Hadoop学习笔记—9.Partitioner与自定义Partitioner
一、初步探索Partitioner
1.1 再次回顾Map阶段五大步骤
在第四篇博文《初识MapReduce》中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下图所示:
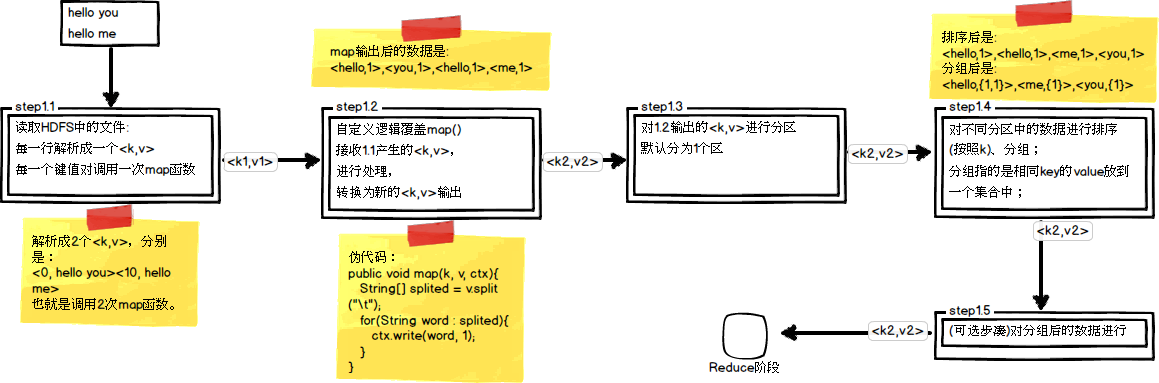
其中,step1.3就是一个分区操作。通过前面的学习我们知道Mapper最终处理的键值对<key, value>,是需要送到Reducer去合并的,合并的时候,有相同key的键/值对会送到同一个Reducer节点中进行归并。哪个key到哪个Reducer的分配过程,是由Partitioner规定的。在一些集群应用中,例如分布式缓存集群中,缓存的数据大多都是靠哈希函数来进行数据的均匀分布的,在Hadoop中也不例外。

1.2 Hadoop内置Partitioner
MapReduce的使用者通常会指定Reduce任务和Reduce任务输出文件的数量(R)。用户在中间key上使用分区函数来对数据进行分区,之后在输入到后续任务执行进程。一个默认的分区函数式使用hash方法(比如常见的:hash(key) mod R)进行分区。hash方法能够产生非常平衡的分区,鉴于此,Hadoop中自带了一个默认的分区类HashPartitioner,它继承了Partitioner类,提供了一个getPartition的方法,它的定义如下所示:
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
现在我们来看看HashPartitoner所做的事情,其关键代码就一句:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
这段代码实现的目的是将key均匀分布在Reduce Tasks上,例如:如果Key为Text的话,Text的hashcode方法跟String的基本一致,都是采用的Horner公式计算,得到一个int整数。但是,如果string太大的话这个int整数值可能会溢出变成负数,所以和整数的上限值Integer.MAX_VALUE(即0111111111111111)进行与运算,然后再对reduce任务个数取余,这样就可以让key均匀分布在reduce上。
二、自己定制Partitioner
