1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的,
环境准备:
pip install lxml
pip install bs4
pip install urllib
#!/usr/bin/env python
#-*- coding: utf-8 -*- import requests
from bs4 import BeautifulSoup
import os
import urllib
import random class mzitu(): def all_url(self, url):
html = self.request(url)
all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text()
print(u'开始保存:', title)
title = title.replace(':', '')
path = str(title).replace("?", '_')
if not self.mkdir(path): ##跳过已存在的文件夹
print(u'已经跳过:', title)
continue
href = a['href']
self.html(href) def html(self, href):
html = self.request(href)
max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='pagenavi').find_all('span')[-2].get_text()
for page in range(1, int(max_span) + 1):
page_url = href + '/' + str(page)
self.img(page_url) def img(self, page_url):
img_html = self.request(page_url)
img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src']
self.save(img_url, page_url) def save(self, img_url, page_url):
name = img_url[-9:-4]
try:
img = self.requestpic(img_url, page_url)
f = open(name + '.jpg', 'ab')
f.write(img.content)
f.close()
except FileNotFoundError: ##捕获异常,继续往下走
print(u'图片不存在已跳过:', img_url)
return False def mkdir(self, path): ##这个函数创建文件夹
path = path.strip()
isExists = os.path.exists(os.path.join("D:\mzitu", path))
if not isExists:
print(u'建了一个名字叫做', path, u'的文件夹!')
path = path.replace(':','')
os.makedirs(os.path.join("D:\mzitu", path))
os.chdir(os.path.join("D:\mzitu", path)) ##切换到目录
return True
else:
print(u'名字叫做', path, u'的文件夹已经存在了!')
return False def requestpic(self, url, Referer): ##这个函数获取网页的response 然后返回
user_agent_list = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
65-1 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
ua = random.choice(user_agent_list)
headers = {'User-Agent': ua, "Referer": Referer} ##较之前版本获取图片关键参数在这里
content = requests.get(url, headers=headers)
return content def request(self, url): ##这个函数获取网页的response 然后返回
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
content = requests.get(url, headers=headers)
return content Mzitu = mzitu() ##实例化
Mzitu.all_url('http://www.mzitu.com/all/') ##给函数all_url传入参数 你可以当作启动爬虫(就是入口)
print(u'恭喜您下载完成啦!')
执行步骤:
重复执行代码的话已保存的不会再次下载保存
