Haproxy+Keepalived高可用配置
基本实验
参考文档
环境拓扑
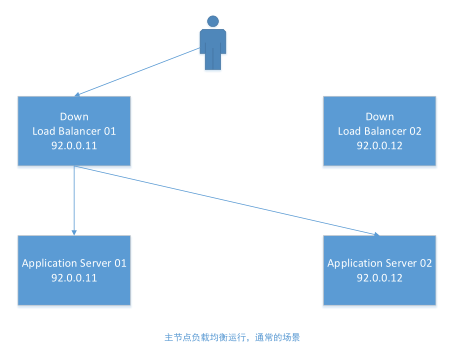
下面使我们要实现的负载均衡集群图示

- 主节点地址: 92.0.0.11
- 从节点地址: 92.0.0.12
- 共享虚拟地址:92.0.0.8
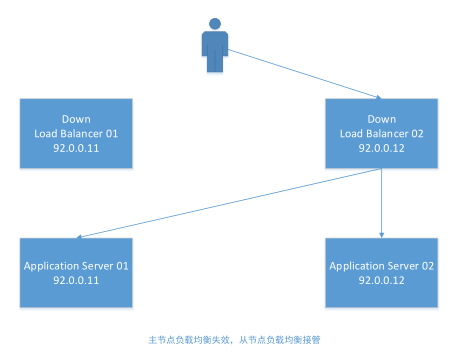
下面是负载均衡集群可能出现的两种场景(当主节点故障时,将从图1切换到图2)
Application服务可以部署到其他主机节点上,这边实验为了方便就部署到同一台上
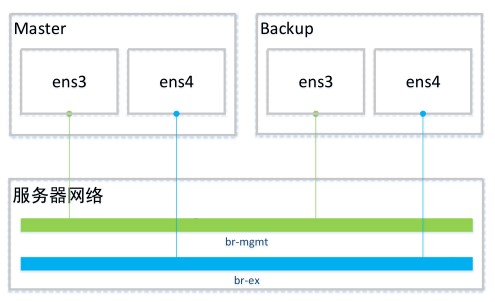
网络拓扑
br-mgmt:内网网桥(92.0.0.0/24)、br-ex:外网网桥(192.168.200.0/24)
环境搭建
安装软件
### 主/从节点都需安装
# yum install haproxy keepalived nginx -y
# systemctl start nginx
# systemctl enable nginx
HAProxy需要绑定非本机网络地址,所以需要修改
### 主/从节点都需修改
# vim /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1
### 让配置生效
# sysctl -p
编辑keepalived配置文件
# vim /etc/keepalived/keepalived.conf
主节点配置文件内容如下
# Script used to check if HAProxy is running
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
# Virtual interface
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_01 {
state MASTER
interface ens3
virtual_router_id 51
priority 101
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
92.0.0.8
}
track_script {
check_haproxy
}
}
从节点配置文件内容如下
# Script used to check if HAProxy is running
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
# Virtual interface
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_01 {
state BACKUP
interface ens3
virtual_router_id 51
priority 80
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
92.0.0.8
}
track_script {
check_haproxy
}
}
启动keepalived服务
# systemctl start keepalived
# systemctl enable keepalived
编辑haproxy配置文件
# vim /etc/haproxy/haproxy.cfg
global #全局设置
log 127.0.0.1 local0 #日志输出配置,所有日志都记录在本机,通过local0输出
