Tensorflow实现稀疏自动编码(SAE)
1.概述
人在获取图像时,并不是像计算机逐个像素去读,一般是扫一眼物体,大致能得到需要的信息,如形状,颜色,特征。怎么让机器也有这项能力呢,稀疏编码来了。
定义:
稀疏自编码器(Sparse Autoencoder)可以自动从无标注数据中学习特征,可以给出比原始数据更好的特征描述。在实际运用时可以用稀疏编码器发现的特征取代原始数据,这样往往能带来更好的结果。
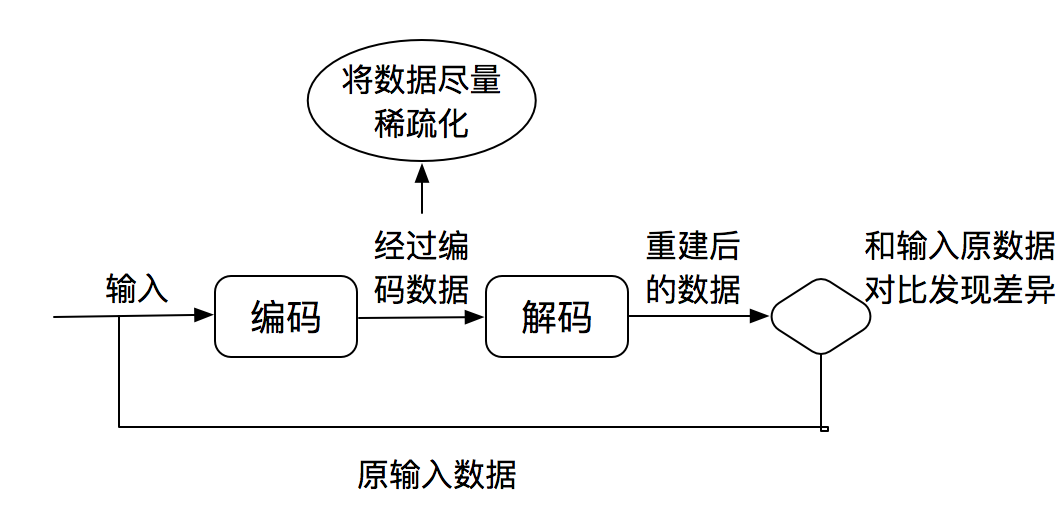
上图就是稀疏编码的一半流程,清晰的说明了稀疏编码的过程。
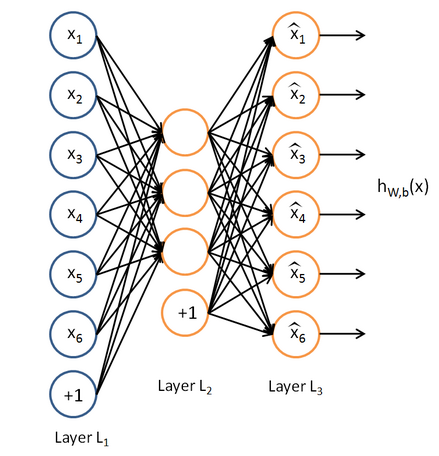
自编码器要求输出尽可能等于输入,并且它的隐藏层必须满足一定的稀疏性,即隐藏层不能携带太多信息。所以隐藏层对输入进行了压缩,并在输出层中解压缩。整个过程肯定会丢失信息,但训练能够使丢失的信息尽量少。通过引入惩罚机制和BP算法解决最小化信息丢失问题。
2.代码实现
#coding=utf-8
'''
Created on 2016年12月3日
@author: chunsoft
'''
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入 MNIST 数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# 参数
learning_rate = 0.01 #学习速率
training_epochs = 20 #训练批次
batch_size = 256 #随机选择训练数据大小
display_step = 1 #展示步骤
examples_to_show = 10 #显示示例图片数量
# 网络参数
#我这里采用了三层编码,实际针对mnist数据,隐层两层,分别为256,128效果最好
n_hidden_1 = 512 #第一隐层神经元数量
n_hidden_2 = 256 #第二
n_hidden_3 = 128 #第三
n_input = 784 #输入
#tf Graph输入
X = tf.placeholder("float", [None,n_input])
#权重初始化
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'encoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_2])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h3': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
#偏置值初始化
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b3': tf.Variable(tf.random_normal([n_input])),
}
# 开始编码
def encoder(x):
#sigmoid激活函数,layer = x*weights['encoder_h1']+biases['encoder_b1']
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
return layer_3
# 开始解码
def decoder(x):
#sigmoid激活函数,layer = x*weights['decoder_h1']+biases['decoder_b1']
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
return layer_3
# 构造模型
encoder_op = encoder(X)
encoder_result = encoder_op
decoder_op = decoder(encoder_op)
#预测
y_pred = decoder_op
#实际输入数据当作标签
y_true = X
# 定义代价函数和优化器,最小化平方误差,这里可以根据实际修改误差模型
cost = tf.reduce_mean(tf.pow(y_true-y_pred, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
# 初始化变量
init = tf.initialize_all_variables();
# 运行Graph
with tf.Session() as sess:
sess.run(init)
#总的batch
total_batch = int(mnist.train.num_examples/batch_size)
# 开始训练
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 展示每次训练结果
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# Applying encode and decode over test set
#显示编码结果和解码后结果
encodes = sess.run(
encoder_result, feed_dict={X: mnist.test.images[:examples_to_show]})
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 对比原始图片重建图片
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
f.show()
plt.draw()
plt.waitforbuttonpress()Tensorflow实现稀疏自动编码(SAE)的更多相关文章
- 稀疏自动编码之反向传播算法(BP)
假设给定m个训练样本的训练集,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数: 那么整个训练集的损失函数定义如下: 第一项是所有样本的方差的均值.第二项是一个归一化项( ...
