数据库SQL优化分析查询语句总结
方法一:
SELECT TOP 10 TEXT AS 'SQL Statement'
,last_execution_time AS 'Last Execution Time'
,(total_logical_reads + total_physical_reads + total_logical_writes) / execution_count AS [Average IO]
,(total_worker_time / execution_count) / 1000000.0 AS [Average CPU Time (sec)]
,(total_elapsed_time / execution_count) / 1000000.0 AS [Average Elapsed Time (sec)]
,execution_count AS "Execution Count",qs.total_physical_reads,qs.total_logical_writes
,qp.query_plan AS "Query Plan"
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
ORDER BY total_elapsed_time / execution_count DESC
示例: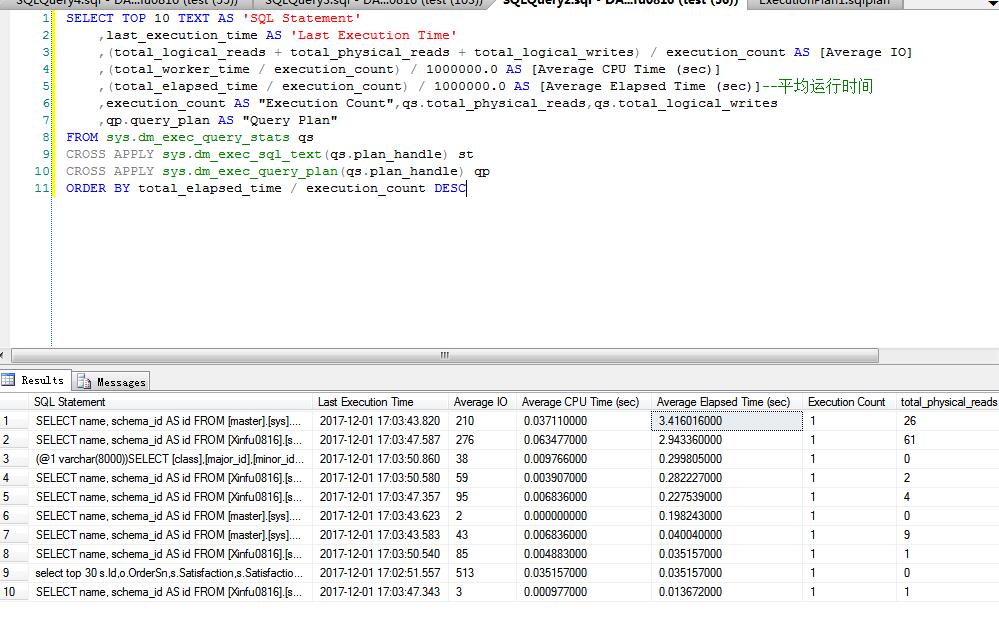
方法二:
SELECT DB_ID(DB.dbid) '数据库名'
, OBJECT_ID(db.objectid) '对象'
, QS.creation_time '编译计划的时间'
, QS.last_execution_time '上次执行计划的时间'
, QS.execution_count '执行的次数'
, QS.total_elapsed_time / 1000 '占用的总时间(秒)'
, QS.total_physical_reads '物理读取总次数'
, QS.total_worker_time / 1000 'CPU 时间总量(秒)'
, QS.total_logical_writes '逻辑写入总次数'
, QS.total_logical_reads N'逻辑读取总次数'
, QS.total_elapsed_time / 1000 N'总花费时间(秒)'
, SUBSTRING(ST.text, ( QS.statement_start_offset / 2 ) + 1,
( ( CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE QS.statement_end_offset