maxconn 4096 #最大连接数
group haproxy #用户组
daemon #后台运行haproxy
nbproc 1 #启动1个haproxy实例
pidfile /usr/local/haproxy/haproxy.pid #将所有进程PID写入pid文件
defaults #默认设置
#log global
log 127.0.0.1 local3 #日志文件的输出定向
#默认的模式:tcp|http|health
mode http #所处理的类别,默认采用http模式
option httplog #日志类别,采用http日志格式`
option dontlognull
option forwardfor #将客户端真实ip加到HTTP Header中供后端服务器读取
option httpclose #每次请求完毕后主动关闭http通道,haproxy不支持keep-alive,只>能模拟这种模式的实现
retries 3 #3次连接失败就认为服务器不可用,主要通过后面的check检查
option redispatch #当serverid对应的服务器挂掉后,强制定向到其他健康服务器
option abortonclose #当服务器负载很高时,自动结束掉当前队列中处理比较久的链接
maxconn 2000 #默认最大连接数
timeout connect 5000 #连接超时时间
timeout client 50000 #客户端连接超时时间
timeout server 50000 #服务器端连接超时时间
listen am_cluster 92.0.0.8:8080
server s1 92.0.0.11:80 check
server s2 92.0.0.12:80 check
启动haproxy服务
# systemctl start haproxy
# systemctl enable haproxy
查看节点网络
### Master节点
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:21:07:87 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.11/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet 92.0.0.8/32 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe21:787/64 scope link
valid_lft forever preferred_lft forever
### Backup节点
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:64:ca:a7 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.12/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe64:caa7/64 scope link
valid_lft forever preferred_lft forever
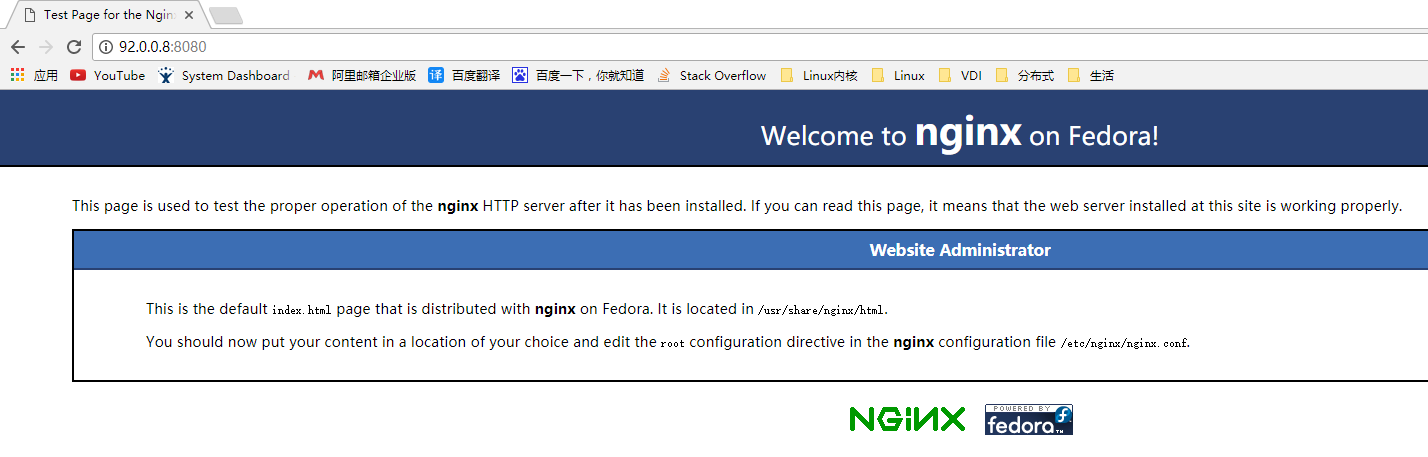
环境测试
正常访问
关闭Master节点的Keepalived,并刷新页面