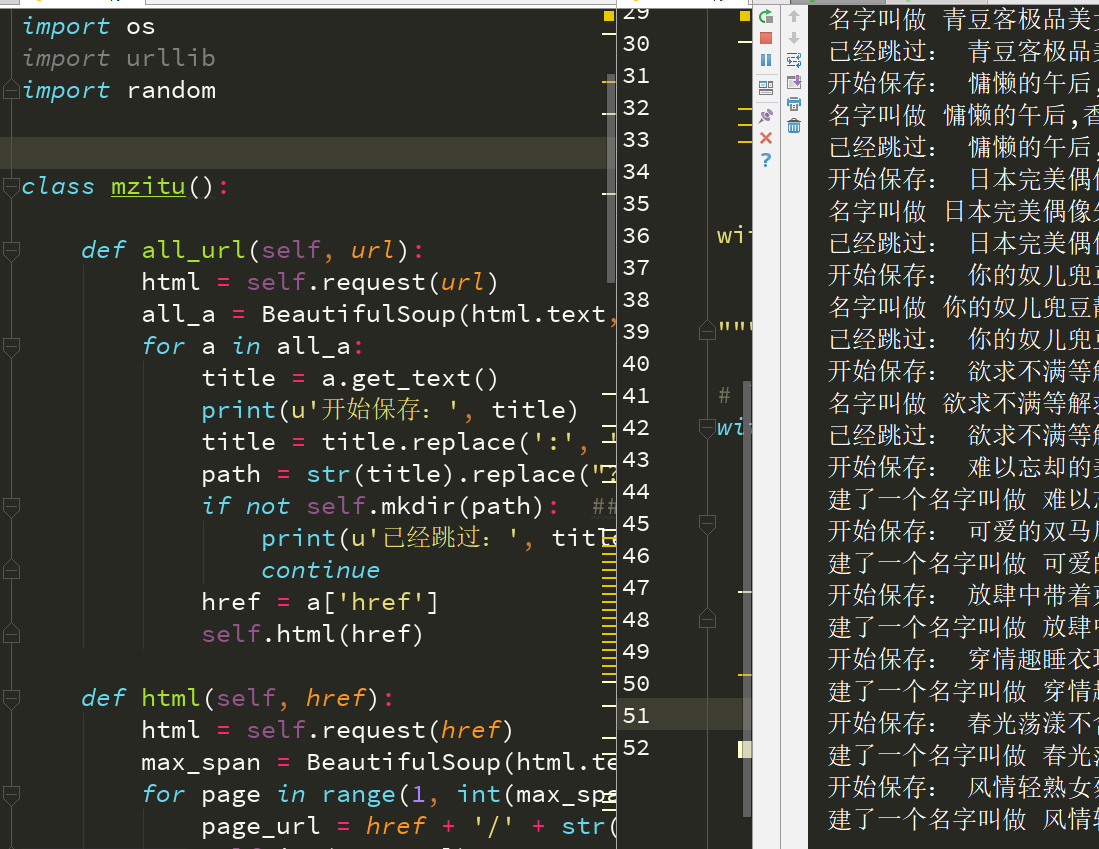
执行结果:
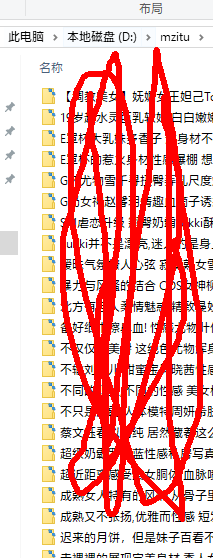
遇到的错误如何解决:
1、错误提示:requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:访问量瞬间过大,被网站反爬机制拦截了
解决方法:稍等一段时间再次执行即可
2、requests.exceptions.ChunkedEncodingError: ("Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)", ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
错误原因分析:可能对方服务器做了反爬
解决方法:requests手动添加一下header


1、使用Python3爬取美女图片-网站中的每日更新一栏的更多相关文章
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- android高仿抖音、点餐界面、天气项目、自定义view指示、爬取美女图片等源码
Android精选源码 一个爬取美女图片的app Android高仿抖音 android一个可以上拉下滑的Ui效果 android用shape方式实现样式源码 一款Android上的新浪微博第三方轻量 ...
- Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据 众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD ...
- Python3爬取美女妹子图片转载
# -*- coding: utf-8 -*- """ Created on Sun Dec 30 15:38:25 2018 @author: 球球 "&qu ...
随机推荐
- selenium工作原理
在我们new一个webdriver过程中 selenium会检测本地浏览器组件是否存在,版本是否匹配,接着会启动一套webservice ,这套webservice使用的selenium定义的webw ...
- webstorm + babel
网上有很多关于如何设置babel的.我学习着设置,但总差那么几步,没能满足我的需求. 我使用的是webStorm2017.1版本. babel安装准备 使用webStorm自带的filewatcher ...
- 在 Windows10 系统中安装 Homestead 本地开发环境
在 windows10 系统中安装 homestead 本地开发环境 在 windows10 环境下安装 homestead 开发环境,网上有很多相关教程其中大多都是 mac 环境,很多大神都是用户的 ...
- Django入门--创建项目及应用
Django是用于后台处理的web应用框架.用户通过浏览器输入网址,向http服务器发起访问网页的请求,http服务器(Apache/Nginx)接收到用户请求后,把请求发送给web应用框架进行处理, ...
- CodeForcesGym 100641D Generalized Roman Numerals
Generalized Roman Numerals Time Limit: 5000ms Memory Limit: 262144KB This problem will be judged on ...
- nodejs-app.js
设置静态目录 1 2 app.use(express.static(path.join(__dirname, 'public'))); //设置模版渲染的js,css,images的静态文件目录 设置 ...
- rabbitMQ学习笔记(四) 发布/订阅消息
前面都是一条消息只会被一个消费者处理. 如果要每个消费者都处理同一个消息,rabbitMq也提供了相应的方法. 在以前的程序中,不管是生产者端还是消费者端都必须知道一个指定的QueueName才能发送 ...
- failed to sync branch You might need to open a shell and debug the state of this repo.
failed to sync branch You might need to open a shell and debug the state of this repo. i made some c ...
- javascript——从「最被误解的语言」到「最流行的语言」
JavaScript曾是"世界上最被误解的语言".由于它担负太多的特性.包含糟糕的交互和失败的设计,但随着Ajax的到来.JavaScript"从最受误解的编程语言演变为 ...
- Spring MVC学习------------核心类与接口
核心类与接口: 先来了解一下,几个重要的接口与类. 如今不知道他们是干什么的没关系,先混个脸熟,为以后认识他们打个基础. DispatcherServlet -- 前置控制器 HandlerMap ...