END - QS.statement_start_offset ) / 2 ) + 1) AS '执行语句'
FROM sys.dm_exec_query_stats AS QS CROSS APPLY
sys.dm_exec_sql_text(QS.sql_handle) AS ST INNER JOIN
( SELECT *
FROM sys.dm_exec_cached_plans cp CROSS APPLY
sys.dm_exec_query_plan(cp.plan_handle)
) DB
ON QS.plan_handle = DB.plan_handle
where SUBSTRING(st.text, ( qs.statement_start_offset / 2 ) + 1,
( ( CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset ) / 2 ) + 1) not like '%fetch%'
ORDER BY QS.total_elapsed_time / 1000 DESC
示例: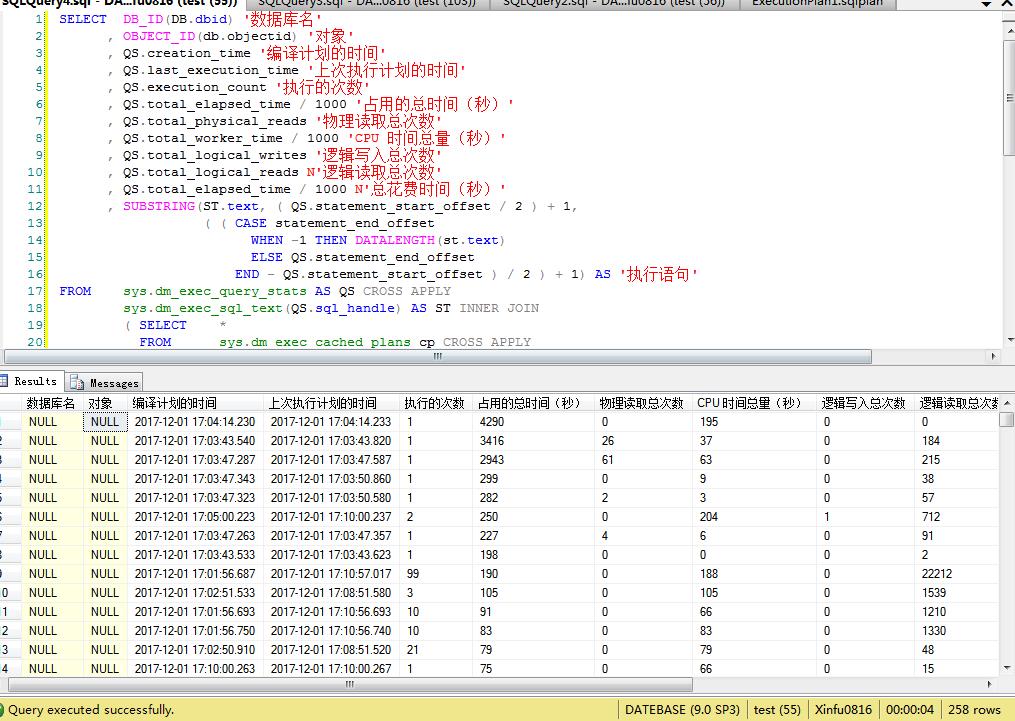
方法三:
SELECT s2.dbid,
(SELECT TOP 1 SUBSTRING(s2.text,statement_start_offset / 2+1 ,
( (CASE WHEN statement_end_offset = -1
THEN (LEN(CONVERT(nvarchar(max),s2.text)) * 2)
ELSE statement_end_offset END) - statement_start_offset) / 2+1)) AS sql_statement,
execution_count, plan_generation_num, last_execution_time, total_worker_time, last_worker_time, min_worker_time,
max_worker_time, total_physical_reads, last_physical_reads,
min_physical_reads, max_physical_reads, total_logical_writes, last_logical_writes, min_logical_writes, max_logical_writes