### Master节点
# systemctl stop keepalived
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:21:07:87 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.11/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe21:787/64 scope link
valid_lft forever preferred_lft forever
### Backup节点
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:64:ca:a7 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.12/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet 92.0.0.8/32 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe64:caa7/64 scope link
valid_lft forever preferred_lft forever
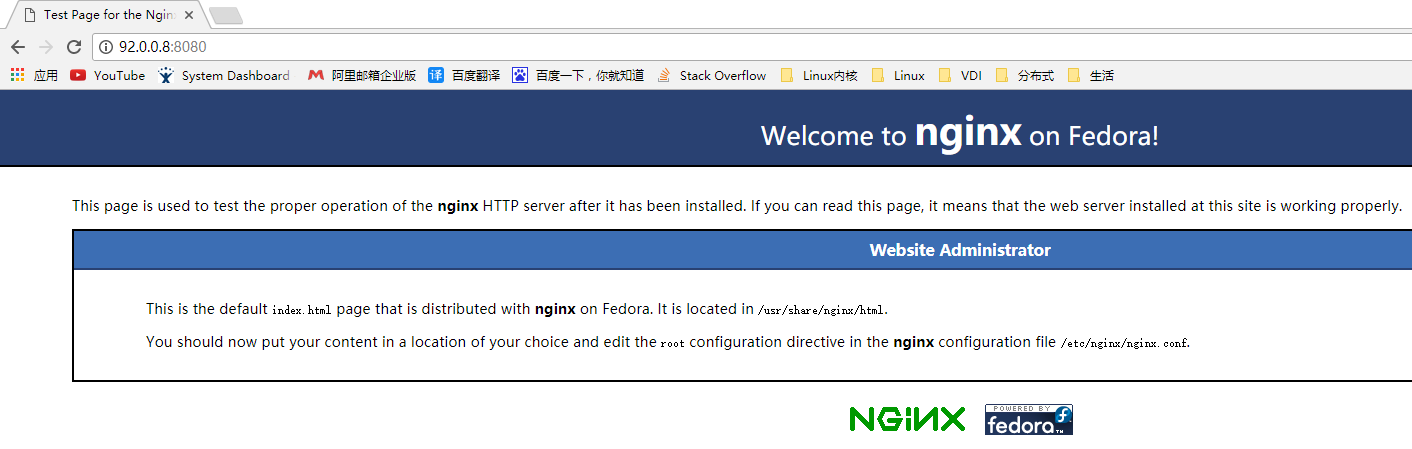
关闭Backup节点的Haproxy,并刷新页面
### Backup节点
# systemctl stop haproxy
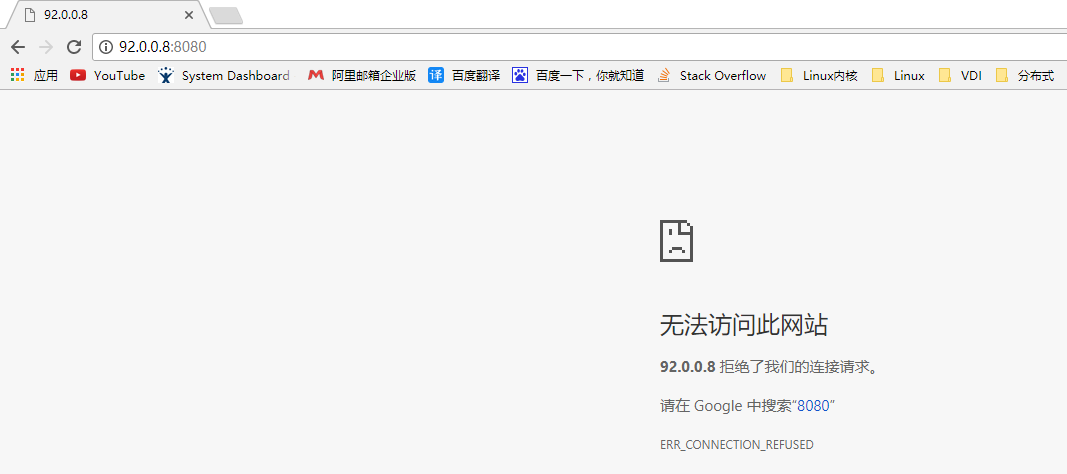
恢复Master节点的keepalived,并刷新页面
### Master节点
# systemctl start keepalived
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:21:07:87 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.11/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet 92.0.0.8/32 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe21:787/64 scope link
valid_lft forever preferred_lft forever
### Backup节点
# ip addr show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:64:ca:a7 brd ff:ff:ff:ff:ff:ff
inet 92.0.0.12/24 brd 92.0.0.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe64:caa7/64 scope link
valid_lft forever preferred_lft forever
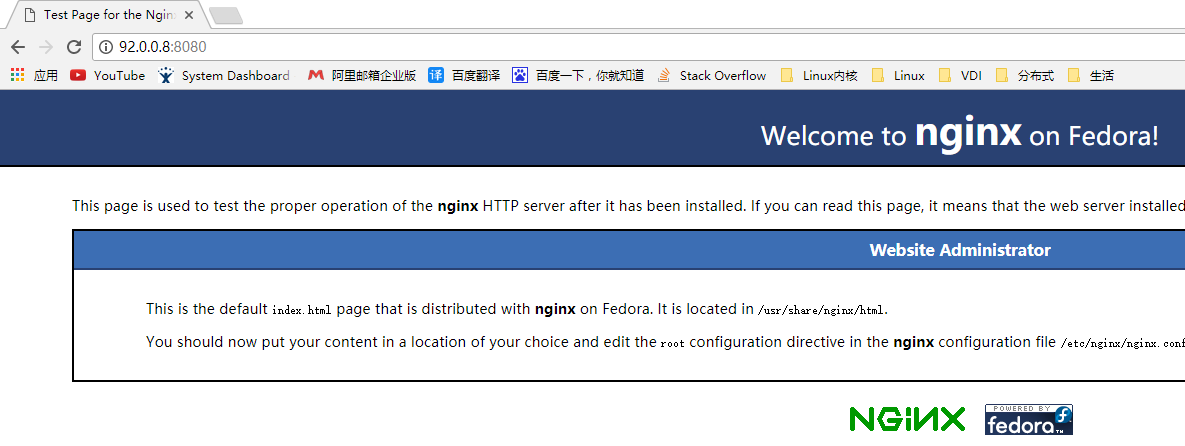
总结
- keepalived在Master节点故障时,VIP会自动迁移到Slave节点,并在Master节点恢复后自动迁回(VIP抢占模式)
- keepalived和haproxy只有在同一台节点才能正常工作,即Master节点的keepalived挂了,Slave节点的haproxy节点挂了,是无法正常工作的,原因未知~
Kolla实验
修改配置文件
