(七)日志采集工具sleuth--分布式链路跟踪(zipkin)
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂,在项目中引入sleuth可以方便程序进行调试。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
改造前面的feign、service(服务)
pom增加:
<!--sleuth跟踪-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
feign增加日志:
@Autowired
private IFeignService feignService;
private static Logger log = LoggerFactory.getLogger(FeignController.class); @RequestMapping("/index")
public String index(){
log.info("feign info");
return feignService.index(); // @FeignClient(value = "service-hello")
}
service增加日志:
private static Logger log = LoggerFactory.getLogger(HelloController.class);
@RequestMapping("/index")
public String index() {
log.info("service info");
System.err.println("服务提供者client:" + name + "服务端口:" + port);
return "服务提供者client:" + name + "服务端口:" + port;
}
启动测试,打开eureka、feign、service

打开页面,正常

显示的日志如下:
2018-12-29 16:24:26.048 INFO [service-feign,1d270312e94cab85,1d270312e94cab85,false] 10692 --- [nio-8886-exec-8] c.e.fegin.controller.FeignController : feign info 2018-12-29 16:24:26.056 INFO [service-hello,1d270312e94cab85,5e23c30b75ee6755,false] 6560 --- [nio-8883-exec-5] c.e.e.controller.HelloController : service info
[appname,traceId,spanId,exportable],也就是Sleuth的跟踪数据。其中:- appname: 为微服务的服务名称;
- traceId\spanId: 为Sleuth链路追踪的两个术语,后面我们再仔细介绍;
- exportable 是否是发送给Zipkin
整合Zipkin服务
Zipkin是一个致力于收集分布式服务的时间数据的分布式跟踪系统。其主要涉及以下四个组件:
- collector: 数据采集;
- storage: 数据存储;
- search: 数据查询;
- UI: 数据展示.
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,个人推荐Elasticsearch,特别是后续当我们需要整合ELK时。
构建zipkin项目
用的springboot2,所以构建zipkin没有找到适合的方法(@EnableZipkinServer....失效),所以直接在官网https://zipkin.io/下载了jar包运行:
打开http://localhost:9411
修改feign、service:
<!--sleuth跟踪-->
