1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的,
环境准备:
pip install lxml
pip install bs4
pip install urllib
#!/usr/bin/env python
#-*- coding: utf-8 -*- import requests
from bs4 import BeautifulSoup
import os
import urllib
import random class mzitu(): def all_url(self, url):
html = self.request(url)
all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text()
print(u'开始保存:', title)
title = title.replace(':', '')
path = str(title).replace("?", '_')
if not self.mkdir(path): ##跳过已存在的文件夹
print(u'已经跳过:', title)
continue
href = a['href']
self.html(href) def html(self, href):
html = self.request(href)
max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='pagenavi').find_all('span')[-2].get_text()
for page in range(1, int(max_span) + 1):
page_url = href + '/' + str(page)
self.img(page_url) def img(self, page_url):
img_html = self.request(page_url)
img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src']
self.save(img_url, page_url) def save(self, img_url, page_url):
name = img_url[-9:-4]
try:
img = self.requestpic(img_url, page_url)
f = open(name + '.jpg', 'ab')
f.write(img.content)
f.close()
except FileNotFoundError: ##捕获异常,继续往下走
print(u'图片不存在已跳过:', img_url)
return False def mkdir(self, path): ##这个函数创建文件夹
path = path.strip()
isExists = os.path.exists(os.path.join("D:\mzitu", path))
if not isExists:
print(u'建了一个名字叫做', path, u'的文件夹!')
path = path.replace(':','')
os.makedirs(os.path.join("D:\mzitu", path))
os.chdir(os.path.join("D:\mzitu", path)) ##切换到目录
return True
else:
print(u'名字叫做', path, u'的文件夹已经存在了!')
return False def requestpic(self, url, Referer): ##这个函数获取网页的response 然后返回
user_agent_list = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
65-1 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
ua = random.choice(user_agent_list)
headers = {'User-Agent': ua, "Referer": Referer} ##较之前版本获取图片关键参数在这里
content = requests.get(url, headers=headers)
return content def request(self, url): ##这个函数获取网页的response 然后返回
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
content = requests.get(url, headers=headers)
return content Mzitu = mzitu() ##实例化
