Python数据抓取(2) —简单网络爬虫的撰写
(一)使用Requests存储网页
Requests
是什么?网络资源(URLs)抓取套件
优点?
- 改善urllib2的缺点,让使用者以最简单的方式获取网络资源
- 可以使用REST操作(POST,PUT,GET,DELETE)存取网络资源
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
print(response.text)模拟HTTP的GET方法存储网页,获取网页的内容,这时我们发现我们获取的结果是乱码,为什么呢?
- 我们所抓取网页是UTF8的,但是python在请求的时候,把它误判为不知道是什么编码,因此把这个编码显示为预设编码:ISO-8859-1
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
print(response.encoding)显示结果为ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面代码改进如下,我们便可以获得一个简体中文的内容:
import requests
response = requests.get('http://blog.sina.com.cn/lm/stock/')
response.encoding = 'utf-8'
print(response.text)现在我们还有一个问题,该如何把上面非结构化的数据转化为结构化的数据呢?—DOM TREE方法
(二)用BeautifulSoup解析网页
1.基础铺垫-DOM TREE
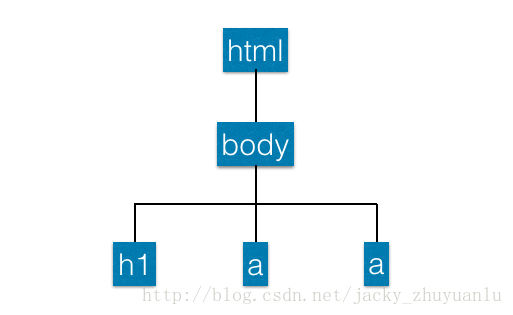
- 全称:Document Object Model Tree,它是一组API,可以跟网页的元素进行互动,使用BeautifulSoup就可以把网页变成一个DOM TREE,我们就可以根据DOM TREE的节点进行操作

- 上图的举例,最外面结构是html,是最上层的节点,下面一层是body,里面包含h1和a两个链接,这些就组成了DOM TREE的架构,我们就可以根据这个架构下的某些节点进行互动,我们可以取得h1里面的词,也可以取得a里面的词,这时候我们就可以把数据顺利提取出来;
2.BeautifulSoup范例
- 将网页读进BeautifulSoup中
from bs4 import BeautifulSoup
html_sample = '\
<html> \
<body> \
<h1 id="title">Hello World</h1> \
<a href="#" class="link">This is link1</a> \
<a href="# link2" class="link">This is link2</a> \
</body> \
</html> '
soup = BeautifulSoup(html_sample)
print(soup.text)
- 这里会显示警告信息,警告信息告诉我们这段代码没有使用到我们的剖析器,这时python会预测一个剖析器给我们,如果我们要避免这种警告的产生,我们可以在代码中指明
soup = BeautifulSoup(html_sample,'html.parser')3.找出所有含有特定标签的HTML元素
另外需要考虑的是,即使我们可以利用BeautifulSoup将标签移除掉,但有时我们要抓取的一些内容还位于特殊的标签之中,我们该怎样把特殊标签,以及节点中的资料取出来?
- 使用select找出含有h1标签的元素
soup = BeautifulSoup(html_sample)
header = soup.select('h1')
print(header)- 使用select找出含有a标签的元素
soup = BeautifulSoup(html_sample)
alink = soup.select('a')
print(alink)下面我们实操一下:
from bs4 import BeautifulSoup
html_sample = '\
<html> \
<body> \
<h1 id="title">Hello World</h1> \
<a href="#" class="link">This is link1</a> \
<a href="# link2" class="link">This is link2</a> \
</body> \
</html> '
soup = BeautifulSoup(html_sample,'html.parser')
header = soup.select('h1')
print(header)显示的结果为:

- 如何进一步把上面的文字解开?加上[0],可以去掉中括号,加.text可以把里面的文字取出来
print(header[0].text)
4.取得含有特定CSS属性的元素
除了标签以外,我们该怎样取得特定的元素?我们可以透过CSS的属性去取得里面的元素,CSS是网页的“化妆师”,透过这个化妆师,我们可以对网页进行点缀
(1)如何要抓取独立不重复的元素,可以加上id的修饰
- 使用select找出所有id为title的元素(id前面需加#)
alink = soup.select('#title')
print(alink)(2)如果要抓取重复的元素,可以加上class的修饰
- 使用select找出所有class为link的元素(class前面需加 . )
soup = BeautifulSoup(html_sample)
for link in soup.select('.link'):
print(link)5.取得含有特定CSS属性的元素
在网页的连接上,我们会用 a tag 去连接不同的网页,a tag 有一个属性就叫href,透过这个属性我们才能连接到不同的网页;
- 使用select找出所有a tag 的href连结
alinks = soup.select('a')
for link in alinks:
print(link['href'])Python数据抓取(2) —简单网络爬虫的撰写的更多相关文章
- python数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- Python数据抓取(1) —数据处理前的准备
(一)数据抓取概要 为什么要学会抓取网络数据? 对公司或对自己有价值的数据,80%都不在本地的数据库,它们都散落在广大的网络数据,这些数据通常都伴随着网页的形式呈现,这样的数据我们称为非结构化数据 如 ...
