李宏毅 Keras手写数字集识别(优化篇)
在之前的一章中我们讲到的keras手写数字集的识别中,所使用的loss function为‘mse’,即均方差。那我们如何才能知道所得出的结果是不是overfitting?我们通过运行结果中的training和testing即可得知。
源代码与运行截图如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number] x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28) x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32') y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10) x_train=x_train
x_test=x_test x_train=x_train/255 #归一化到0-1区间 变为只有0 1的矩阵
x_test=x_test/255
return (x_train,y_train),(x_test,y_test) (x_train,y_train),(x_test,y_test)=load_data() model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#
#model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy']) #train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20) #测试结果 并打印accuary
result= model.evaluate(x_train,y_train,batch_size=10000)
print('\nTRAIN ACC :',result[1]) result= model.evaluate(x_test,y_test,batch_size=10000) # print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1]) print('\nTEST ACC :',result[1])
运行截图:
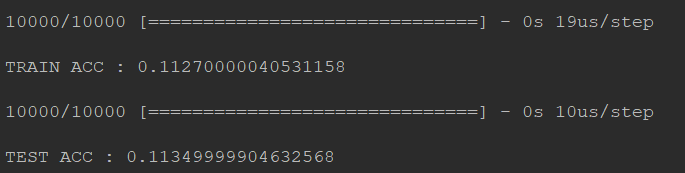
通过图片中的运行结果我们可以发现。训练结果中在training data上的准确率为0.1127,在testing data上的准确率为0.1134
虽然准确率不够高,但是这其中的train和test的准确率相差无几,所以这并不是overfitting问题。这其实就是模型的建立问题。
考虑更换loss function。原loss function 为 mse 更换为'categorical_crossentropy'然后观察训练结果。
源代码(只修改了loss):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number] x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28) x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32') y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10) x_train=x_train
x_test=x_test x_train=x_train/255 #归一化到0-1区间 变为只有0 1的矩阵
x_test=x_test/255
return (x_train,y_train),(x_test,y_test) (x_train,y_train),(x_test,y_test)=load_data() model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
#model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#
model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy']) #train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20) #测试结果 并打印accuary
result= model.evaluate(x_train,y_train,batch_size=10000)
print('\nTRAIN ACC :',result[1]) result= model.evaluate(x_test,y_test,batch_size=10000) # print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1]) print('\nTEST ACC :',result[1])
运行截图:

deep layer
考虑使hidden layer更深一些
for _ in range(10):
model.add(Dense(units=689,activation='sigmoid'))
结果不是很理想呢.....
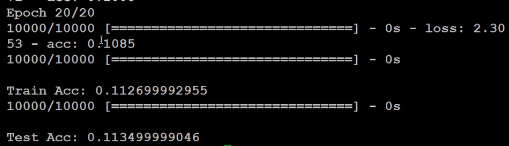
normalize
现在的图片是有进行normalize,每个pixel我们用一个0-1之间的值进行表示,那么我们不进行normalize,把255拿掉会怎样呢?
#注释掉
# x_train=x_train/255
# x_test=x_test/255
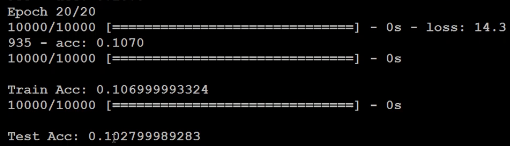
你会发现你又做不起来了,所以这种小小的地方,只是有没有做normalizion,其实对你的结果会有关键性影响。
optimizer
修改优化器optimizer,将SGD修改为Adam,然后再去跑一次,你会发现,用adam的时候最后不收敛的地方查不到,但是上升的速度变快。
源代码不贴了,就是修改了optimizer
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
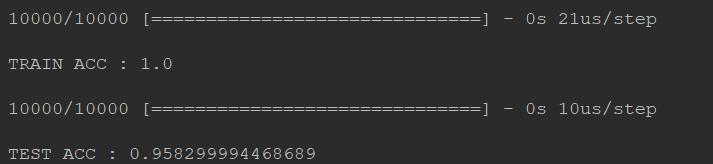
你会惊奇的发现!wow!train accuracy居然达到100%!而且test accuracy也表现的不错~
运行截图:
Random noise
添加噪声数据,看看结果会掉多少?完整代码不贴了QAQ
x_test = np.random.normal(x_test)
可以看出train的结果是ok的 但是test不太行,出现了overfitting!
