Java根据余弦定理计算文本相似度
项目中需要算2个字符串的相似度,是根据余弦相似性算的,下面具体介绍一下:
余弦相似度计算
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
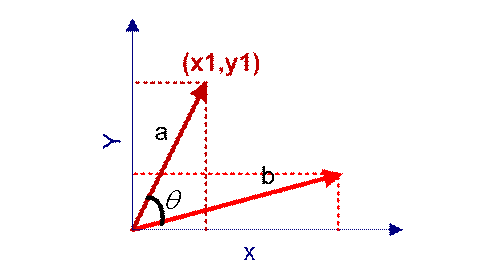
我们知道,对于两个向量,如果他们之间的夹角越小,那么我们认为这两个向量是越相似的。余弦相似性就是利用了这个理论思想。它通过计算两个向量的夹角的余弦值来衡量向量之间的相似度值。余弦相似性推导公式如下:
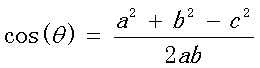
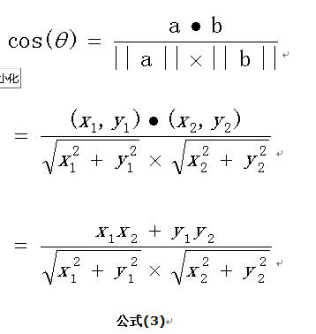
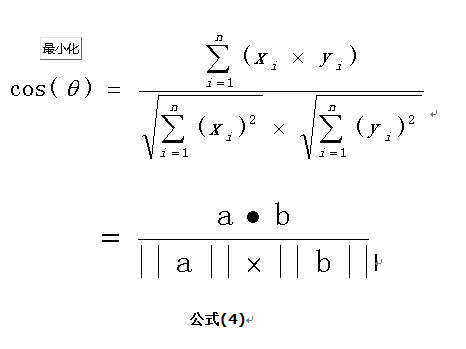
public class Cosine {
public static double getSimilarity(String doc1, String doc2) {
if (doc1 != null && doc1.trim().length() > 0 && doc2 != null&& doc2.trim().length() > 0) {
Map<Integer, int[]> AlgorithmMap = new HashMap<Integer, int[]>();
//将两个字符串中的中文字符以及出现的总数封装到,AlgorithmMap中
for (int i = 0; i < doc1.length(); i++) {
char d1 = doc1.charAt(i);
if(isHanZi(d1)){//标点和数字不处理
int charIndex = getGB2312Id(d1);//保存字符对应的GB2312编码
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null && fq.length == 2){
fq[0]++;//已有该字符,加1
}else {
fq = new int[2];
fq[0] = 1;
fq[1] = 0;
AlgorithmMap.put(charIndex, fq);//新增字符入map
}
}
}
}
for (int i = 0; i < doc2.length(); i++) {
char d2 = doc2.charAt(i);
if(isHanZi(d2)){
int charIndex = getGB2312Id(d2);
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null && fq.length == 2){
fq[1]++;
}else {
fq = new int[2];
fq[0] = 0;
fq[1] = 1;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
Iterator<Integer> iterator = AlgorithmMap.keySet().iterator();
double sqdoc1 = 0;
double sqdoc2 = 0;
double denominator = 0;
while(iterator.hasNext()){
int[] c = AlgorithmMap.get(iterator.next());
denominator += c[0]*c[1];
sqdoc1 += c[0]*c[0];
sqdoc2 += c[1]*c[1];
}
return denominator / Math.sqrt(sqdoc1*sqdoc2);//余弦计算
} else {
throw new NullPointerException(" the Document is null or have not cahrs!!");
}
}
public static boolean isHanZi(char ch) {
// 判断是否汉字
return (ch >= 0x4E00 && ch <= 0x9FA5);
/*if (ch >= 0x4E00 && ch <= 0x9FA5) {//汉字
return true;
}else{
String str = "" + ch;
boolean isNum = str.matches("[0-9]+");
return isNum;
}*/
/*if(Character.isLetterOrDigit(ch)){
String str = "" + ch;
if (str.matches("[0-9a-zA-Z\\u4e00-\\u9fa5]+")){//非乱码
return true;
}else return false;
}else return false;*/
}
/**
* 根据输入的Unicode字符,获取它的GB2312编码或者ascii编码,
*
* @param ch 输入的GB2312中文字符或者ASCII字符(128个)
* @return ch在GB2312中的位置,-1表示该字符不认识
*/
public static short getGB2312Id(char ch) {
try {
byte[] buffer = Character.toString(ch).getBytes("GB2312");
if (buffer.length != 2) {
// 正常情况下buffer应该是两个字节,否则说明ch不属于GB2312编码,故返回'?',此时说明不认识该字符
return -1;
}
int b0 = (int) (buffer[0] & 0x0FF) - 161; // 编码从A1开始,因此减去0xA1=161
int b1 = (int) (buffer[1] & 0x0FF) - 161;
return (short) (b0 * 94 + b1);// 第一个字符和最后一个字符没有汉字,因此每个区只收16*6-2=94个汉字
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) {
String str1="担保人姓名";
String str2="个人法定名称";
long start=System.currentTimeMillis();
double Similarity=Cosine.getSimilarity(str1, str2);
System.out.println("用时:"+(System.currentTimeMillis()-start));
System.out.println(Similarity);
}
}
Java根据余弦定理计算文本相似度的更多相关文章
- C#动态规划法计算文本相似度
C# 采用动态规划算法,计算两个字符串之间的相似程度. public static double CountTextSimilarity(string textX, string textY, boo ...
