hadoop 2.x HA 出现ssh不能解析问题记录。
在docker里面安装hadoop HA 在启动或者停止的时候报ssh不能解析问题。
问题现象:
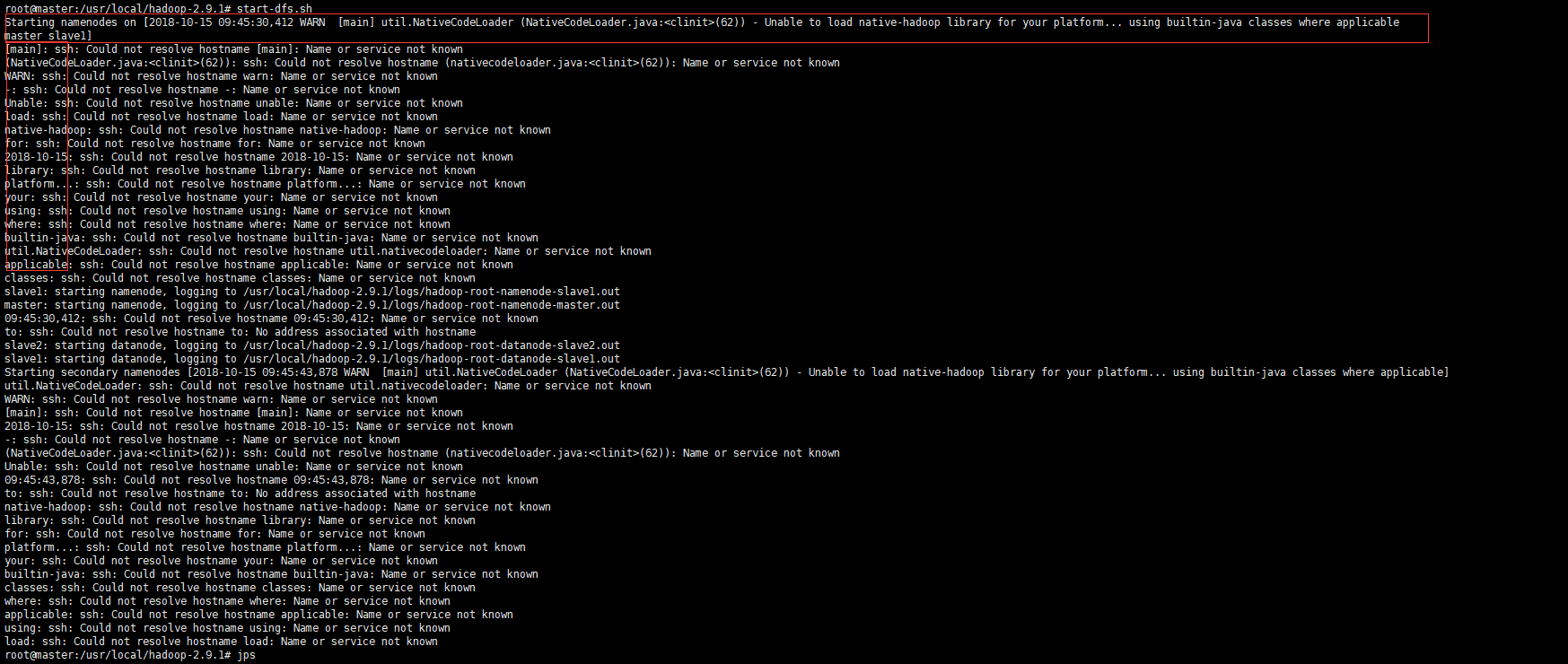
发现图片不清晰:把问题现象粘贴如下:
root@master:/usr/local/hadoop-2.9.1# start-dfs.sh
Starting namenodes on [2018-10-15 09:45:30,412 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
master slave1]
[main]: ssh: Could not resolve hostname [main]: Name or service not known
(NativeCodeLoader.java:<clinit>(62)): ssh: Could not resolve hostname (nativecodeloader.java:<clinit>(62)): Name or service not known
WARN: ssh: Could not resolve hostname warn: Name or service not known
-: ssh: Could not resolve hostname -: Name or service not known
Unable: ssh: Could not resolve hostname unable: Name or service not known
load: ssh: Could not resolve hostname load: Name or service not known
native-hadoop: ssh: Could not resolve hostname native-hadoop: Name or service not known
for: ssh: Could not resolve hostname for: Name or service not known
2018-10-15: ssh: Could not resolve hostname 2018-10-15: Name or service not known
library: ssh: Could not resolve hostname library: Name or service not known
platform...: ssh: Could not resolve hostname platform...: Name or service not known
your: ssh: Could not resolve hostname your: Name or service not known
using: ssh: Could not resolve hostname using: Name or service not known
where: ssh: Could not resolve hostname where: Name or service not known
builtin-java: ssh: Could not resolve hostname builtin-java: Name or service not known
util.NativeCodeLoader: ssh: Could not resolve hostname util.nativecodeloader: Name or service not known
applicable: ssh: Could not resolve hostname applicable: Name or service not known
classes: ssh: Could not resolve hostname classes: Name or service not known
slave1: starting namenode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-namenode-slave1.out
master: starting namenode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-namenode-master.out
09:45:30,412: ssh: Could not resolve hostname 09:45:30,412: Name or service not known
to: ssh: Could not resolve hostname to: No address associated with hostname
slave2: starting datanode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /usr/local/hadoop-2.9.1/logs/hadoop-root-datanode-slave1.out
Starting secondary namenodes [2018-10-15 09:45:43,878 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable]