### keepalived和haproxy都要安装到所有controller节点(准备3台host作为controller节点)
# vim multinode
[haproxy:children]
controller
# vim /usr/share/kolla-ansible/ansible/roles/haproxy/templates/keepalived.conf.j2
vrrp_script check_alive {
script "/check_alive.sh"
interval 2
fall 2
rise 10
}
vrrp_instance kolla_internal_vip_{{ keepalived_virtual_router_id }} {
{% if inventory_hostname == groups['controller'][0] %}
state MASTER
{% else %}
state BACKUP
{% endif %}
nopreempt
interface {{ api_interface }}
virtual_router_id {{ keepalived_virtual_router_id }}
{% if inventory_hostname == groups['controller'][0] %}
priority 100
{% else %}
priority {{ groups['haproxy'].index(inventory_hostname) }}
{% endif %}
advert_int 1
virtual_ipaddress {
{{ kolla_internal_vip_address }} dev {{ api_interface }}
{% if haproxy_enable_external_vip | bool %}
{{ kolla_external_vip_address }} dev {{ kolla_external_vip_interface }}
{% endif %}
}
{% if haproxy_enable_external_vip | bool and api_interface != kolla_external_vip_interface %}
track_interface {
{{ kolla_external_vip_interface }}
}
{% endif %}
authentication {
auth_type PASS
auth_pass {{ keepalived_password }}
}
track_script {
check_alive
}
}
### 部署OpenStack
# kolla-ansible -i multinode deploy
测试HA
直接关闭一台非network节点的controller不会影响OpenStack功能使用
Haproxy+Keepalived高可用配置的更多相关文章
- RabbitMQ集群安装配置+HAproxy+Keepalived高可用
RabbitMQ集群安装配置+HAproxy+Keepalived高可用 转自:https://www.linuxidc.com/Linux/2016-10/136492.htm rabbitmq 集 ...
- 案例一(haproxy+keepalived高可用负载均衡系统)【转】
1.搭建环境描述: 操作系统: [root@HA-1 ~]# cat /etc/redhat-release CentOS release 6.7 (Final) 地址规划: 主机名 IP地址 集群角 ...