- DSSM算法-计算文本相似度
转载请注明出处: http://blog.csdn.net/u013074302/article/details/76422551 导语 在NLP领域,语义相似度的计算一直是个难题:搜索场景下quer ...
- 利用simhash计算文本相似度
摘自:http://www.programcreek.com/java-api-examples/index.php?source_dir=textmining-master/src/com/gta/ ...
- 转:Python 文本挖掘:使用gensim进行文本相似度计算
Python使用gensim进行文本相似度计算 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/ 在文本处理 ...
- 文本相似度 余弦值相似度算法 VS L氏编辑距离(动态规划)
设置n为字符串s的长度.("我是个小仙女") 设置m为字符串t的长度.("我不是个小仙女") 如果n等于0,返回m并退出.如果m等于0,返回n并退出.构造两个向 ...
- 文本离散表示(三):TF-IDF结合n-gram进行关键词提取和文本相似度分析
这是文本离散表示的第二篇实战文章,要做的是运用TF-IDF算法结合n-gram,求几篇文档的TF-IDF矩阵,然后提取出各篇文档的关键词,并计算各篇文档之间的余弦距离,分析其相似度. TF-IDF与n ...
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- C# 比较两文本相似度
这个比较文本用到的主要是余弦定理比较文本相似度,具体原理右转某度,主要适用场景是在考试系统中的简答题概述,可根据权重自动打分,感觉实用性蛮广的. 先说下思路: 文本分词,中文于英文不同,规范的英文每个 ...
- 【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
环境 Python3, gensim,jieba,numpy ,pandas 原理:文章转成向量,然后在计算两个向量的余弦值. Gensim gensim是一个python的自然语言处理库,能够将文档 ...
随机推荐
- MHA原理及搭建
MYSQL5.7下搭建MHA 环境说明 在主机1,主机2,主机3上安装MySQL服务端和客户端. 主机1 主机2 主机3 操作系统 CentOS7.4 CentOS7.4 CentOS7.4 主机名 ...
- T100——P处理程序显示进度明细
IF g_bgjob <> "Y" THEN #更新交易對像信用餘額檔: LET ls_value = cl_getmsg('axm ...
- JavaScript设计模式(发布订阅模式)
发布—订阅模式又叫观察者模式,它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知.在JavaScript开发中,我们一般用事件模型来替代传统的发布—订阅模式 ...
- hdu 6025(女生赛)
典型的用空间换取时间的思想 关键要理解多个数怎么算最小公倍数 用一个前缀 一个后缀 然后枚举去掉的点就可以了 #include <iostream> #include <cstdio ...
- L1-025. 正整数A+B 简单复习一下,。
本题的目标很简单,就是求两个正整数A和B的和,其中A和B都在区间[1,1000].稍微有点麻烦的是,输入并不保证是两个正整数. 输入格式: 输入在一行给出A和B,其间以空格分开.问题是A和B不一定是满 ...
- 21-Perl 发送邮件
1.Perl 发送邮件如果你的程序在 Linux/Unix 系统上运行,你就可以在 Perl 中使用 sendmail 工具来发送邮件.以下是一个简单的脚本实例用于发送邮件:#!/usr/bin/pe ...
- 大数据学习(2)- export、source(附带多个服务器一起启动服务器)
linux环境中, A=1这种命名方式,变量作用域为当前线程 export命令出的变量作用域是当前进程及其子进程. 可以通过source 脚本,将脚本里面的变量放在当前进程中 附带自己写的tomcat ...
- Cognex925B的使用方法
一.Cognex925B的简介 Cognex925B是一款线激光扫描传感器,利用激光三角的原理测量Z方向的断差. 二 ...
- Windows 7 系统下显示文件类型的扩展名和隐藏文件
一.显示扩展名 点击开始菜单 在搜索框中输入「文件夹选项」并单击 切换到「查看」栏,取消勾选「隐藏已知文件类型的扩展名」这一项 设置完成 ps: 你也可以通过单击下图位置进行相应操作来达到同样的效果 ...
- Oracle的FIXED
今天发现一个有意思的问题,我们知道,在Oracle数据库中正常执行 select sysdate from dual 都可以返回当前主机的系统时间.正常修改系统时间,对应的查询结果也会变成修改后的系统 ...