python学习3(转载)
主要内容:
列表 和 元组和字典
列表
一、列表介绍
列表是一种能存储大量数据的数据结构,是能装对象的对象。由方括号 [] 括起来,能放任意类型的数据,数据之间用逗号隔开
列表存储数据是有顺序的
二、增删改查
lis = []
1、增加 (三种)
lis.append() 在末尾追加,一次只能加一个
lis.insert(index, 元素) 在指定位置插入元素,这种方法由于会改变列表中其他索引,“牵一发而动全身”,所以运行效率会低一些
lis.extend(可迭代对象) 迭代添加
2、删除
lis.pop() “弹出一个” 删除末尾的元素,并返回删除的元素值,也可以指定索引删除指定元素(通过索引删除)
lis.remove(元素) 移除一个某个元素(通过值删除元素)
lis.clear() 清空列表
切片删除
del lis[1:3] # 删除索引是1,2的元素
索引切片修改
# 修改
lst = ["太白", "太", "五", "银王", "日天"]
lst[1] = "太污" # 把1号元素修改成太污
print(lst)
lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步长不是1, 要注意. 元素的个数
print(lst)
lst[1:4] = ["李嘉诚很厉害"] # 如果切片没有步长或者步长是1. 则不用关心个数
print(lst)
结果:
['太白', '太污', '五', '银王', '日天']
['太白', '麻花藤', '五', '哇靠', '日天']
['太白', '李嘉诚很厉害', '日天']
3、修改
只能根据索引值修改
即
lis[index] = " new"
4、查询
、根据索引和切片查找某个或某些元素
lis = ["列","表","与","元组"]
# 循环输出列表中元素
for c in lis :
print(c) # 代表列表中每个元素
# 循环输列表中元素 带索引
for n in rang(len(lis)):
print(n, lis[n])
、列表循环遍历
三、列表常用功能
lis.count(元素) 统计某个元素在列表出现次数
lis.index(元素) 返回元素的索引 没有时报错 ValueError: 5 is not in list
lis.sort() 列表排序,对于纯数字元素的列表,从小到大排序(升序)
lis.sort(reverse = True) 从大到小排序(逆序)
注意: 字符串不要用这个方法排序,不是不能排,而是用这个方法排完也没有什么价值,因为用的是默认的字符串比较大小的方式
"xxx".join(lis) 用"xxx"将列表元素连成字符串, 和split()功能相反 两个可以一起记
四、列表嵌套
想要找某个元素是,用降维的方法,一层一层的找,一定要注意每一层对应的是什么数据
元组
元组由括号()括起来。可以存任意类型数据
元组是不可变数据类型,所以,增删改查中只有查能进行,所以也被称为“只读列表”
对元组不可变性的理解:
它的不可变性体现在元组在创建时第一层元素的内存地址就是固定的了,所以如果元素是不可变数据类型,比如字符串,那么是无法对其有修改操作的,但如果元素是可变数据类型,比如列表,是可以对其进行一些修改操作的。参考图解
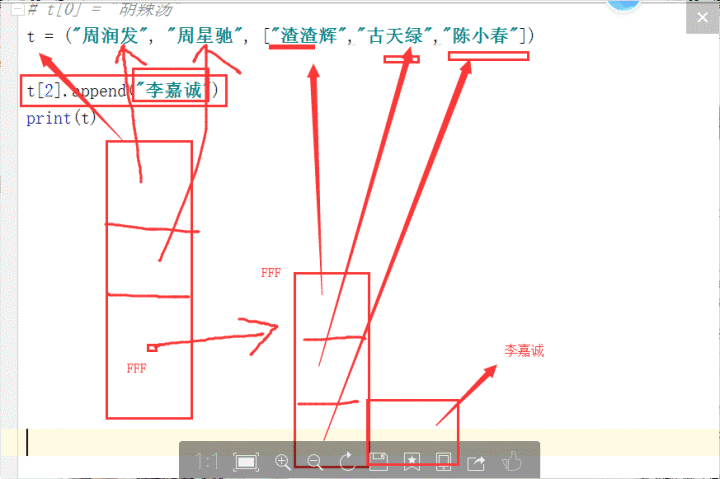
注意坑:元组如果只有一个元素,要加逗号,不然会将括号算作运算符
t1 = (2)
t2 = (2,)
t3 = (1,2,3,)
print(t1) # 2
print(type(t1)) #<class 'int'>
print(t2) #(2,)
print(type(t2)) #<class 'tuple'>
print(t3) #(1,2,3)
print(type(t3) #<class 'tuple'>
code
常用操作:
t = (1,2,2,4,5,"张")
t.index() 查找指定索引元素 元素不存在时报错 ValueError: tuple.index(x): x not in tuple
t.count() 统计某个元素出现次数
补充知识:
range()函数
range(n) 遍历[0,n)的元素
range(m,n) 遍历[m,n)的元素
range(m,n,p) 从m到n, 每隔p个取一个 p为负数可以倒序遍历 如range(100,0,-1) 遍历[100,0)的元素
列表删除
切片删除
del lis[1:3] # 删除索引是1,2的元素
修改

索引切片修改
# 修改
lst = ["太白", "太", "五", "银王", "日天"]
lst[1] = "太污" # 把1号元素修改成太污
