mysql查询优化--临时表和文件排序(Using temporary; Using filesort问题解决)
先看一段sql:
- <span style="font-size:18px;">SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0</span>
<span style="font-size:18px;">SELECT
*
FROM
rank_user AS rankUser
LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
ORDER BY
rankUser.create_time DESC
LIMIT 10 OFFSET 0</span>
介绍一下这段sql的表的构成:一张主表:rank_user;两张跟rank_user直接关联(多张表通过同一字段最好是主键进行关联)的表:rank_user_level ,rank_user_login_stat ;两张跟rank_user非直接关联的表:rank_product ,rank_product_fee 。这段sql看似简单,但是执行时间却很长,我们来看一下执行计划:
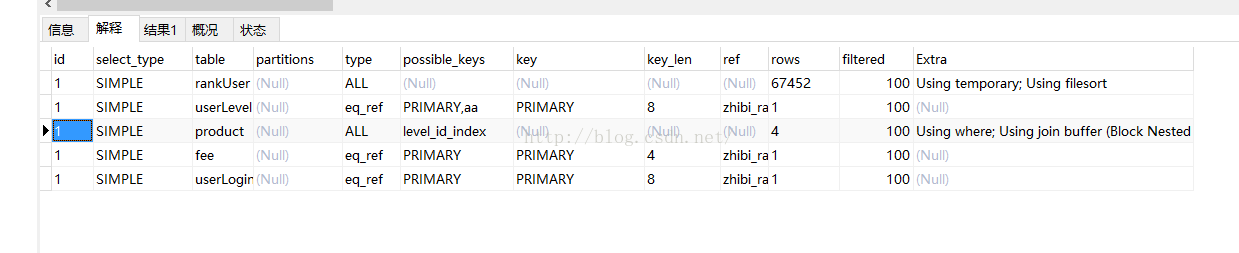
执行时间1.45s,可以看到,这段不仅仅扫描全表,而且使用了临时表,进行了文件排序。
为了找到原因,我们把排序去掉看一下:
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- -- ORDER BY
- -- rankUser.create_time DESC
- LIMIT 10 OFFSET 0
SELECT
*
FROM
rank_user AS rankUser
LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
-- ORDER BY
-- rankUser.create_time DESC
LIMIT 10 OFFSET 0

执行时间0.015s,扫描行数67452,果然是排序惹的祸。但是仅仅是排序惹的祸吗?别忘了这里有两张非直接关联的表,这样的查询,如果有查询条件或者排序分组的时候往往都需要创建临时表(这个没有办法,想想也知道)。为了验证这个观点,我们把两张非直接关联的表去掉看一下:
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
- -- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
- -- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0
SELECT
*
FROM
rank_user AS rankUser
LEFT JOIN rank_user_level AS userLevel ON rankUser.id = userLevel.user_id
-- LEFT JOIN rank_product AS product ON userLevel.new_level = product.level_id
-- LEFT JOIN rank_product_fee AS fee ON userLevel.fee_id = fee.fee_id
LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
ORDER BY
rankUser.create_time DESC
LIMIT 10 OFFSET 0
执行时间0.003s,扫描行数10,屌爆了有木有,mysql多表直接关联在没有其他筛选条件的情况下,查询速度大大提升,而且排序可以使用create_time这个索引,直接取到前十条。

到了这里,我想大家应该已经明白第一条sql查询时间很长的原因了:多表非直接关联的前提下还要排序。mysql查询往往最需要优化的地方就是临时表和文件排序了。这里总结一下教训:
1.mysql查询存在直接关联和非直接关联的问题,这两种查询效率差别很大;
2.mysql排序尽量使用索引;
3.mysql多表关联left join其他表的时候,如果以其他表的字段作为查询条件都会产生临时表;
4.mysql在非直接关联的基础上进行排序会很慢,需要进行优化;
知道了问题,我们就好优化了,这里我给出了两种方案:
第一种(子查询,适合子查询部分不作为查询条件):
- SELECT
- rankUser.id, rankUser.qq, rankUser.phone, rankUser.regip, rankUser.channel, rankUser.create_time, rankUser.qudao_key, rankUser.qq_openid, rankUser.wechat_openid,
- userLevel.recommend_count,userLevel.end_time,userLevel.new_level,userLevel.`level`,userLevel.new_recommend_count,userLevel.`is_limited`,
- (case when userLevel.new_level > 1 then 1 else 0 end) is_official_user,
- (select product_name from rank_product where level_id = userLevel.new_level) product_name,
