Classification and Representation
Classification
To attempt classification, one method is to use linear regression and map all predictions greater than 0.5 as a 1 and all less than 0.5 as a 0. However, this method doesn't work well because classification is not actually a linear function.
The classification problem is just like the regression problem, except that the values we now want to predict take on only a small number of discrete values. For now, we will focus on the binary classification problem in which y can take on only two values, 0 and 1. (Most of what we say here will also generalize to the multiple-class case.) For instance, if we are trying to build a spam classifier for email, then 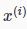 may be some features of a piece of email, and y may be 1 if it is a piece of spam mail, and 0 otherwise. Hence, y∈{0,1}. 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “-” and “+.” Given x(i), the corresponding
may be some features of a piece of email, and y may be 1 if it is a piece of spam mail, and 0 otherwise. Hence, y∈{0,1}. 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “-” and “+.” Given x(i), the corresponding  is also called the label for the training example.
is also called the label for the training example.
Hypothesis Representation
We could approach the classification problem ignoring the fact that y is discrete-valued, and use our old linear regression algorithm to try to predict y given x. However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn’t make sense for hθ(x) to take values larger than 1 or smaller than 0 when we know that y ∈ {0, 1}. To fix this, let’s change the form for our hypotheses hθ(x) to satisfy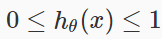 . This is accomplished by plugging
. This is accomplished by plugging  into the Logistic Function.
into the Logistic Function.
Our new form uses the "Sigmoid Function," also called the "Logistic Function":

The following image shows us what the sigmoid function looks like:

The function g(z), shown here, maps any real number to the (0, 1) interval, making it useful for transforming an arbitrary-valued function into a function better suited for classification.
hθ(x) will give us the probability that our output is 1. For example, hθ(x)=0.7 gives us a probability of 70% that our output is 1. Our probability that our prediction is 0 is just the complement of our probability that it is 1 (e.g. if probability that it is 1 is 70%, then the probability that it is 0 is 30%).
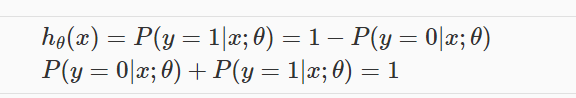
Decision Boundary
In order to get our discrete 0 or 1 classification, we can translate the output of the hypothesis function as follows:

The way our logistic function g behaves is that when its input is greater than or equal to zero, its output is greater than or equal to 0.5:

Remember.

So if our input to g is  , then that means:
, then that means:

From these statements we can now say:

The decision boundary is the line that separates the area where y = 0 and where y = 1. It is created by our hypothesis function.
Example:


Multiclass Classification: One-vs-all
Now we will approach the classification of data when we have more than two categories. Instead of y = {0,1} we will expand our definition so that y = {0,1...n}.
Since y = {0,1...n}, we divide our problem into n+1 (+1 because the index starts at 0) binary classification problems; in each one, we predict the probability that 'y' is a member of one of our classes.

The following image shows how one could classify 3 classes:We are basically choosing one class and then lumping all the others into a single second class. We do this repeatedly, applying binary logistic regression to each case, and then use the hypothesis that returned the highest value as our prediction.

To summarize:

Classification and Representation的更多相关文章
- 浅谈Logistic回归及过拟合
判断学习速率是否合适?每步都下降即可.这篇先不整理吧... 这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法.啥叫正统呢?我概念里面机器学习算法一般是这 ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- 《Machine Learning》系列学习笔记之第三周
第三周 第一部分 Classification and Representation Classification 为了尝试分类,一种方法是使用线性回归,并将大于0.5的所有预测映射为1,所有小于0. ...
- Andrew Ng机器学习课程笔记--week3(逻辑回归&正则化参数)
Logistic Regression 一.内容概要 Classification and Representation Classification Hypothesis Representatio ...
- ICLR 2014 International Conference on Learning Representations深度学习论文papers
ICLR 2014 International Conference on Learning Representations Apr 14 - 16, 2014, Banff, Canada Work ...
- Course Machine Learning Note
Machine Learning Note Introduction Introduction What is Machine Learning? Two definitions of Machine ...
- Survey of single-target visual tracking methods based on online learning 翻译
基于在线学习的单目标跟踪算法调研 摘要 视觉跟踪在计算机视觉和机器人学领域是一个流行和有挑战的话题.由于多种场景下出现的目标外貌和复杂环境变量的改变,先进的跟踪框架就有必要采用在线学习的原理.本论文简 ...
- 《Learning Structured Representation for Text Classification via Reinforcement Learning》论文翻译.md
摘要 表征学习是自然语言处理中的一个基本问题.本文研究了如何学习文本分类的结构化表示.与大多数既不使用结构又依赖于预先指定结构的现有表示模型不同,我们提出了一种强化学习(RL)方法,通过自动覆盖优化结 ...
随机推荐
- excel的隔行插入
https://wenda.so.com/q/1523455238213064 #公式 IF(ISODD(ROW()),OFFSET($B$1,INT((ROW(A1)-1)/2),),OFFSET( ...
- 洛谷——P1137 旅行计划
https://www.luogu.org/problem/show?pid=1137 题目描述 小明要去一个国家旅游.这个国家有N个城市,编号为1-N,并且有M条道路连接着,小明准备从其中一个城市出 ...
- 【Android个人理解(八)】跨应用调用不同组件的方法
如果情景: 创建两个应用appA和appB,appA包括一个Service,此Service有一个堵塞方法每隔10秒钟产生一个随机数字,例如以下: public int getRandomInt(){ ...
- LeetCode 06 ZigZag Conversion
https://leetcode.com/problems/zigzag-conversion/ 水题纯考细心 题目:依照Z字形来把一个字符串写成矩阵,然后逐行输出矩阵. O(n)能够处理掉 记i为行 ...
- 《iOS Human Interface Guidelines》——Container View Controller
容器视图控制器 容器视图控制器管理和展示它的子视图集合--或者子控制器集合--以一种自己定义的方式. 系统定义的容器视图控制器的样例有标签栏视图控制器.导航栏视图控制器和分栏视图控制器(查看Tab B ...
- Mahout是什么?(一)
不多说,直接上干货! http://mahout.apache.org/ Mahout是Apache Software Foundation(ASF)旗下的一个开源项目. 提供一些可扩展的机器学习领域 ...
- ASP.NET MVC使用Ninject
Ninject是一个快如闪电的,轻量级的.....依赖注入框架,呃呃呃,貌似很少用到,Ninject就是一个DI容器,作用是对ASP.NET MVC程序中的组件进行解耦 ,说到解耦其实也有其他的方式可 ...
- vue.js提交按钮时简单的if判断表达式示例
简单的业务需求如下,看图说话 1:当充值金额没有填写的时候,会有Toast小弹框提示"请输入有效的充值金额" if (!this.money) { console.log('mon ...
- SpringBoot+springmvc异步处理请求
有两种情况,第一种是业务逻辑复杂,但不需要业务逻辑的结果,第二种是需要返回业务逻辑的处理结果 第一种比较简单,利用多线程处理业务逻辑,或者利用spring中@Asyn注解更简单, 使用@Asyn注解, ...
- 妙味css3课程---1-1、css中自定义属性可以用属性选择器么
妙味css3课程---1-1.css中自定义属性可以用属性选择器么 一.总结 一句话总结:可以的. 1.如何实现用属性选择器实现a标签根据href里面含有的字段选择背景图片? p a[href*=te ...