大部分情况下,我们都会使用默认的分区函数HashPartitioner。但有时我们又有一些特殊的应用需求,所以我们需要定制Partitioner来完成我们的业务。这里以第五篇—自定义数据类型处理手机上网日志为例,来对其中的日志内容做一个特殊的分区:
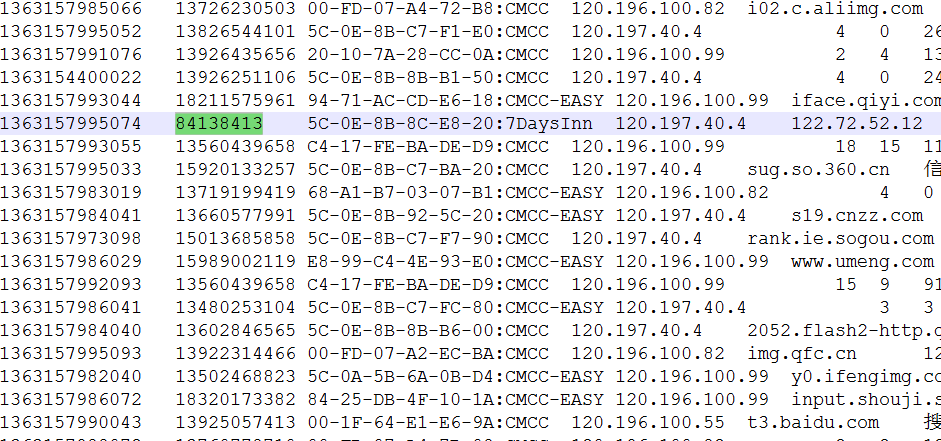
从上图中我们可以发现,在第二列上并不是所有的数据都是手机号(例如:84138413并不是一个手机号),我们任务就是在统计手机流量时,将手机号码和非手机号输出到不同的文件中。
2.1 自定义KpiPartitioner
/*
* 自定义Partitioner类
*/
public static class KpiPartitioner extends Partitioner<Text, KpiWritable> {
@Override
public int getPartition(Text key, KpiWritable value, int numPartitions) {
// 实现不同的长度不同的号码分配到不同的reduce task中
int numLength = key.toString().length();
if (numLength == 11) {
return 0;
} else {
return 1;
}
}
}
这里按手机和非手机号码的区分是按该字段的长度来划分,如果是11位则为手机号。接下来,就是重新修改run方法中的代码:设置为打包运行,设置Partitioner为KpiPartitioner,设置ReducerTask的个数为2;
public int run(String[] args) throws Exception {
// 首先删除输出目录已生成的文件
FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf());
Path outPath = new Path(OUTPUT_PATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 定义一个作业
Job job = new Job(getConf(), "MyKpiJob");
// 分区需要设置为打包运行
job.setJarByClass(MyKpiJob.class);
// 设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