- (select period from rank_product_fee where fee_id = userLevel.fee_id) period,
- userLoginInfo.last_login, userLoginInfo.login_count, userLoginInfo.login_seconds
- FROM rank_user AS rankUser
- LEFT JOIN rank_user_level as userLevel on userLevel.user_id=rankUser.id
- LEFT JOIN rank_user_login_stat as userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0
SELECT
rankUser.id, rankUser.qq, rankUser.phone, rankUser.regip, rankUser.channel, rankUser.create_time, rankUser.qudao_key, rankUser.qq_openid, rankUser.wechat_openid,
userLevel.recommend_count,userLevel.end_time,userLevel.new_level,userLevel.`level`,userLevel.new_recommend_count,userLevel.`is_limited`,
(case when userLevel.new_level > 1 then 1 else 0 end) is_official_user,
(select product_name from rank_product where level_id = userLevel.new_level) product_name,
(select period from rank_product_fee where fee_id = userLevel.fee_id) period,
userLoginInfo.last_login, userLoginInfo.login_count, userLoginInfo.login_seconds
FROM rank_user AS rankUser
LEFT JOIN rank_user_level as userLevel on userLevel.user_id=rankUser.id
LEFT JOIN rank_user_login_stat as userLoginInfo ON rankUser.id = userLoginInfo.user_id
ORDER BY
rankUser.create_time DESC
LIMIT 10 OFFSET 0

第二种(非直接关联转变成直接关联,这个要根据业务来定,我这里rank_product和rank_product_fee两张表只是为了查询rank_user_level表中的产品和产品费用信息,而rank_user_level是一张直接关联的表,故这里可以先将这三张表进行合并,然后再和rank_user表进行联合查询):
- SELECT
- *
- FROM
- rank_user AS rankUser
- LEFT JOIN (
- select
- l.*,p.product_name,f.period
- from
- rank_user_level l,rank_product p,rank_product_fee f
- where
- l.new_level = p.level_id
- and l.fee_id = f.fee_id
- ) AS userLevel ON rankUser.id = userLevel.user_id
- LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
- ORDER BY
- rankUser.create_time DESC
- LIMIT 10 OFFSET 0
SELECT
*
FROM
rank_user AS rankUser
LEFT JOIN (
select
l.*,p.product_name,f.period
from
rank_user_level l,rank_product p,rank_product_fee f
where
l.new_level = p.level_id
and l.fee_id = f.fee_id
) AS userLevel ON rankUser.id = userLevel.user_id
LEFT JOIN rank_user_login_stat AS userLoginInfo ON rankUser.id = userLoginInfo.user_id
ORDER BY
rankUser.create_time DESC
LIMIT 10 OFFSET 0
mysql查询优化--临时表和文件排序(Using temporary; Using filesort问题解决)的更多相关文章
- MYSQL 磁盘临时表和文件排序
因为Memory引擎不支持BOLB和TEXT类型,所以,如果查询使用了BLOB或TEXT列并且需要使用隐式临时表,将不得不使用MyISAM磁盘临时表,即使只有几行数据也是如此. 这会导致严重的性能开销 ...
- MySQL查询优化之explain的深入解析
在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要执行的行数.expla ...