- paper 53 :深度学习(转载)
转载来源:http://blog.csdn.net/fengbingchun/article/details/50087005 这篇文章主要是为了对深度学习(DeepLearning)有个初步了解,算 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- [UFLDL] *Sparse Representation
Deep learning:二十九(Sparse coding练习) Deep learning:二十八(使用BP算法思想求解Sparse coding中矩阵范数导数) Deep learning:二 ...
- 稀疏自编码器及TensorFlow实现
自动编码机更像是一个识别网络,只是简单重构了输入.而重点应是在像素级重构图像,施加的唯一约束是隐藏层单元的数量. 有趣的是,像素级重构并不能保证网络将从数据集中学习抽象特征,但是可以通过添加更多的约束 ...
- 学习笔记TF057:TensorFlow MNIST,卷积神经网络、循环神经网络、无监督学习
MNIST 卷积神经网络.https://github.com/nlintz/TensorFlow-Tutorials/blob/master/05_convolutional_net.py .Ten ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- 自动编码(AE)器的简单实现
一.目录 自动编码(AE)器的简单实现 一.目录 二.自动编码器的发展简述 2.1 自动编码器(Auto-Encoders,AE) 2.2 降噪自编码(Denoising Auto-Encoders, ...
随机推荐
- .NET 构造DataTable返回多个json值
有时候我们使用Ajax链接一般处理程序需要返回多个值,然而这些数据并非在一个查询表内,此时便想到构造一个虚拟的DataTable,这样就可以返回多个值了(当然有很多办法,这是其中一种 ). 首先我们需 ...
- activitemq整合spring
activitemq整合spring 一.activmq的点对点模型 pom.xml: <?xml version="1.0" encoding="UTF-8&qu ...
- 关于 Nginx 配置 WebSocket 400 问题
今天把项目升级了 asp.net core 到 2.1 的版本,使用了 signalr 的功能,由于阿里云不支持 websocket 协议,所以使用了 nginx 代理方式来解决,后续就报了一个登陆 ...
- Spring Boot + Spring Cloud 构建微服务系统(九):配置中心(Spring Cloud Config)
技术背景 如今微服务架构盛行,在分布式系统中,项目日益庞大,子项目日益增多,每个项目都散落着各种配置文件,且随着服务的增加而不断增多.此时,往往某一个基础服务信息变更,都会导致一系列服务的更新和重启, ...
- Vue + Element UI 实现权限管理系统 前端篇(十三):页面权限控制
权限控制方案 既然是后台权限管理系统,当然少不了权限控制啦,至于权限控制,前端方面当然就是对页面资源的访问和操作控制啦. 前端资源权限主要又分为两个部分,即导航菜单的查看权限和页面增删改操作按钮的操作 ...
- 基于vue2.0实现仿百度前端分页效果(一)
前言 最近在接手一个后台管理项目的时候,由于之前是使用jquery+bootstrap做的,后端使用php yii框架,前后端耦合在一起,所以接手过来之后通过vue进行改造,但依然继续使用的boots ...
- SpringMVC源码阅读:过滤器
1.前言 SpringMVC是目前J2EE平台的主流Web框架,不熟悉的园友可以看SpringMVC源码阅读入门,它交代了SpringMVC的基础知识和源码阅读的技巧 本文将通过源码(基于Spring ...
- python的Web框架,auth权限系统
使用django默认权限系统实现用户登录退出 判断用户是否登录 request.user.is_authenticated 返回的为bool值 一个简单的登录视图范式: # 导包 from djang ...
- epoll的高效实现原理
epoll的高效实现原理 原文地址:http://blog.chinaunix.net/space.php?uid=26423908&do=blog&id=3058905 开发高性能网 ...
- stark组件之多级过滤
一.引子 在我们浏览很多页面时,会发现一般情况下都有一个分类的功能,而且还是多个类别同时控制,这就是多级过滤.如下图: 一行代表一个类别,第一行就是展示了所有的出版社,选中后就会以出版社分类,第二行就 ...