Mzitu.all_url('http://www.mzitu.com/all/') ##给函数all_url传入参数 你可以当作启动爬虫(就是入口)
print(u'恭喜您下载完成啦!')
执行步骤:
重复执行代码的话已保存的不会再次下载保存
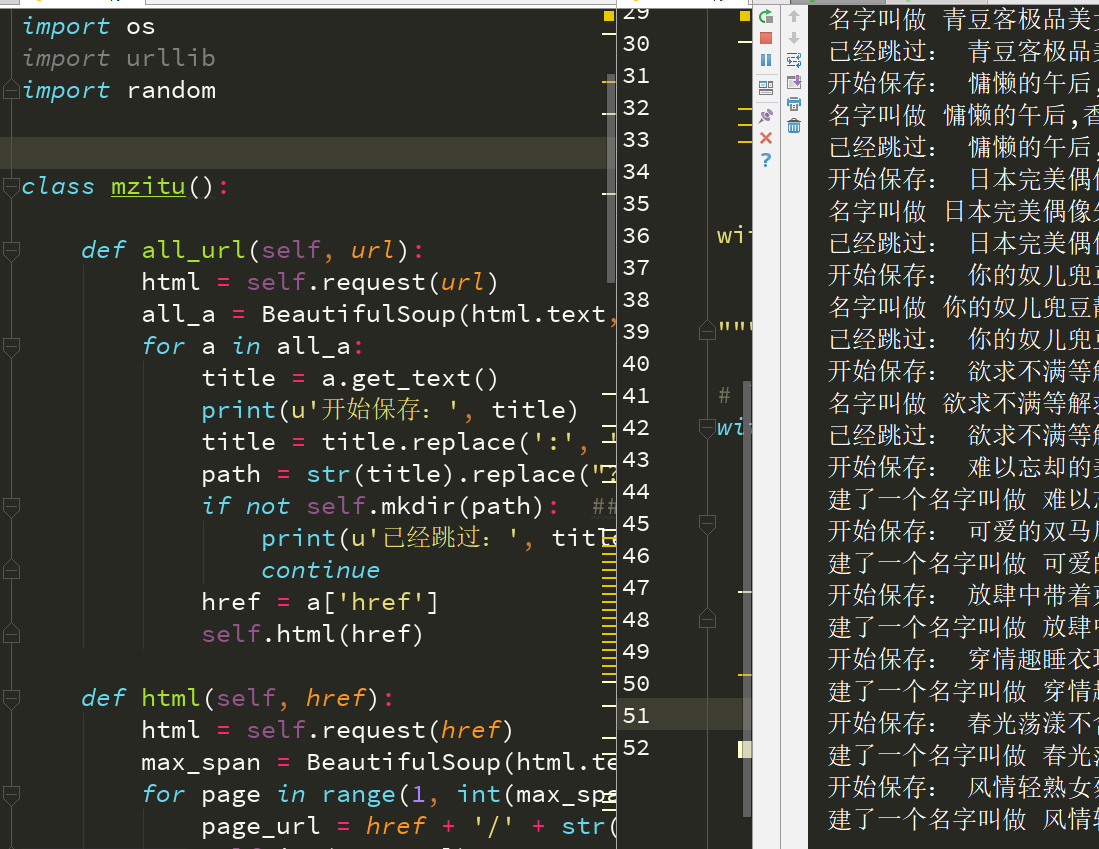
执行结果:
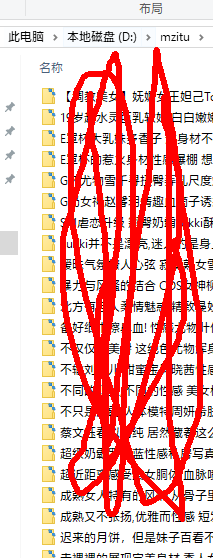
遇到的错误如何解决:
1、错误提示:requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:访问量瞬间过大,被网站反爬机制拦截了
解决方法:稍等一段时间再次执行即可
2、requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:可能对方服务器做了反爬
解决方法:requests手动添加一下header


1、使用Python3爬取美女图片-网站中的每日更新一栏的更多相关文章
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- android高仿抖音、点餐界面、天气项目、自定义view指示、爬取美女图片等源码
Android精选源码 一个爬取美女图片的app Android高仿抖音 android一个可以上拉下滑的Ui效果 android用shape方式实现样式源码 一款Android上的新浪微博第三方轻量 ...
- Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据 众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD ...
- Python3爬取美女妹子图片转载
# -*- coding: utf-8 -*- """ Created on Sun Dec 30 15:38:25 2018 @author: 球球 "&qu ...
随机推荐
- 服务器重启后启动Docker命令
启动步骤: 1.启动Docker 守护进程 systemctl daemon-reload 2.Docker启动命令: systemctl start docker 3.查看docker服务是否启动 ...
- [SharePoint2010开发入门经典]9创建更好的用户体验----silverlight
本章概要: 1.了解Silverlight 2.理解为什么使用Silverlight 3.介绍如何集成SharePoint和Silverlight
- 重定向标准输出到socket的方法
- [HTML 5] Atomic Relevant Busy
Together 'aria-live', we can use 'aria-atomic', 'aria-relevant' and 'aria-busy' to give more informa ...
- 使用UE4公布安卓平台游戏
使用了几天的UE4 ,总算是将游戏在安卓平台执行起来了.当中遇到非常多问题,而且终于依旧有一些问题没能解决. 整体感觉是UE4这款引擎眼下还不够成熟.问题较多. 没有unity使用起来方便. 可是既然 ...
- python 并发编程入门
多进程 在Unix/Linux下,为我们提供了类似c中<unistd.h>头文件里的的fork()函数的接口,这个函数位于os模块中,相同与c中类似,对于父进程fork()调用返回子进程I ...
- HIbernate中openSession和getCurrentSession
这两者的差别网上非常多资源,我这里就copy一下了,然后有点问题的是今天遇到的问题. openSession和getCurrentSession的根本差别在于有没有绑定当前线程,所以,用法有差 ...
- cocos2dx3.2 android平台搭建开发环境纠错备忘录
平台:win32 + android cocos2d版本号:3.2 搭建cocos2d-x android 常见问题: 问题1: Android platform not specified, sea ...
- xcodeproj cannot be opened because the project file cannot be parsed.
解决方法: 1.对.xcodeproj文件右键,显示包内容 2.双击打开 project.pbxproj 文件 3.找到以上类似的冲突信息(能够用commad + f搜索) 4.删除<&l ...
- comp.lang.javascript FAQ [zz]
comp.lang.javascript FAQ Version 32.2, Updated 2010-10-08, by Garrett Smith FAQ Notes 1 Meta-FAQ met ...