ubantu 16.4 Hadoop 完全分布式搭建
一个虚拟机
- 1.以 NAT网卡模式 装载虚拟机
- 2.最好将几个用到的虚拟机修改主机名,静态IP /etc/network/interface,这里 是 s101 s102 s103 三台主机 ubantu,改/etc/hostname文件
- 3.安装ssh
- 在第一台主机那里s101 创建公私密匙
- ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- >cd .ssh
- >cp id_rsa.pub >authorized_keys 创建密匙库
- 将id_rsa.pub传到其他主机上,到.ssh目录下
- 通过 服务端 nc -l 8888 >~/.ssh/authorized_keys
- 客户端 nc s102 8888 <id_rsa.pub
- 在第一台主机那里s101 创建公私密匙
开始安装Hadoop/jdk
- 安装VM-tools 方便从win 10 拖拉文件到ubantu
- 创建目录 /soft
- 改变组 chown ubantu:ubantu /soft 方便传输文件有权限
- 将文件放入到/soft (可以从桌面cp/mv src dst)
- tar -zxvf jdk或hadoop 自动创建解压目录
- 配置安装环境 (/etc/environment)
- 添加 JAVA_HOME=/soft/jdk-...jdk目录
- 添加 HADOOP_HOME=/soft/hadoop(Hadoop目录)
- 在path里面加/soft/jdk-...jdk/bin:/soft/hadoop/bin/:/soft/hadoop/sbin
- 通过 java -version 查看有版本号 成功
- hadoop version 有版本号 成功
开始配置HDFS四大文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101:9000</value>
</property> </configuration>
2.hdfs-site.xml
<configuration>
<!-- Configurations for NameNode: -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hdfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hdfs/data</value>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>s101:50090</value>
</property> <property>
<name>dfs.namenode.http-address</name>
<value>s101:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property> <property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/data/hdfs/checkpoint</value>
</property> <property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/data/hdfs/edits</value>
</property>
</configuration>
3. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s101</value>
</property>
</configuration>
到此成功一半。。。。。。。。。。。。。。
创建文件夹
mkdir /data/hdfs/tmp
mkdir /data/hdfs/var
mkdir /data/hdfs/logs
mkdir /data/hdfs/dfs
mkdir /data/hdfs/data
mkdir /data/hdfs/name
mkdir /data/hdfs/checkpoint
mkdir /data/hdfs/edits
记得将目录权限修改