// 设置自定义Mapper类
job.setMapperClass(MyMapper.class);
// 指定<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class);
// 设置Partitioner
job.setPartitionerClass(KpiPartitioner.class);
job.setNumReduceTasks(2);
// 设置Combiner
job.setCombinerClass(MyReducer.class);
// 设置自定义Reducer类
job.setReducerClass(MyReducer.class);
// 指定<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(KpiWritable.class);
// 设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
// 提交作业
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0;
}
注意:分区的例子必须要设置为打成jar包运行!
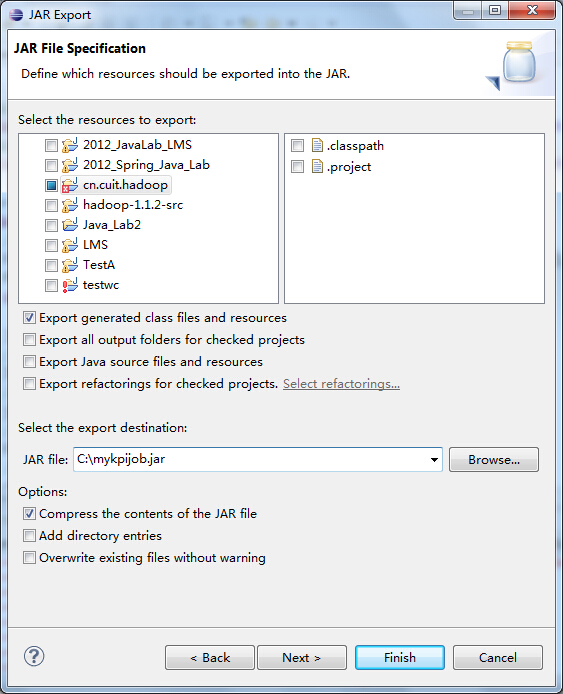
2.2 打成jar包并在Hadoop中运行
(1)通过Eclipse导出jar包
(2)通过FTP上传到Linux中,可以使用各种FTP工具,我一般使用XFtp。
(3)通过Hadoop Shell执行jar包中的程序

(4)查看执行结果文件:
首先是part-r-00000,它展示了手机号码的统计结果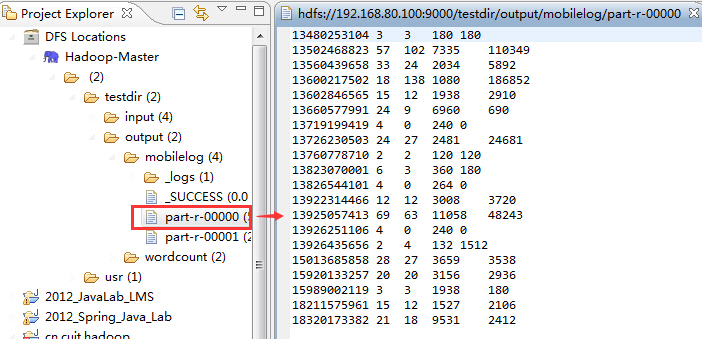
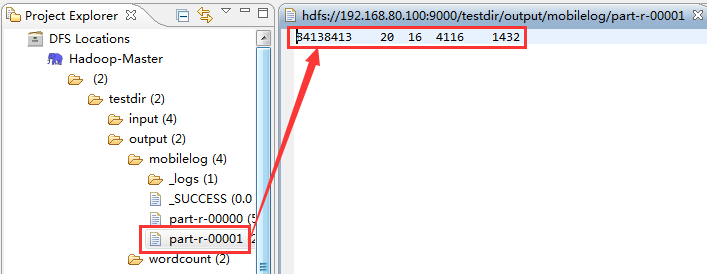
然后是part-r-00001,它展示了非手机号码的统计结果
(5)通过Web接口验证Partitioner的运行:通过访问http://hadoop-master:50030
①是否有2个Reduce任务?

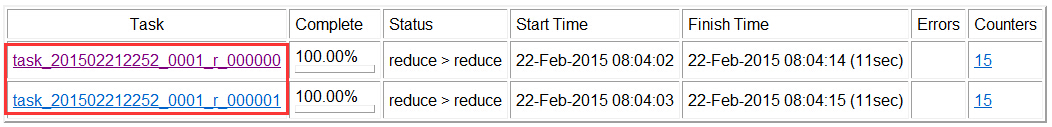
从图中可以看出,总共有2个Reduce任务;
②Reduce输出结果是否一致?
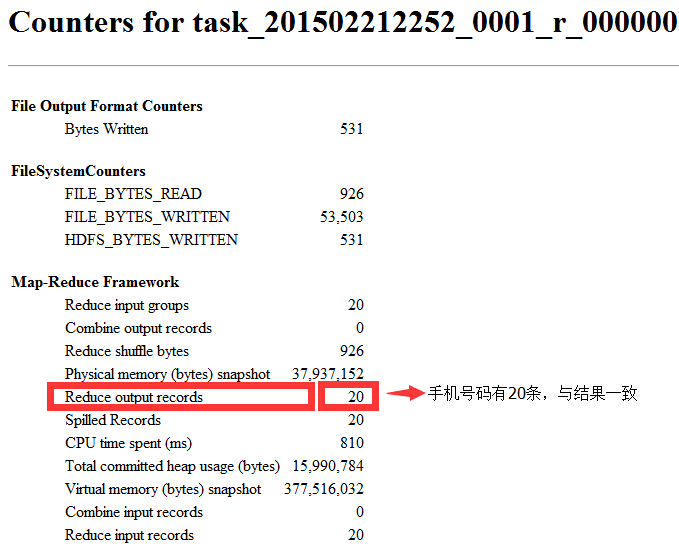
手机号码有20条记录,一致!