FROM sys.dm_exec_query_stats AS s1
CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS s2
WHERE s2.objectid is null
ORDER BY s1.total_worker_time desc
示例: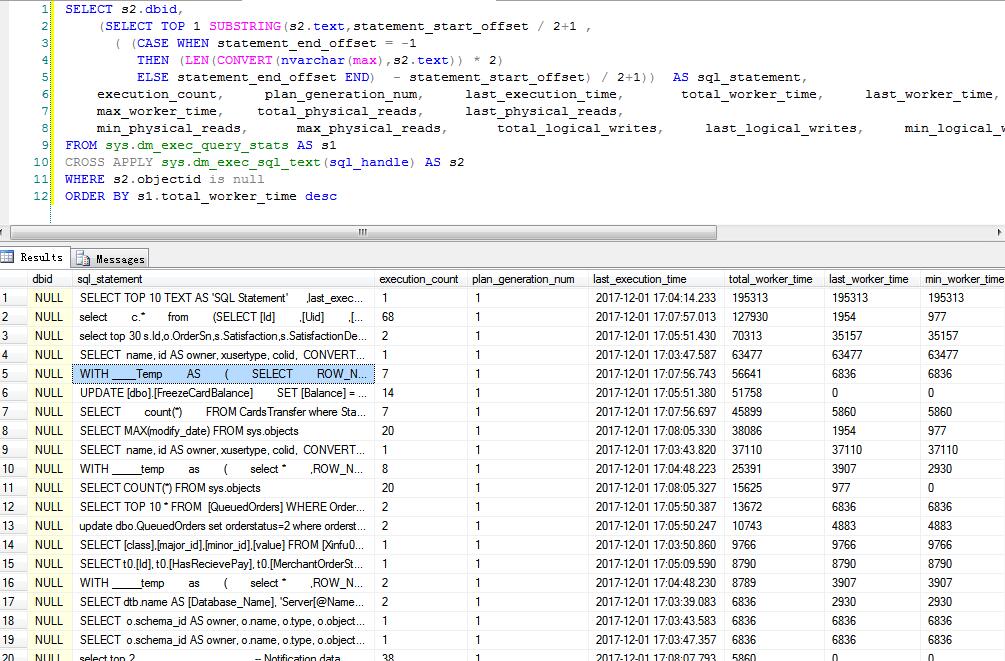
方式四:
选取了前10个最耗CPU时间的会话:
SELECT TOP 10
[session_id],
[request_id],
[start_time] AS '开始时间',
[status] AS '状态',
[command] AS '命令',
dest.[text] AS 'sql语句',
DB_NAME([database_id]) AS '数据库名',
[blocking_session_id] AS '正在阻塞其他会话的会话ID',
[wait_type] AS '等待资源类型',
[wait_time] AS '等待时间',
[wait_resource] AS '等待的资源',
[reads] AS '物理读次数',
[writes] AS '写次数',
[logical_reads] AS '逻辑读次数',
[row_count] AS '返回结果行数'
FROM sys.[dm_exec_requests] AS der
CROSS APPLY
sys.[dm_exec_sql_text](der.[sql_handle]) AS dest
WHERE [session_id]>50 AND DB_NAME(der.[database_id])='gposdb'
ORDER BY [cpu_time] DESC
示例: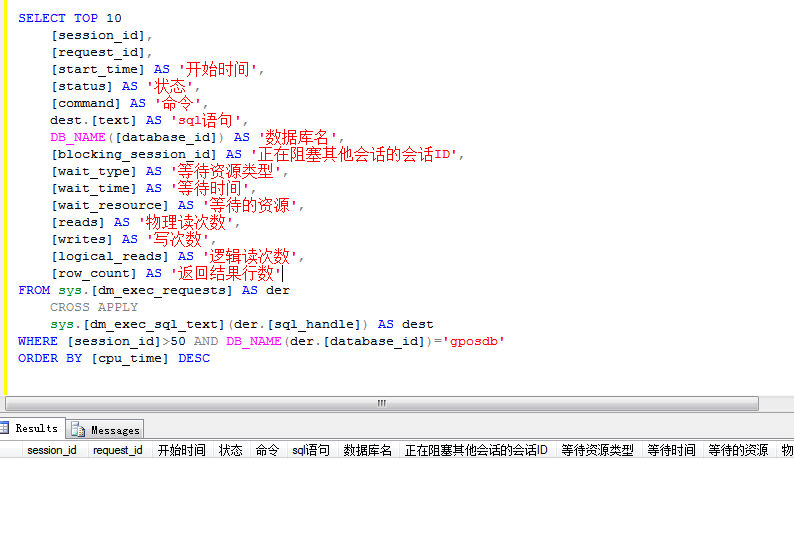
资料来源:
http://www.cnblogs.com/sdadx/p/6510213.html
http://blog.csdn.net/tianlianchao1982/article/details/5562035
https://www.cnblogs.com/xunziji/archive/2012/03/20/2408348.html
数据库SQL优化分析查询语句总结的更多相关文章
- 数据库sql优化总结之5--数据库SQL优化大总结
数据库SQL优化大总结 小编最近几天一直未出新技术点,是因为小编在忙着总结整理数据库的一些优化方案,特此奉上,优化总结较多,建议分段去消化,一口吃不成pang(胖)纸 一.百万级数据库优化方案 1.对 ...