<!--<dependency>-->
<!--<groupId>org.springframework.cloud</groupId>-->
<!--<artifactId>spring-cloud-starter-sleuth</artifactId>-->
<!--</dependency>-->
<!-- Zipkin 已包含spring-cloud-starter-sleuth -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
properties配置:
spring.zipkin.base-url=http://localhost:9411
spring.sleuth.sampler.percentage=1.0 # 默认
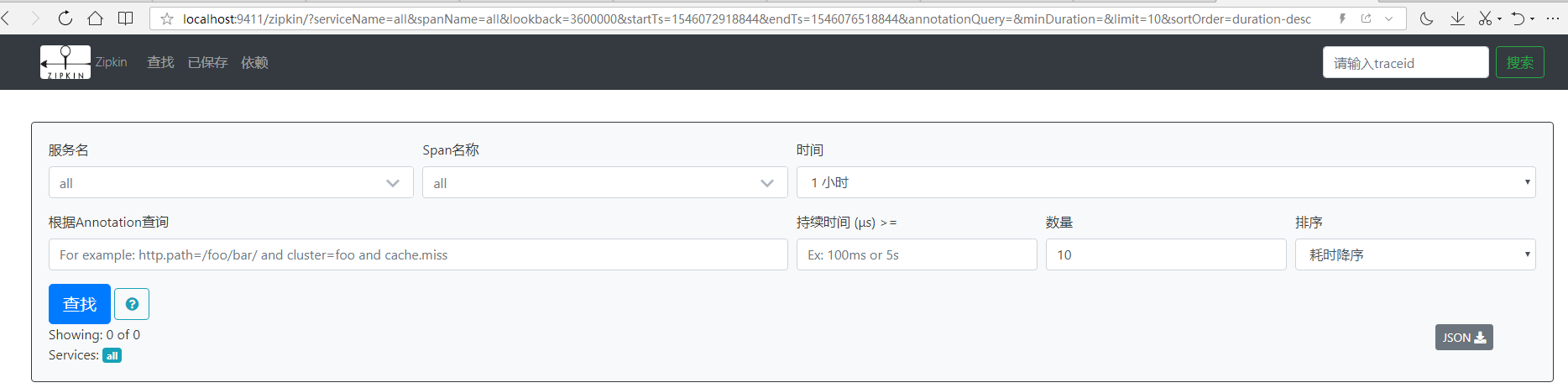
我们在浏览器中访问几次服务http://localhost:8886/index,然后转到Zipkin服务器

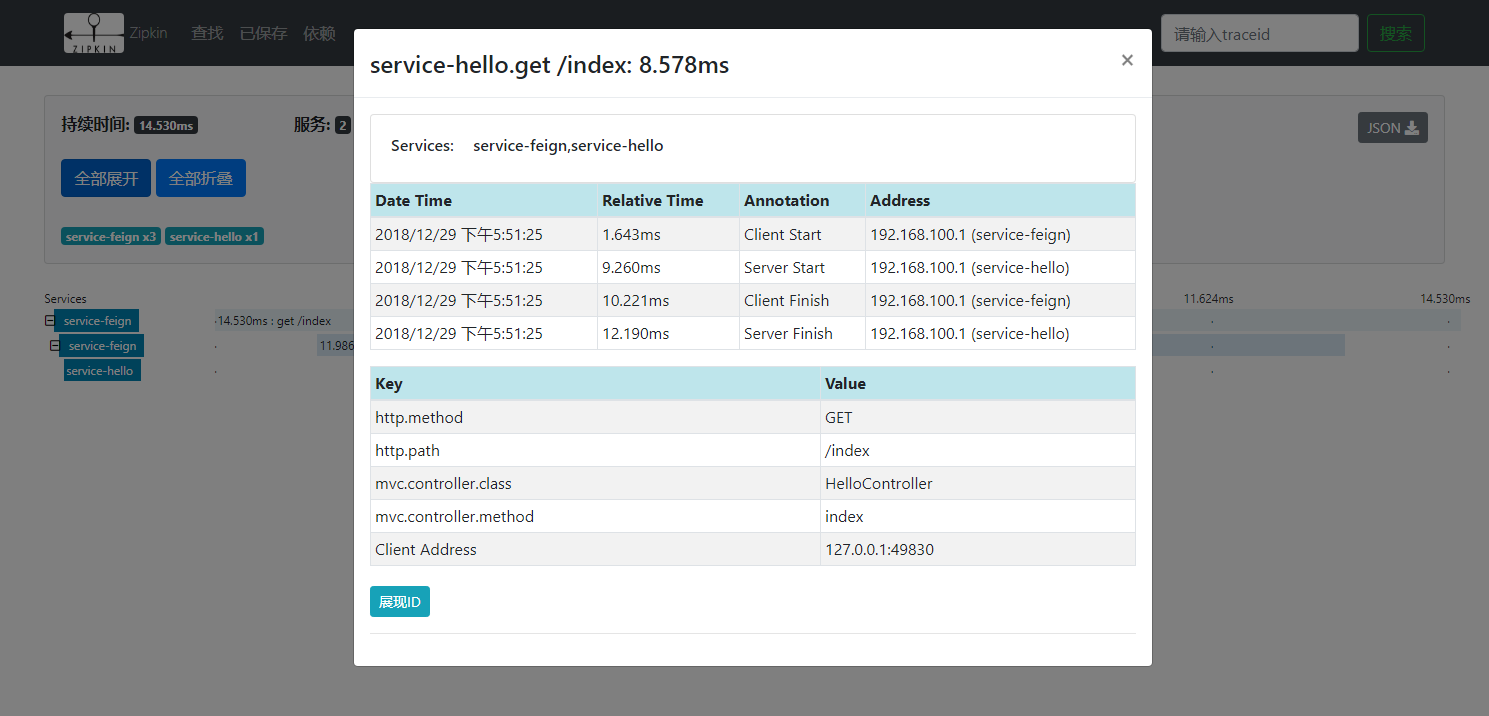
该界面对本次请求进行了更详细的展现。同样我们还可以再点击,以查看更为详细的数据,可以看到如下界面
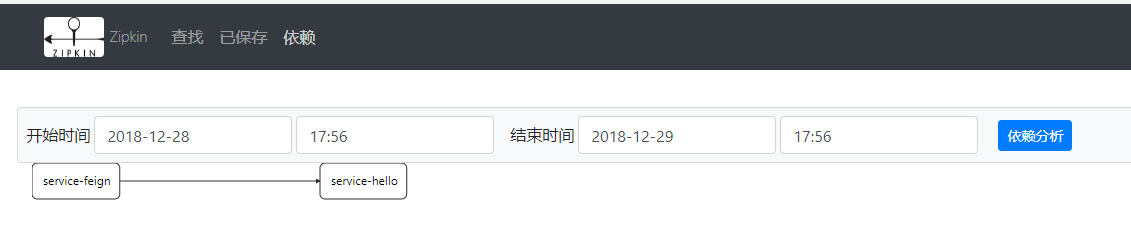
在Zipkin界面中我们还可以查看各服务之间的依赖关系
错误信息
Zipkin可以在跟踪记录中显示错误信息。当异常抛出并且没有捕获,Zipkin就会自动的换个颜色显示。在跟踪记录的清单中,当看到红色的记录时,就表示有异常抛出了。
关掉service-hello
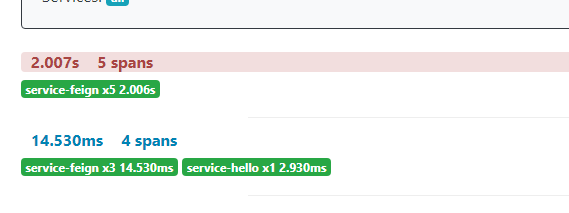
点击进去以获取更详细的错误信息。

采样率
在生成环境中,由于业务量比较大,所产生的跟踪数据可能会非常大,如果全部采集一是对业务有一定影响,二是对存储压力也会比较大,所以采样变的很重要。一般来说,我们也不需要把每一个发生的动作都进行记录。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。
我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
也可以通过实现bean的方式来设置采样为全部采样(AlwaysSampler)或者不采样(NeverSampler)
來源:简书
(七)日志采集工具sleuth--分布式链路跟踪(zipkin)的更多相关文章
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- spring-cloud-sleuth 和 分布式链路跟踪系统
==================spring-cloud-sleuth==================spring-cloud-sleuth 可以用来增强 log 的跟踪识别能力, 经常在微服 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- 使用zipKin构建NetCore分布式链路跟踪
本文主要讲解使用ZipKin构建NetCore分布式链路跟踪 场景 因为最近公司业务量增加,而项目也需要增大部署数量,K8S中Pod基本都扩容了一倍,新增了若干物理机,部分物理机网络通信存在问题,导致 ...
- 分布式链路跟踪系统架构SkyWalking和zipkin和pinpoint
Net和Java基于zipkin的全链路追踪 https://www.cnblogs.com/zhangs1986/p/8966051.html 在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框 ...
- 你的Node应用,对接分布式链路跟踪系统了吗?(一) 原创: 金炳 Node全栈进阶 4天前 戳蓝字「Node全栈进阶」关注我们哦