- MySQL查询优化(转)
在分析性能欠佳的查询时,应考虑: 1) 应用程序是否正获取超过需要的数据,即访问了过多的行或列. 2) Mysql服务器是否分析了超过需要的行. 如果发现访问的数据行数很大,而生成的结果中数据行很少, ...
- 一文带你掌握MySQL查询优化技能
查询优化本就不是一蹴而就的,需要学会使用对应的工具.借鉴别人的经验来对SQL进行优化,并且提升自己. 分享一套博主觉得讲的很详细很实用的MySQL教程给大家,可直接点击观看! https://www. ...
- mysql中的文件排序(filesort)
在MySQL中的ORDER BY有两种排序实现方式: 1. 利用有序索引获取有序数据 2. 文件排序 在explain中分析查询的时候,利用有序索引获取有序数据显示Using index ,文件排序显 ...
- MySQL查询优化:连接查询排序limit
MySQL查询优化:连接查询排序limit(join.order by.limit语句) 2013-02-27 个评论 收藏 我要投稿 MySQL查询优化:连接查询排序 ...
- mysql查询优化之一:mysql查询优化常用方式
一.为什么查询速度会慢? 一个查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中在“执行”阶段包含了大量为了检索数据到存储引擎 ...
- MySQL系统临时表、用户临时表
MySQL临时表分为系统使用的临时表和用户使用的临时表. 系统使用的临时表是指MySQL在执行某些SQL语句时需要依赖临时表来完成整个过程.系统使用的临时表的情况可以分为以下几种: * group ...
- php面试专题---18、MySQL查询优化考点
php面试专题---18.MySQL查询优化考点 一.总结 一句话总结: 慢查询:查找分析查询速度慢的原因 数据访问:优化查询过程中的数据访问 长难句:优化长难的查询语句 特定类型:优化特定类型的查询 ...
随机推荐
- 0x66 Tarjan算法与无向图联通性
bzoj1123: [POI2008]BLO poj3694 先e-DCC缩点,此时图就变成了树,树上每一条边都是桥.对于添加边的操作,相当于和树上一条路径构环,导致该路径上所有边都不成为桥.那么找这 ...
- hdoj--1258--Sum It Up(dfs)
Sum It Up Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- 分布式系统CAP原则与BASE思想
一.CAP原则 CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性). Availability(可用性).Partition tolerance(分区容错性),三者 ...
- [WebServer] Linux下Apache与Tomcat整合的简单方法
Apache与Tomcat比较联系 apache支持静态页,tomcat支持动态的,比如servlet等. 一般使用apache+tomcat的话,apache只是作为一个转发,对jsp的处理是由to ...
- openssl https证书
今天摸索了下 HTTPS 的证书生成,以及它在 Nginx 上的部署.由于博客托管在 github 上,没办法部署证书,先记录下,后续有需要方便快捷操作.本文的阐述不一定完善,但是可以让一个初学者了解 ...
- Oracle---显式游标
一 游标的分类 在Oracle中提供了两种类型的游标:静态游标和动态游标. 1.静态游标是在编译时知道其SELECT语句的游标.静态游标又分为两种类型,即隐式游标和显式游标. 2.当用户需要为游标使 ...
- 利用javascript(自定义事件)记录尺寸可变元素的尺寸变化过程
1.效果图 2.源码 <%@ page contentType="text/html;charset=UTF-8" language="java" %&g ...
- 使用Scanner获取键盘输入 (转)
原文地址:https://www.cnblogs.com/SzBlog/p/5404335.html 后面有改动 使用Scanner类可以很方便地便获取用户的键盘输入,Scanner是一个基于正则表达 ...
- linq.sort
reflections.Sort(delegate(ReflectionEntity a, ReflectionEntity b) { if (a.CreatedTime < b.Created ...
- hadoop基础学习
MR系类: ①hadoop生态 >MapReduce:分布式处理 >Hdfs:hadoop distribut file system >其他相关框架 ->unstructur ...