运行截图:
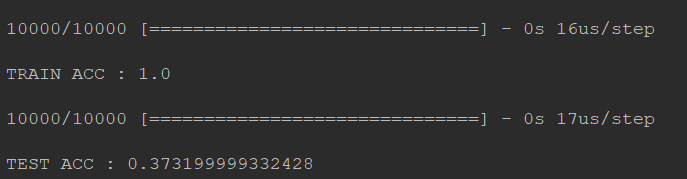
dropout
#dropout 就是在每一个隐藏层后面都dropout一下
model.add(Dense(input_dim=28*28,units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.7))
model.add(Dense(units=10,activation='softmax'))
要知道dropout加入之后,train的效果会变差,然而test的正确率提升了
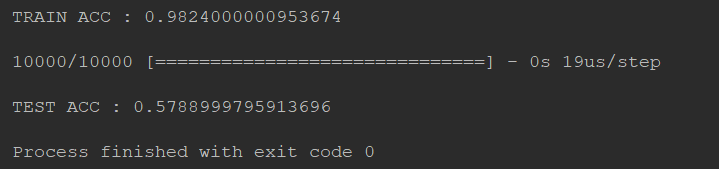
李宏毅 Keras手写数字集识别(优化篇)的更多相关文章
- 如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP, ...
- [机器学习] keras:MNIST手写数字体识别(DeepLearning 的 HelloWord程序)
深度学习界的Hello Word程序:MNIST手写数字体识别 learn from(仍然是李宏毅老师<机器学习>课程):http://speech.ee.ntu.edu.tw/~tlka ...
- 【TensorFlow篇】--Tensorflow框架实现SoftMax模型识别手写数字集
一.前述 本文讲述用Tensorflow框架实现SoftMax模型识别手写数字集,来实现多分类. 同时对模型的保存和恢复做下示例. 二.具体原理 代码一:实现代码 #!/usr/bin/python ...
- 【Keras篇】---Keras初始,两种模型构造方法,利用keras实现手写数字体识别
一.前述 Keras 适合快速体验 ,keras的设计是把大量内部运算都隐藏了,用户始终可以用theano或tensorflow的语句来写扩展功能并和keras结合使用. 二.安装 Pip insta ...
- Python实现神经网络算法识别手写数字集
最近忙里偷闲学习了一点机器学习的知识,看到神经网络算法时我和阿Kun便想到要将它用Python代码实现.我们用了两种不同的方法来编写它.这里只放出我的代码. MNIST数据集基于美国国家标准与技术研究 ...
- Pytorch卷积神经网络识别手写数字集
卷积神经网络目前被广泛地用在图片识别上, 已经有层出不穷的应用, 如果你对卷积神经网络充满好奇心,这里为你带来pytorch实现cnn一些入门的教程代码 #首先导入包 import torchfrom ...
- python手写神经网络实现识别手写数字
写在开头:这个实验和matlab手写神经网络实现识别手写数字一样. 实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手 ...
- matlab手写神经网络实现识别手写数字
实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手写数字图片,于是我就尝试用matlab写一个网络. 实验数据:500 ...
- 闭关修炼180天--手写IOC和AOP(xml篇)
闭关修炼180天--手写IOC和AOP(xml篇) 帝莘 首先先分享一波思维导图,涵盖了一些Spring的知识点,当然这里并不全面,后期我会持续更新知识点. 在手写实现IOC和AOP之前(也就是打造一 ...
随机推荐
- Django+MySQLDB配置
Django+MySQLDB配置 来源: ChinaUnix博客 日期: 2009.07.09 16:25 (共有条评论) 我要评论 一.安装Mysql(1)下 ...
- Codeforces Round #590 (Div. 3) C. Pipes
链接: https://codeforces.com/contest/1234/problem/C 题意: You are given a system of pipes. It consists o ...
- KindEditor完全复制word内容
我司需要做一个需求,就是使用富文本编辑器时,不要以上传附件的形式上传图片,而是以复制粘贴的形式上传图片. 在网上找了一下,有一个插件支持这个功能. WordPaster 安装方式如下: 直接使用Wor ...
- 集合家族——LinkedList
一.概述: LinkedList 与 ArrayList 一样实现 List 接口,只是 ArrayList 是 List 接口的大小可变数组的实现,LinkedList 是 List 接口链表的实现 ...
- 浏览器事件循环机制(event loop)
JS是单线程的 JS是单线程的,或者说只有一个主线程,也就是它一次只能执行一段代码.JS中其实是没有线程概念的,所谓的单线程也只是相对于多线程而言.JS的设计初衷就没有考虑这些,针对JS这种不具备并行 ...
- macos npm + node 环境启动问题排查
MacOS安装npm全局包的权限问题 解决办法:修改npm包所安装目录的权限:sudo chown -R $USER /usr/local 然后输入密码就可以了 deMBP:~ $ sudo ch ...
- mybatis 批量将list数据插入到数据库
随着业务需要,有时我们需要将数据批量添加到数据库,mybatis提供了将list集合循环添加到数据库的方法.具体实现代码如下: 1.mapper层中创建 insertForeach(List < ...
- android data binding jetpack VIII BindingConversion
android data binding jetpack VIII BindingConversion android data binding jetpack VII @BindingAdapter ...
- C#剪切生成高质量缩放图片
/// <summary> /// 高质量缩放图片 /// </summary> /// <param name="OriginFilePath"&g ...
- 扩展:向量空间模型算法(Vector Space Model)