- 我的mysql数据库sql优化原则
原文 我的mysql数据库sql优化原则 一.前提 这里的原则 只是针对mysql数据库,其他的数据库 某些是殊途同归,某些还是存在差异.我总结的也是mysql普遍的规则,对于某些特殊情况得特殊对待. ...
- 数据库sql优化方案
声明:这个不是我自己写的,是我们老师给我,我拿出来分享一下! 为什么要优化: 随着实际项目的启动,数据库经过一段时间的运行,最初的数据库设置,会与实际数据库运行性能会有一些差异,这时我们 ...
- 高性能mysql-----MySQL_explain关键字分析查询语句(一)
转载地址:https://www.cnblogs.com/xpp142857/p/7373005.html MySQL_explain关键字分析查询语句 通过对查询语句的分析,可以了解查询语句的执 ...
- MySQL_explain关键字分析查询语句
版权声明:本文为博主原创文章,转载请注明出处. 通过对查询语句的分析,可以了解查询语句的执行情况.MySQL中,可以使用EXPLAIN语句和DESCRIBE语句来分析查询语句. EXPLAIN语句的基 ...
- SQL优化- 数据库SQL优化——使用EXIST代替IN
数据库SQL优化——使用EXIST代替IN 1,查询进行优化,应尽量避免全表扫描 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引 . 尝试下面的 ...
- Explain分析查询语句
表的读取顺序 读取操作的类型 可用索引,实际使用的索引 表之间的引用 每张表多少行被优化器查询 索引的长度 EXPLAIN字段解释: ØTable:显示这一行的数据是关于哪张表的 Øpossible ...
- SQL结构化查询语句
SQL结构化查询语句 SQL定义了查询所有关系型数据库的规则. 1.通用语法 SQL语句可以单行或者多行书写,以分号结尾 可以使用空格和缩进增强可读性 不区分大小写,但是关键字建议大写 3种注释 注释 ...
- sql优化 慢查询分析
查询速度慢的原因很多,常见如下几种 SQL慢查询分析 转自:https://www.cnblogs.com/firstdream/p/5899383.html 1.没有索引或者没有用到索引(这是查询慢 ...
随机推荐
- LeetCode 岛屿的最大面积(探索字节跳动)
题目描述 给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合.你可以假设二维矩阵的四个边缘都被水包围着. 找到给定的 ...
- layer.js错误Uncaught TypeError: i is not a function
最初是要写一个管理后台来着,项目中需要用到弹出层,但是没有前端配合,我一个小PHP需要去写这玩意,怎么办呢?查了一些资料,发现layer对我来说还行,文档写的也比较完全,学习成本不高,就下决心用这个了 ...
- 齐普夫-Zipf定律
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- Android studio怎么使用git代码文件逐行追溯
在Android studio中集成了相当多的工具用于管理代码,应该现在经常使用的git的方式来管理管理,用于上传代码或者进行下载代码库中,而在git中进行管理的话,那么就可以进行历史的记录信息,如果 ...
- Actuator Elasticsearch healthcheck error
1. 相关环境 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- Java 实现判断 主机是否能 ping 通
Java 实现判断 主机是否能 ping 通 代码实现如下: import java.io.IOException; import java.net.InetAddress; import java. ...
- 错误 MSB6006 CL.exe 已退出,代码为2
环境 WIN10 + VS2019 社区版 按照其他网友的方法说 解决方法: 1 一个类内部的定义返回类型为double的方法种没有写return语句. 2 变量没有初始化也会导致这种情况. 但是设置 ...
- Python3 循环_break和continue语句及循环中的else子句
break和continue语句及循环中的else子句break语句可以跳出for和while的循环体.如果你从for或while循环中终止,任何对应的循环else块将不执行. continue语句被 ...
- 手写web框架之实现依赖注入功能
我们在Controller中定义了Service成员变量,然后在Controller的Action方法中调用Service成员变量的方法,那么如果实现Service的成员变量? 之前定义了@Injec ...
- MVC自定义视图
编写自定义模板,以单选按钮为例 1.在Shared新建模板视图(文件夹名必须为EditorTemplates) 2.编写模板代码 @model bool <table&g ...