发人员,开发利器当然是首选微软自家的:宇宙第一IDE - Visual Studio了. 这不 VS 2022 正式版已经发布近两个月了,我也体验了近两个月, ...
- MTK Android SwitchPreference(设置-智能辅助-导航栏-导航栏可隐藏)
1.界面布局文件 packages/apps/PrizeSettings/res/xml/navigation_bar_prize.xml ------------------------------ ...
- 百度大脑UNIT3.0智能对话技术全面解析
智能客服.智能家居.智能助手.智能车机.智能政务……赋予产品智能对话能力是提升产品智能化体验.高效服务的重要手段,已经开始被越来越多的企业关注并布局.然而,智能对话系统搭建涉及NLP.知识图谱.语音等 ...
- Python交互图表可视化Bokeh:2. 辅助参数
图表辅助参数设置 辅助标注.注释.矢量箭头 参考官方文档:https://bokeh.pydata.org/en/latest/docs/user_guide/annotations.html#col ...
- 设计师别浪费时间啦,快来试试这款Sketch标注插件吧
随着移动互联网的快速发展,用户的需求也在不断地增大,这对产品经理还有设计师的考验是越来越大.市场环境的变化让我们深信为快不破,但是一个产品的产出需要各个环节的紧密配合,但往往在产品输出过程中,由于分工 ...
- 设计师都爱用的UI标注软件有哪些?
UI标注软件现在是设计师(UI.PM.前端等)必备的一款软件.设计稿是UI设计师日常工作中的产出物之一,当然,做出了高保真设计稿并不意味着你的工作结束了,因为你还得与下游的开发工程师进行对接. 我们经 ...
- 曼孚科技:数据标注,AI背后的百亿市场
1. 两年前,来自山东农村的王磊成为了一位数据标注员.彼时的他,工作内容非常简单且枯燥:识别图片中人的性别. 然而,一段时间之后,他注意到分配给他的任务开始变得越来越复杂:从识别性别到年龄,从框选 ...
- 基于脑波眼电-语音-APP控制的多功能智能轮椅
前言:这个项目是在2016-2017完成的,做的很浅显,贴出来与大家分享,希望能有帮助. 摘要 本项目主要是针对脑电信号控制的智能轮椅的设计,脑电控制是智能医疗领域的重要研究方向,旨在帮助行动不便但智 ...
随机推荐
- CSS&JS两种方式实现手风琴式折叠菜单
<div class="accordion"> <div id="one" class="section"> < ...
- Web.config配置customErrors mode为Off后依然不显示具体错误的可能原因。
有时候我们的网站程序在本地运行没有问题,但在上传到远程服务器后则报错.这就需要我们了解具体错误,但IIS默认只显示统一的运行时错误,想要知道具体错误就需要配置Web.config中customErro ...
- SQLite 知识摘要 --- 事务
在许多时候,我们在使用大数据的时候会发现,尽管sqlite数据库的执行效率已经很快了,但是还是满足不了我们的需求,这时候我们会很容易考虑到使用并发的方式去访问sqlite数据库,但是sqlite数据独 ...
- CentOS7.4 系统下 Tomcat 启动慢解决方法
CentOS7.4 系统下 Tomcat 启动慢解决的方法 首先查看日志信息,查看因为什么而启动慢 在CentOS7启动Tomcat时,启动过程很慢,需要几分钟,经过查看日志,发现耗时在这里:是s ...
- loadrunner 脚本开发-url解码
url解码 by:授客 QQ:1033553122 脚本结构如下: Action.c中的代码如下: int htoi(char *s) { int value = 0; int c = 0; c = ...
- Android 开创java世界(JNI Invocation API)
在Android的世界中,由名称为app_process的C++本地应用程序(路径为:framework/base/cmds/app_process/app_main.cpp)调用JNI Invoca ...
- SpringMVC的启动
Spring MVC中的Servlet Spring MVC中Servlet一共有三个层次,分别是HttpServletBean.FrameworkServlet和DispatcherServlet. ...
- DB2表被锁,如何解锁
原因与解决方案 1.原因:修改表结构表结构发生变化后再对表进行任何操作都不被允许,SQLState为57016(因为表不活动,所以不能对其进行访问),由于修改了表字段权限,导致表处于不可用状态 2.解 ...
- python第四十八天--高级FTP
高级FTP服务器1. 用户加密认证2. 多用户同时登陆3. 每个用户有自己的家目录且只能访问自己的家目录4. 对用户进行磁盘配额.不同用户配额可不同5. 用户可以登陆server后,可切换目录6. 查 ...
- 【第七篇】SAP ABAP7.5x新语法之F4增强
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:SAP ABAP7.5x系列之F4增强 前言部分 ...