Flink简介
Flink简介
Flink的核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以方便用户编写分布式任务:
1. DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便的采用Flink提供的各种操作符对分布式数据集进行各种操作,支持Java,Scala和Python。
2. DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便的采用Flink提供的各种操作符对分布式数据流进行各种操作,支持Java和Scala。
3. Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过Flink提供的类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
1. Flink ML,Flink的机器学习库,提供了机器学习Pipelines API以及很多的机器学习算法实现。
2. Gelly,Flink的图计算库,提供了图计算的相关API以及很多的图计算算法实现。
Flink的技术栈如下图所示:
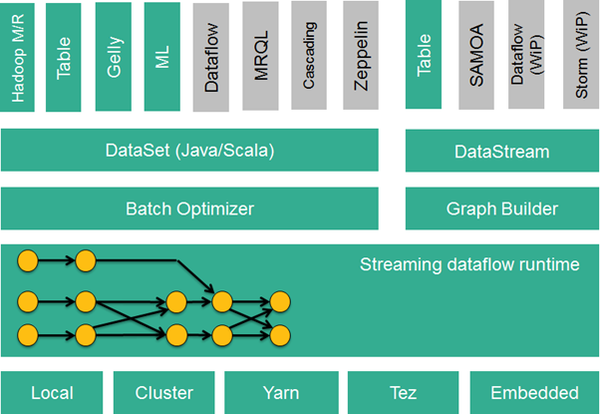
Flink技术栈
此外,Flink也可以方便地和其他的Hadoop生态圈的项目集成,例如,Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce/Storm代码,或是通过YARN申请集群资源等等。
链接:https://zhuanlan.zhihu.com/p/20585530
Spark 和 Flink 比较
Flink简介的更多相关文章
- (转)Flink简介
1. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- flink01--------1.flink简介 2.flink安装 3. flink提交任务的2种方式 4. 4flink的快速入门 5.source 6 常用算子(keyBy,max/min,maxBy/minBy,connect,union,split+select)
1. flink简介 1.1 什么是flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流(如离线数据)和无限流数据及逆行有状态计算(不太懂).可以部署在各种集群环境,对各种 ...
- Flink简介及使用
一.Flink概述 官网:https://flink.apache.org/ mapreduce-->maxcompute HBase-->部门 quickBI DataV Hive--& ...
- Apache 流框架Flink简介
1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提供 API来像Spark ...
- Flink学习之路(一)Flink简介
一.什么是Flink? Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能. 二.Flink特点 1.现有的开源计算方案,会把流处 ...
- Flink(一)Flink的入门简介
一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河 ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Flink流处理(一)- 状态流处理简介
1. Flink 简介 Flink 是一个分布式流处理器,提供直观且易于使用的API,以供实现有状态的流处理应用.它能够以fault-tolerant的方式高效地运行在大规模系统中. 流处理技术在当今 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
随机推荐
- iOS音频频谱动画,仿QQ录音频谱
先上效果图: display.gif 有需要的请移步GitHub下载: https://github.com/HuangGY1993/GYSpectrum 用法很简单,示例: SpectrumView ...
- idou老师教你学Istio 23 : 如何用 Istio 实现速率限制
使用 Istio 可以很方便地实现速率限制.本文介绍了速率限制的使用场景,使用 memquota\redisquota adapter 实现速率限制的方法,通过配置 rule 实现有条件的速率限制,以 ...
- win10锁屏壁纸文件夹Assets中无文件问题的解决方法
一.前言 win10在锁屏时会有很多精美的壁纸,在网上查找到win10锁屏壁纸存放目录为 : C:\Users\你的用户名\AppData\Local\Packages\Microsoft.Windo ...
- 迭代器 Iterator 是什么?(未完成)Iterator 怎么使用?(未完成)有什么特点?(未完成)
迭代器 Iterator 是什么?(未完成)Iterator 怎么使用?(未完成)有什么特点?(未完成)
- 算法笔记--BSGS && exBSGS 模板
https://www.cnblogs.com/sdzwyq/p/9900650.html 模板: unordered_map<int, int> mp; LL q_pow(LL n, L ...
- Codeforces 1187 F - Expected Square Beauty
F - Expected Square Beauty 思路:https://codeforces.com/blog/entry/68111 代码: #pragma GCC optimize(2) #p ...
- 从头至尾一点点实现自己的ViewPager效果
对于ViewPager,应该没有人在项目中没使用过它,效果非常的赞,使用也非常简单,但是如果自己来实现这样的效果,我想并非三下五除二的事了,这里涉及到怎么自定义ViewGroup了,它相比自定义Vie ...
- Windows Media Player播放视频导致程序闪退
在有的电脑上发现,使用Windows Media Player组件播放视频导致程序闪退. 发现是显卡问题,独立显卡换成集成显卡 解决: 打开显卡控制面板->管理3D设置->集成图形-> ...
- Java : 对象不再使用时,为什么要赋值为 null ?
今天遇到一个比较有意思的问题,对象不再使用时,为什么要赋值为 null ? 在这里我看到一篇文章说的不错,下面是网址,有兴趣的IT友可以看看. https://mp.weixin.qq.com/s/Z ...
- C# 安全性
一.标识和Principal static void Main(string[] args) { AppDomain.CurrentDomain.SetPrincipalPolicy(System.S ...