util.NativeCodeLoader: ssh: Could not resolve hostname util.nativecodeloader: Name or service not known
WARN: ssh: Could not resolve hostname warn: Name or service not known
[main]: ssh: Could not resolve hostname [main]: Name or service not known
2018-10-15: ssh: Could not resolve hostname 2018-10-15: Name or service not known
-: ssh: Could not resolve hostname -: Name or service not known
(NativeCodeLoader.java:<clinit>(62)): ssh: Could not resolve hostname (nativecodeloader.java:<clinit>(62)): Name or service not known
Unable: ssh: Could not resolve hostname unable: Name or service not known
09:45:43,878: ssh: Could not resolve hostname 09:45:43,878: Name or service not known
to: ssh: Could not resolve hostname to: No address associated with hostname
native-hadoop: ssh: Could not resolve hostname native-hadoop: Name or service not known
library: ssh: Could not resolve hostname library: Name or service not known
for: ssh: Could not resolve hostname for: Name or service not known
platform...: ssh: Could not resolve hostname platform...: Name or service not known
your: ssh: Could not resolve hostname your: Name or service not known
builtin-java: ssh: Could not resolve hostname builtin-java: Name or service not known
classes: ssh: Could not resolve hostname classes: Name or service not known
where: ssh: Could not resolve hostname where: Name or service not known
applicable: ssh: Could not resolve hostname applicable: Name or service not known
using: ssh: Could not resolve hostname using: Name or service not known
load: ssh: Could not resolve hostname load: Name or service not known
通过报错现象分析,是由于ssh解析错误,但是我的/etc/hosts里面主机名与ip地址的映射关系完全没问题,这个时候就不能是ssh问题,那就肯定是hadoop本身的问题。
查看上面的图,看我红框里面的信息,不难发现ssh把
Starting namenodes on [2018-10-15 09:45:30,412 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
master slave1]
这条警告信息当做域名去解析了,所以肯定有问题。
解决办法:
打开 hadoop路径/etc/hadoop/log4j.properties 添加如下信息:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
这条信息的作用就是在log4j里面去除警告,记住是添加。
网上解决其他办法:(对于我这种情况不合适)
出现上述问题主要是环境变量没设置好,在~/.bash_profile或者/etc/profile中加入以下语句就没问题了。
#vi /etc/profile或者vi ~/.bash_profile
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib",
有的答案说不能加这个双引号:export HADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib,但具体怎样,我也不太清楚,因为这种方法没有解决掉我问题。所以说很多问题虽然看似跟网上其他人的问题相似,但最终却不能解决掉自己问题,在这种情况下还得自己好好分析,分析出错的现象,说实话,我这个问题我也是花了不少时间才发现的,也是由于不细心以及太依赖于百度了。这里记录一下,也是希望可以帮助到出现类似问题的小伙伴。
然后用source重新编译使之生效即可!