你的Node应用,对接分布式链路跟踪系统了吗?(一) 原创: 金炳 Node全栈进阶 4天前 戳蓝字「Node全栈进阶」关注我们哦
- 分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
原创: dqqzj SpringForAll社区 今天 Spring Cloud Sleuth Span是基本的工作单位. 例如,发送 RPC是一个新的跨度,就像向RPC发送响应一样. 跨度由跨度唯一 ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- 使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
原文:http://www.cnblogs.com/ityouknow/p/8403388.html 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成, ...
随机推荐
- bzoj3998: [TJOI2015]弦论(SAM+dfs)
3998: [TJOI2015]弦论 题目:传送门 题解: SAM的入门题目(很好的复习了SAM并加强Right集合的使用) 其实对于第K小的字符串直接从root开始一通DFS就好,因为son边是直接 ...
- iOS开发中权限再度梳理
前言 上篇文章iOS开发中的这些权限,你搞懂了吗?介绍了一些常用权限的获取和请求方法,知道这些方法的使用基本上可以搞定大部分应用的权限访问的需求.但是,这些方法并不全面,不能涵盖住所有权限访问的方法. ...
- php面向对象之构造函数和析构函数
php面向对象之构造函数和析构函数 简介 php面向对象支持两种形式的构造函数和析构函数,一种是和类同名的构造函数(php5.5之前),一类是魔术方法(php5.5之后).与类名相同的构造函数优先级比 ...
- Linux平台Oracle多个实例启动
如何在Linux系统中启动多个Oracle实例?相信很多Oracle的初学者都会碰到这一类问题,下面我简单介绍一下. 1.切换Oracle用户: # su oracle 2.切换到Oracle目录下: ...
- oracle 11gR2 如何修改scan vip 地址 /etc/hosts方式
这次帮客户搭建了一套oracle 11gR2 rac for aix环境,scan vip因为网络调整需要,需要更改以前设置好的scan vip,是采用/etc/hosts的方式,比如将scan vi ...
- Node.js:连接 MongoDB
ylbtech-Node.js:连接 MongoDB 1.返回顶部 1. Node.js 连接 MongoDB MongoDB是一种文档导向数据库管理系统,由C++撰写而成. 本章节我们将为大家介绍如 ...
- c/c++ 比较好的开源框架
作者:EZLippi链接:https://www.zhihu.com/question/19823234/answer/31632919来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转 ...
- ubuntu下无法将iNode绑定到侧边栏的解决办法
title: ubuntu下无法将iNode绑定到侧边栏的解决办法 toc: false date: 2018-09-01 17:43:52 categories: methods tags: ubu ...
- BZOJ 3323 splay维护序列
就第三个操作比较新颖 转化成 在l前插一个点 把r和r+1合并 //By SiriusRen #include <cstdio> #include <cstring> #inc ...
- canvas 画图优化
http://www.cnblogs.com/rhcad/archive/2012/11/17/2774794.html