print(lst)
lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步长不是1, 要注意. 元素的个数
print(lst)
lst[1:4] = ["李嘉诚个⻳⼉⼦"] # 如果切片没有步长或者步长是1. 则不用关心个数
print(lst)
字典
字典由花括号表示{ },元素是key:value的键值对,元素之间用逗号隔开
特点:1、字典中key是不能重复的 且是不可变的数据类型,因为字典是使用hash算法来计算key的哈希值,然后用哈希值来存储键值对数据
2、字典中元素是无序的
3、value值可以是任意类型的数据
注:字典中的key是可hash的,可hash的数据的都是不可变的数据类型
已知的可哈希(不可变)的数据类型: int, str, tuple(元组), bool
不可哈希(可变)的数据类型: list(列表), dict(字典), set(集合)
增删改查
创建一个空字典---两种方式:
dic ={}
dic = dict()
新增(两种方式)
dic[key] = value # 可以新增也可修改已有key的value值
dic.setdefault(key, value) # 如果key是没有的,新增;如果key已存在 保持原值(这个方法是分两步的 在查询会细说)
删除(四种方式)
pop(key) # 必须指定一个key 删除指定元素
popitems( ) # 随机删除一个值(字典是无序的) 但是在3.6版本里效果是删除字典最后一个元素--->原因 3.5之前字典打印输出是无序的,但在3.6之后字典打印输出是按照元素添 加的顺序的,所以感觉用这个方法时是删除的最后一个元素,但是这个方法的源码里还是随机删除的
del dic[key] # 删除指定元素
dic.clear() # 清空字典
修改(两种)
dic[key] = new value #赋一个新值
dic.update(dic2) #将dic2更新到dic中
查询(三种)
dic[key] #查询指定元素 key不存在时报错
dic.get(key,[xxx]) # 查询key的value key不存在时返回xxx,如果不写xxx,默认返回None
dic.setdefault(key,[value]) # 执行逻辑 第一步,看key是否存在,key存在, 不添加也不修改value;不存在,添加key:value键值对,value没有时默认为None
第二步,返回key对应的value值
常用操作
dic.keys() 返回所有的键 返回的是一个可迭代对象,形式像列表但又不是列表
1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.keys()) #dict_keys(['意大利', '意大利2', '美国', '美国电视剧'])
4
5 for k in dic.keys(): # 可以迭代。 拿到的是每一个key
6 print(k)
dic.values() 返回所有的值
dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
print(dic.values()) #dict_values(['西西里的美丽传说', '天堂电影院', '美国往事', '越狱'])
for value in dic.values():
print(value)
dic.items() 返回所有的键值对
1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.items()) #dict_items([('意大利', '西西里的美丽传说'), ('意大利2', '天堂电影院'), ('美国', '美国往事'), ('美国电视剧', '越狱')])
4 for k ,v in dic.items():
5 print(k ,v)
6
7 #遍历字典最好的方案
8 for k, v in dic.items(): # 拿到的是元组(key, value) 这是解包操作
9 print(k,v) #直接拿到key和value
python学习3(转载)的更多相关文章
- python学习目录(转载)
python基础篇 python 基础知识 python 初始python python 字符编码 python 类型及变量 python 字符串详解 python 列表详解 ...
- 《Python学习手册》读书笔记【转载】
转载:http://www.cnblogs.com/wuyuegb2312/archive/2013/02/26/2910908.html 之前为了编写一个svm分词的程序而简单学了下Python,觉 ...