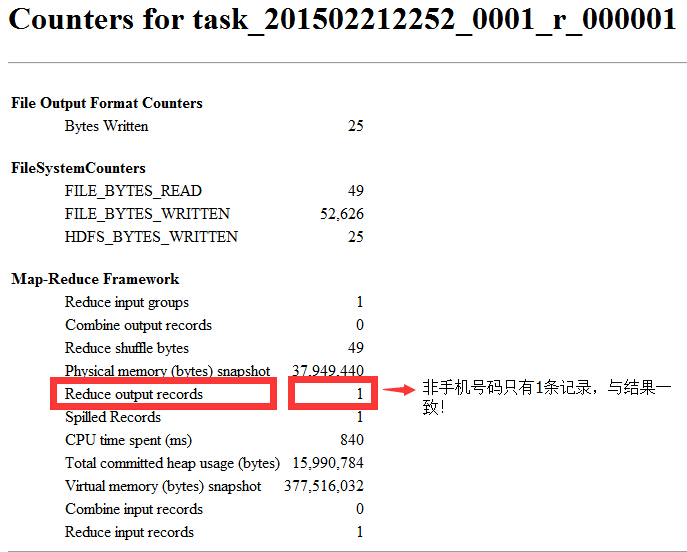
非手机号码只有1条记录,一致!
总结:分区Partitioner主要作用在于以下两点
(1)根据业务需要,产生多个输出文件;
(2)多个reduce任务并发运行,提高整体job的运行效率
参考资料
(1)吴超,《深入浅出Hadoop》:http://115.28.208.222/
(2)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
(3)Suddenly,《Hadoop日记Day17-分区》:http://www.cnblogs.com/sunddenly/p/4009568.html
(4)三劫散仙,《如何使用Hadoop中的Partitioner》:http://qindongliang.iteye.com/blog/2043136
Hadoop学习笔记—9.Partitioner与自定义Partitioner的更多相关文章
- Hadoop学习笔记—8.Combiner与自定义Combiner
一.Combiner的出现背景 1.1 回顾Map阶段五大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下图所示: ...
- Hadoop学习笔记—7.计数器与自定义计数器
一.Hadoop中的计数器 计数器:计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们通常可以在程序的某个位置插入计数器,用来记录数据或者进度的变化情况,它比日志更便利进行分析. ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
随机推荐
- C++ 系列:设计模式研究
Copyright © 1900-2016, NORYES, All Rights Reserved. http://www.cnblogs.com/noryes/ 欢迎转载,请保留此版权声明. -- ...
- [Javascript] 前端随笔
做一个小功能时使用到的一点技术点记录下来: 1.在js中使用定时器: 这两个方法都可以用来实现在一个固定时间段之后去执行JavaScript.不过两者各有各的应用场景. 方 法 实际上,setTime ...
- xamarin(3.9.236)里DATETIMENOW的错误。
[ERROR] FATAL UNHANDLED EXCEPTION: System.EntryPointNotFoundException: monodroid_get_system_property ...
- Jquery便利对象
xhr=[object object] $.each(xhr, function (key, val) { alert(key + '=' + val); ...
- 从零起步搭建Wordpress个人博客——Windows 平台篇(上)
本文以 Windows Server R2 64bit 标准版 为基础,其他windows版本可能会略有不同. 参考资料: https://codex.wordpress.org/Installing ...
- [算法总结]three-way partition
procedure three-way-partition(A : array of values, mid : value): i ← 0 j ← 0 n ← size of A - 1 while ...
- mongodb提示api-ms-win-crt-runtimel1-1-0.dll缺失的解决方案
mongodb提示api-ms-win-crt-runtimel1-1-0.dll缺失的解决方案 官方最新版的mongodb需要: VC++2015 RC x64的支持,否则会报出
- 如何解决插入Oracle数据中文为乱码问题
1.首先,Oracle查询编码:select * from v$nls_parameters;//看看是否GBK 2.如果是用Servlet或者别的,插入数据之前输出一下,看看是否乱码.比如: doP ...
- 由overflow-x:scroll产生的收获
我们都知道float:left属性会让元素向左浮动,如果用一个div将几个左浮动的li包起来,是不是div的宽度被li撑得很长很长呢,代码: <!DOCTYPE html> <htm ...
- swift 上手
学习swift的笔记,偶尔会更新一下 变量与常量 变量定义使用var,常量使用let,类型安全,有自动类型推导,注意赋值的=号两边必须有空格. 变量和常量名是可以几乎所有字符,这些都非常像javasc ...