- Python数据抓取_BeautifulSoup模块的使用
在数据抓取的过程中,我们往往都需要对数据进行处理 本篇文章我们主要来介绍python的HTML和XML的分析库 BeautifulSoup 的官方文档网站如下 https://www.crummy.c ...
- Python数据抓取(3) —抓取标题、时间及链接
本次分享,jacky将跟大家分享如何将第一财经文章中的标题.时间以及链接抓取出来 (一)观察元素抓取位置 网页的原始码很复杂,我们必须找到特殊的元素做抽取,怎么找到特殊的元素呢?使用开发者工具检视每篇 ...
- (转)ObjC利用正则表达式抓取网页内容(网络爬虫)
转自:http://www.cocoachina.com/bbs/read.php?tid=103813 *****boy]原创 2012年5月20日 在开发项目的过程,很多情况下我们需要利用互联网上 ...
- ObjC利用正则表达式抓取网页内容(网络爬虫)
本文转载至 http://www.cocoachina.com/bbs/read.php?tid=103813&fpage=63 在开发项目的过程,很多情况下我们需要利用互联网上的一些数据,在 ...
- 使用Puppeteer进行数据抓取(三)——简单的示例
本文以一个示例简单的介绍一下puppeteer的用法,我们的目的是:获取我博客上的文章的前十页的所有随笔的标题和链接.由于puppeteer本身是自动化chorme,因此这里我们的步骤和手动操作浏览器 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
随机推荐
- Statefulset的拓扑状态
Statefulset: 实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,就被称为“有状态应用”(Stateful Application). StatefulSet 的设计其实非常容易理解 ...
- Linux:PS查看进程信息,和查看tomcat内存等信息
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/fly910905/article/deta ...
- Your ApplicationContext is unlikely tostart due to a @ComponentScan of the defau
一.错误提示: Your ApplicationContext is unlikely tostart due to a @ComponentScan of the default package.. ...
- 【死磕Java并发】—–深入分析ThreadLocal
ThreadLoacal是什么? ThreadLocal是啥?以前面试别人时就喜欢问这个,有些伙伴喜欢把它和线程同步机制混为一谈,事实上ThreadLocal与线程同步无关.ThreadLocal虽然 ...
- git基本操作及实用工具
//git1.安装客户端git Git-2.9.3-rebase-i-64-bit.exe2.安装完成后打开git bashgit config --global user.name "li ...
- PBE加密 .net 实现
using System; using System.Security.Cryptography; using System.Text; namespace Demo { internal class ...
- codeblocks 使用汇总
codeblocks 使用汇总 http://www.cnblogs.com/-clq/archive/2012/01/31/2333247.html
- Spark读取HDFS文件,任务本地化(NODE_LOCAL)
Spark也有数据本地化的概念(Data Locality),这和MapReduce的Local Task差不多,如果读取HDFS文件,Spark则会根据数据的存储位置,分配离数据存储最近的Execu ...
- About Spring MVC
一.简介 1.Springmvc是什么 Spring Web MVC是一种基于Java的实现了Web MVC设计模式的请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将web层进行职责解 ...
- 【转】Delphi货币类型转中文大写金额
unit TU2.Helper.Currency; interface ): string; ): string; implementation uses System.SysUtils, Syste ...