#source /etc/profile或者source ~/.bash_profile
还有一种情况也会出现类似的警告问题,那就是版本不兼容。比如说你下载的hadoop版本是64位的,但你的系统是32位,或者相反,系统64位,hadoop32位。
查看hadoop版本:
进入到如下目录:/usr/local/hadoop-2.9.1/lib/native(这是我的hadoop安装目录,具体情况看你自己安装的目录),
使用ldd或者file命令查看版本:centos系统查看

说明是64位的。
Ubuntu查看:

说明是64位。
file命令也可以查看:

同样说明hadoop是64位。查看操作系统版本使用uname -a就可以。
解决办法同样是在log4j的文件里面加入
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR 参考:https://blog.csdn.net/l1028386804/article/details/51538611
hadoop 2.x HA 出现ssh不能解析问题记录。的更多相关文章
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- hadoop高可靠性HA集群
概述 简单hdfs高可用架构图 在hadoop2.x中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态.Active NameNode对外提供服务,而Standb ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- hadoop 2.x HA(QJM)安装部署规划
一.主机服务规划: db01 db02 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- hadoop高可用HA的配置
zk3 zk4 zk5 配置hadoop的HA大概可以分为以下几步: 配置zookpeer(namenode之间的通信要靠zk来实现) 配置hadoop的 hadoop-env.sh hdfs-sit ...
- hadoop启动时,报ssh: Could not resolve hostname xxx: Name or service not known
本文转载自:http://blog.csdn.net/wodewutai17quiet/article/details/76795951 问题:hadoop启动时,报ssh: Could not re ...
随机推荐
- NEST指定id
1.默认以Id属性为Id,无Id属性则自动生成 2.可通过属性标签指定Id [ElasticsearchType(IdProperty = nameof(last_name))] public cla ...
- c语言二进制、八进制、十六进制
int binary = 0b01000010; //二进制 printf("%d\n", binary); //十进制 printf("0x%x\n", 0x ...
- centos7创建共享文件夹
0.检查是否已经安装samba rpm -qi samba 1.未安装,安装samba, 如果已安装,请忽略: yum -y install samba samba-client 2.共享一个目录,使 ...
- Android笔记(二十六) Android中的广播——BroadcastReceiver
为了方便进行系统级别的消息通知,Android有一套类似广播的消息机制,每个应用程序都可以对自己感兴趣的广播进行注册,这样该程序就只会接收自己所关心的广播内容,这些广播可能是来自于系统,也可能是来自于 ...
- 第二篇:Python基本知识
这一篇我们简单的介绍一下Python学习的基本知识-->Python文件是如何运行.Python文件打开通常会有两行注释,那么这两行注释是什么:上篇提到的字节码,这些字节码都存储在哪?即pyc文 ...
- python编码和解码
一.什么是编码 编码是指信息从一种形式或格式转换为另一种形式或格式的过程. 在计算机中,编码,简而言之,就是将人能够读懂的信息(通常称为明文)转换为计算机能够读懂的信息.众所周知,计算机能够读懂的是高 ...
- Python 使用 docopt 解析json参数文件
1. 背景 在深度学习的任务中,通常需要比较复杂的参数以及输入输出配置,比如需要不同的训练data,不同的模型,写入不同的log文件,输出到不同的文件夹以免混淆输出 常用的parser.add()方法 ...
- 理解serverless无服务
理解serverless无服务 阅读目录 一:什么是serverless无服务? 二:与传统模式架构区别? 三:serverless优缺点? 四:使用serverless的应用场景有哪些? 回到顶部 ...
- linux网络编程之posix线程(二)
继续接着上次的posix线程来学习: 回顾一下创建线程的函数: pthread_att_t属性变量是需要进行初始化才能够用的,一定初始化了属性变量,它就包含了线程的多种属性的值,那到底有哪些属性了,下 ...
- JDBC课程5--利用反射及JDBC元数据(ResultSetMetaData)编写通用的查询方法
/**-利用反射及JDBC元数据编写通用的查询方法 * 1.先利用SQl语句进行查询,得到结果集--> * 2.查找到结果集的别名:id--> * 3.利用反射创建实体类的对象,创建aut ...