- 转载-《Python学习手册》读书笔记
转载-<Python学习手册>读书笔记 http://www.cnblogs.com/wuyuegb2312/archive/2013/02/26/2910908.html
- Python学习资源汇总,转载自他人
python3英文视频教程(全87集) http://pan.baidu.com/s/1dDnGBvV python从入门到精通视频(全60集)链接:http://pan.baidu.com/s/1e ...
- Python 学习 第十篇 CMDB用户权限管理
Python 学习 第十篇 CMDB用户权限管理 2016-10-10 16:29:17 标签: python 版权声明:原创作品,谢绝转载!否则将追究法律责任. 不管是什么系统,用户权限都是至关重要 ...
- OpenCV之Python学习笔记
OpenCV之Python学习笔记 直都在用Python+OpenCV做一些算法的原型.本来想留下发布一些文章的,可是整理一下就有点无奈了,都是写零散不成系统的小片段.现在看 到一本国外的新书< ...
- 《Python学习手册》读书笔记
之前为了编写一个svm分词的程序而简单学了下Python,觉得Python很好用,想深入并系统学习一下,了解一些机制,因此开始阅读<Python学习手册(第三版)>.如果只是想快速入门,我 ...
- python学习笔记(五岁以下儿童)深深浅浅的副本复印件,文件和文件夹
python学习笔记(五岁以下儿童) 深拷贝-浅拷贝 浅拷贝就是对引用的拷贝(仅仅拷贝父对象) 深拷贝就是对对象的资源拷贝 普通的复制,仅仅是添加了一个指向同一个地址空间的"标签" ...
- Python学习路线图
文章转载自「开发者圆桌」一个关于开发者入门.进阶.踩坑的微信公众号 Python学习路线图你可以通过百度云盘下载观看对应的视频 链接: http://pan.baidu.com/s/1c2zLllA ...
- Python学习一:序列基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7858473.html 邮箱:moyi@moyib ...
随机推荐
- 关于MySQL隐式转换
一.如果表定义的是varchar字段,传入的是数字,则会发生隐式转换. 1.表DDL 2.传int的sql 3.传字符串的sql 仔细看下表结构,rid的字段类型: 而用户传入的是int,这里会有一个 ...
- 算法Sedgewick第四版-第1章基础-2.3 Quicksort-001快速排序
一. 1.特点 (1)The quicksort algorithm’s desirable features are that it is in-place (uses only a small a ...
- 数据结构_相似三角形优雅值_sjx
问题描述 给你 n 个三角形,每个三角形有一个优雅值,然后给出一个询问,每次询问一个三角形,求与询问的三角形,相似的三角形中的优雅值最大是多少. ★数据输入第一行输入包括 n 一个数字,接下来 n 行 ...
- Netty学习大纲
1.BIO.NIO和AIO2.Netty 的各大组件3.Netty的线程模型4.TCP 粘包/拆包的原因及解决方法5.了解哪几种序列化协议?包括使用场景和如何去选择6.Netty的零拷贝实现7.Net ...
- python 常用的一些库
AllPairs 2.0.1Appium-Python-Client 0.24asn1crypto 0.24.0attrs 17.4.0AutoItLibrary 1.1bcrypt 3.1.4bea ...
- HTML5游戏开发 PDF扫描版
很多从事Web前端开发的人对HTML总有些不满,比如需要手动检查和设计很多格式代码,不仅容易出错,而且存在大量重复.好在HTML5让我们看到了曙光.作为下一代Web开发标准,HTML5成为主流的日子已 ...
- sql 试图索引
视图是对数据(一种元数据类型)的一种描述.当创建了一个典型视图时,通过封装一个 SELECT 语句(定义一个结果集来表示为虚拟表)来定义元数据.当在另一个查询的 FROM 子句中引用视图时,将从系统目 ...
- 关于redis-windows环境下的一些配置:
如果报错: The Windows version of Redis allocates a memory mapped heap for sharing with the forked proces ...
- javascript 取掉空格自定义函数
js 取掉空格自定义函数 //取掉左右空格: function trim(str){ return str.replace(/(^\s*)|(\s*$)/g, ""); } // ...
- PS2018学习笔记(03-18节)
3-认识主界面 # 主界面包括: 菜单栏.选项栏.工具栏.面板.图像编辑窗口(中间)和状态栏(底部): # 界面设置: 方法1:Ctrl+k:打开界面设置; 方法2:编辑-首选项-界面 # shift ...