- [Z]haproxy+keepalived高可用群集
http://blog.51cto.com/13555423/2067131 Haproxy是目前比较流行的一种集群调度工具Haproxy 与LVS.Nginx的比较LVS性能最好,但是搭建相对复杂N ...
- Haproxy+keepalived高可用集群实战
1.1 Haproxy+keepalived高可用集群实战 随着互联网火热的发展,开源负载均衡器的大量的应用,企业主流软件负载均衡如LVS.Haproxy.Nginx等,各方面性能不亚于硬件负载均衡 ...
- rabbitmq+haproxy+keepalived高可用集群环境搭建
1.先安装centos扩展源: # yum -y install epel-release 2.安装erlang运行环境以及rabbitmq # yum install erlang ... # yu ...
- HAProxy+Keepalived 高可用负载均衡
转自 https://www.jianshu.com/p/95cc6e875456 Keepalived+haproxy实现高可用负载均衡 Master backup vip(虚拟IP) 192.16 ...
- 18-基于CentOS7搭建RabbitMQ3.10.7集群镜像队列+HaProxy+Keepalived高可用架构
集群架构 虚拟机规划 IP hostname 节点说明 端口 控制台地址 192.168.247.150 rabbitmq.master rabbitmq master 5672 http://192 ...
- Haproxy+Keepalived高可用负载均衡详细配置
本文所使用的环境: 10.6.2.128 centos6.5 10.6.2.129 centos6.5 VIP 为10.6.2.150 要实现的目标: 实现10.6.2.128和10.6 ...
- Haproxy+Keepalived高可用环境部署梳理(主主和主从模式)
Nginx.LVS.HAProxy 是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,通常会结合Keepalive做健康检查,实现故障转移的高可用功能. 1)在四层(tcp)实现负载均衡的 ...
随机推荐
- Spark- 流量日志分析
日志生成 package zx.Utils import java.io.{File, FileWriter} import java.util.Calendar import org.apache. ...
- 重置 oschina 的CSS
嗯, 目前只是改了一下OSChina的几个主要DIV宽度而以,还是很粗糙, 以后会慢慢改进的. ---------------------------------------------------- ...
- jQuery应用之eraser.js使用,实现擦除、刮刮卡效果
jquery.eraser是一款使用鼠标或触摸的动作来擦除画布显示真正图片的插件.jquery.eraser插件的原理是用一个画布遮住图片,然后根据触摸或鼠标输入来擦除画布显示图片,您可以在参数中指定 ...
- linux没有eth0
1.创建ifcfg-eth0 touch /etc/sysconfig/network-scripts/ifcfg-eth0 2.配置ifcfg-eth0 DEVICE=eth0 HWADDR=:0c ...
- vue2.0项目实战使用axios发送请求
在Vue1.0的时候有一个官方推荐的 ajax 插件 vue-resource,但是自从 Vue 更新到 2.0 之后,官方就不再更新 vue-resource. 关于为什么放弃推荐? -> 尤 ...
- Oracle学习笔记_01_SQL初步
1.分类 SQL语句分为以下三种类型: DML: Data Manipulation Language 数据操纵语言 DDL: Data Definition Languag ...
- PHP 使用header函数设置HTTP头的示例解析 表头
PHP 使用header函数设置HTTP头的示例解析 表头 //定义编码 header( 'Content-Type:text/html;charset=utf-8 '); //Atom header ...
- Linux-MySQL主从配置
1. MySQL主从原理以及应用场景MySQL的Replication原理非常简单,总结一下:每个从仅可以设置一个主.主在执行sql之后,记录二进制log文件(bin-log).从连接主,并从主获取b ...
- 一个类的类类型是Class类的实例,即类的字节码
new 是静态加载类,编译时期加载.一遍功能性的类 需要动态加载
- 如何生成HLS协议的M3U8文件
什么是HLS协议: HLS(Http Live Streaming)是由Apple公司定义的用于实时流传输的协议,HLS基于HTTP协议实现,传输内容包括两部分,一是M3U8描述文件,二是TS媒体文件 ...