Elasticsearch分布式机制探究
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量隐藏了复杂的分布式机制
分片机制
shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
集群发现机制
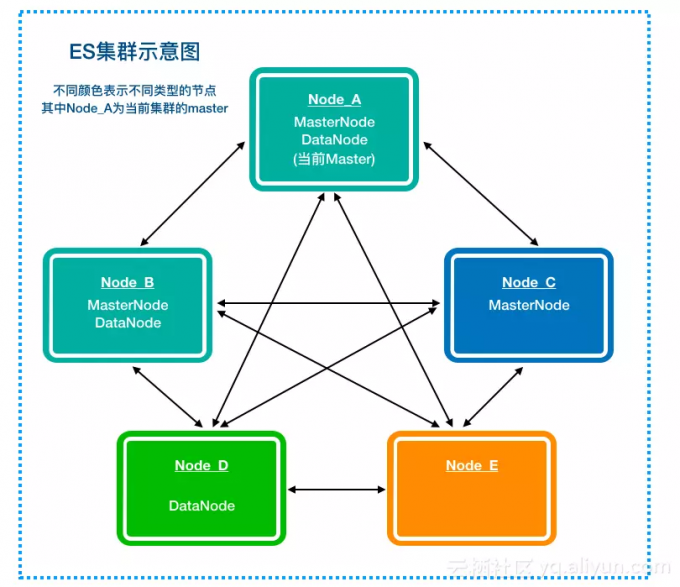
discovery.zen.ping_timeout (默认3秒)配置允许对选举的时间进行调整,用来处理缓慢或拥挤的网络。当一个节点请求加入主节点,它会发送请求信息到主节点,请求的超时时间配置为discovery.zen.join timeout,这个时间比较长,是discovery.zen.ping timeout 时间的20倍。当主节点发生问题的时候,现有的节点又会通过ping来重新选举一个新的主节点。当 discovery.zen.masterelection.filter_client 设置为 true 的时候,在选举主节点的时候从客户端节点(node.client为true,或者node.data和node.master同时为(false)的ping 操作将被忽略,该参数默认为 true当 discovery.zen.master election.filter data 为true时,在选举主节点的时候从数据节点(node.data为ture, node.mas..ter同时为false)的ping操作将被忽略,默认为falsec主节点配置为true的节点一直都有选举的资格当节点node.master设置为false或者node.client设置为true的时候,它们将自动排除成为主节点的可能性。
discovery.zen.minimum master nodes设置需要加入一个新当选的主节点的最小节点数B,或者接收它作为主节点的最小节点数::如果不满足这一要求,主节点会下台,重新开始新的选举。
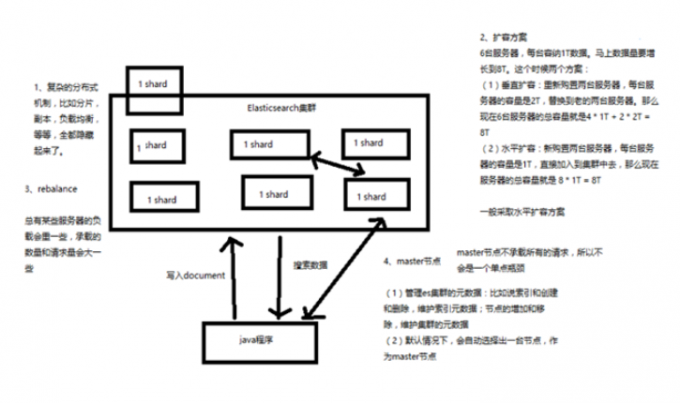
shard负载均衡
“Shard” 这个词英文的意思是”碎片”,而作为数据库相关的技术用语,称之为”分片”,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
shard副本
- index包含多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
集群扩容
Elasticsearch分布式机制探究的更多相关文章
- Elasticsearch学习笔记(四)ElasticSearch分布式机制
一.Elasticsearch对复杂分布式机制透明的隐藏特性 1.分片机制: (1)index包含多个shard,每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处 ...
- Elasticsearch分布式机制和document分析
1. Elasticsearch对复杂分布式机制的透明隐藏特性 1.1)分片机制 1.2)集群发现机制 1.3)shard负载均衡 1.4)shard副本,请求路由,集群扩容,shard重分配 2. ...
- ElasticSearch 分布式及容错机制
1 ElasticSearch分布式基础 1.1 ES分布式机制 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量.它的特性就是对复杂的分布式机制隐藏掉. 分片机制: ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- J2EE进阶(八)Hibernate与延迟加载机制探究
Hibernate与延迟加载机制探究 前言 Hibernate对象关系映射提供延迟的与非延迟的对象初始化.非延迟加载在读取一个对象的时候会将与这个对象所有相关的其他对象一起读取出来.这有时会导致成百的 ...
- Glibc堆块的向前向后合并与unlink原理机制探究
i春秋作家:Bug制造机 原文来自:Glibc堆块的向前向后合并与unlink原理机制探究 玩pwn有一段时间了,最近有点生疏了,调起来都不顺手了,所以读读malloc源码回炉一点一点总结反思下. U ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
随机推荐
- KiCad 如何在原理图添加元件时看到 PCB 封装?
KiCad 如何在原理图添加元件时看到 PCB 封装? 这个功能默认是关闭,评估关闭的原因是因为 PCB 封装很大,而且在前期也没必要详细知道 PCB 封装. 但是有时修改可以看到 PCB 封装会方便 ...
- Java集合整理
0,基础概念 Collection:统计大小.插入或删除数据.清空.是否包含某条数据,等等.而Collection就是对这些常用操作进行提取,只是其很全面.很通用.size(),isEmpty(),c ...
- get_client_ip() 获取IP地址
get_client_ip()获取ip地址,在开启IPv6协议的主机上会全部返回0.0.0.0原因是他会把ipv6地址认为是非法地址而转换成0.0.0.0,而ipv4地址在ipv6主机上用get_cl ...
- tp5服务器验证案例
1.验证器代码 <?php namespace app\user\validate; use think\Validate; use Potting\IDCard; /** * 山区治理报名验证 ...
- js-自定义对话框
引用插件 <link rel="stylesheet" type="text/css" href="${ctx }/resources/comm ...
- MySQL触发器详解
MySQL触发器 触发器是特殊的存储过程.不同的是,触发器不需要手动调用.只要当预定义的事件发生时,会被MySQL自动调用.主要用于满足复杂业务的规则和需求. 一.创建触发器 1.创建只有一个执行语句 ...
- tob toc tovc什么意思
先说一下TOB.TOC.TOVC的含义.B:business (企业)C:customer(消费者)VC:Venture Capital(风险投资) to b产品是根据公司战略或工作需要,构建生态体系 ...
- IDE0022 使用方法的表达式主体
这错误提示意思应该是:推荐您将此方法改为用“表达式主体”形式实现 所谓表达式主体,是类似 public void DisplayName() => Console.WriteLine(ToStr ...
- 关于JAVA架构师
在我们行业内,我们大致把程序员分为四级 1.初级Java程序员的重心在编写代码.运用框架: 2.中级Java程序员重心在编写代码和框架: 3.高级Java程序员技术攻关.性能调优: 4.架构师 解决业 ...
- 分布式消息队列RocketMQ--事务消息--解决分布式事务
说到分布式事务,就会谈到那个经典的”账号转账”问题:2个账号,分布处于2个不同的DB,或者说2个不同的子系统里面,A要扣钱,B要加钱,如何保证原子性? 一般的思路都是通过消息中间件来实现“最终一致性” ...