- sudo chown ubantu:ubantu /data
接下来传输 /soft文件夹到其他主机
创建 xsync可执行文件
- sudo touch xsync
- sudo chmod 777 xsync 权限变成可执行文件
- sudo nano xsync
#!/bin/bash
pcount=$#
if((pcount<));then
echo no args;
exit;
fi p1=$;
fname=`basename $p1`
pdir=`cd -P $(dirname $p1);pwd` cuser=`whoami`
for((host= ; host< ;host=host+));do
echo --------s$host--------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done- xsync /soft-------->就会传文件夹到其他主机
- xsync /data
创建 xcall 向其他主机传命令
#!/bin/bash
pcount=$#
if((pcount<));then
echo no args;
exit;
fi
echo --------localhost-------- $@
for ((host=;host<;host=host+));do
echo --------$shost--------
ssh s$host $@
done
别着急 快结束了 哈
还得配置 workers问价
- 将需要配置成数据节点(DataNode)的主机名放入其中,一行一个
注意重点来了
- 先格式化 hadoop -namenode -format
- 再 启动 start-all.sh
- 查看进程 xcall jps
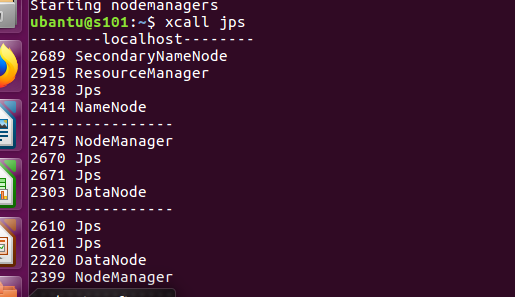
进入网页
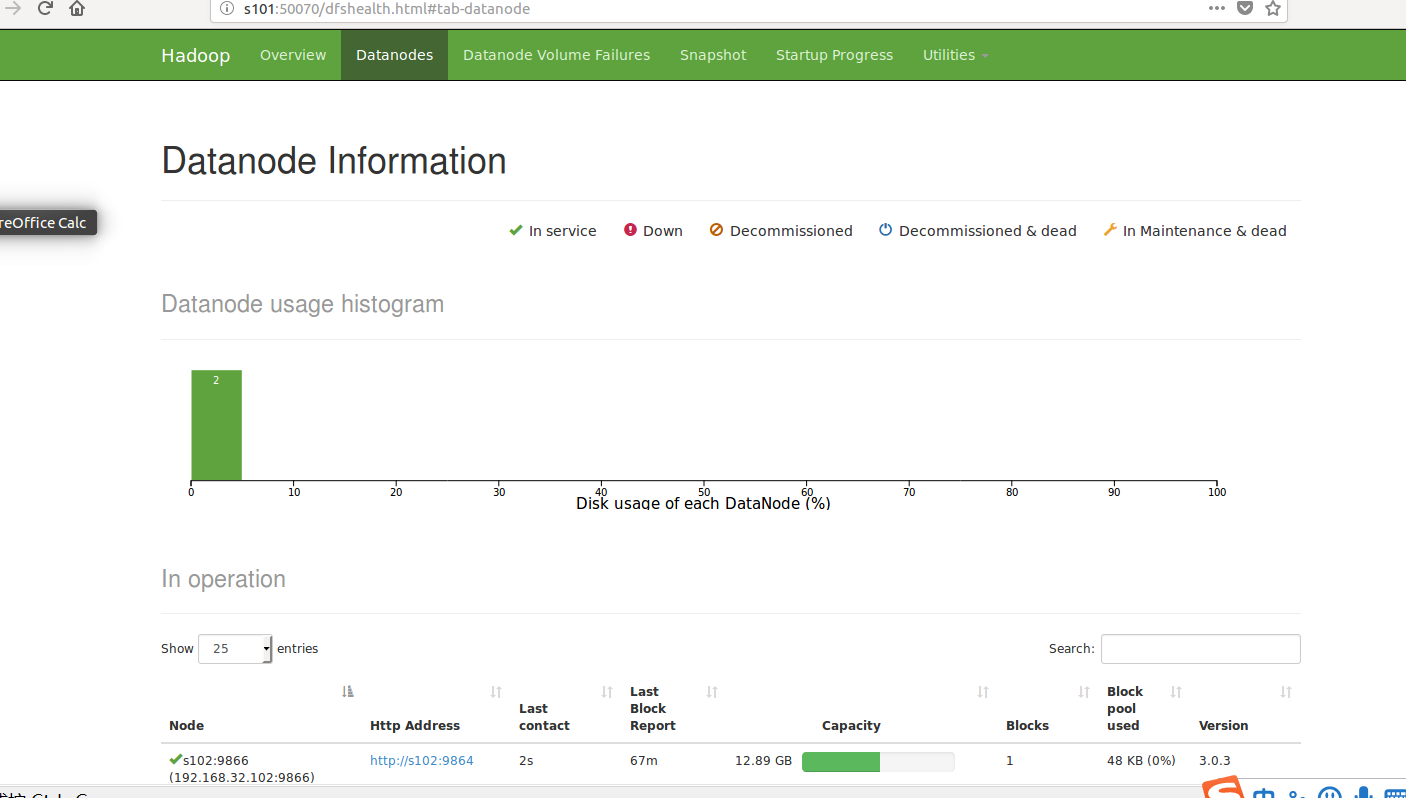
是不是很想牛泪,成功了耶!!!
中间出现了很多问题
1, rsync 权限不够 :删除文件夹 更改文件夹权限chown
2.学会看日志 log
ubantu 16.4 Hadoop 完全分布式搭建的更多相关文章
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- Hadoop 完全分布式搭建
搭建环境 https://www.cnblogs.com/YuanWeiBlogger/p/11456623.html 修改主机名------------------- 1./etc/hostname ...
- hadoop 伪分布式搭建
下载hadoop1.0.4版本,和jdk1.6版本或更高版本:1. 安装JDK,安装目录大家可以自定义,下面是我的安装目录: /usr/jdk1.6.0_22 配置环境变量: [root@hadoop ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- Hadoop完全分布式搭建流程
centos7 搭建完全分布式 Hadoop 环境 SSR 前言 本次教程是以先创建 四台虚拟机 为基础,再配置好一台虚拟机的情况下,直接复制文件到另外的虚拟机中(这样做大大简化了安装流程) 且本次 ...
随机推荐
- Nutch的nutch-default.xml和regex-urlfilter.txt的中文解释
nutch-default解释.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl&qu ...
- STL简洁 && c++读取cfg文件
在c++工程中,往往需要修改一些变量来实现不同的功能效果,这是cfg文件的使用可以使得工程更加高效与便利,这篇文章介绍的就是c++读取cfg文件的相关内容,以便及时总结和日后回顾. STL即标准模板库 ...
- MySQL笔记(5)---索引与算法
1.前言 本章记录MySQL中的索引机制,了解索引可以让数据库更快.索引太多会造成性能损耗,索引太少肯定查询效率不高. 2.InnoDB存储引擎所有概述 InnoDB中常见的索引有: B+树索引 全文 ...
- 六、CLR下的托管代码应用程序与非托管代码程序之间的性能对比
1.托管程序二次编译的问题,以及微软做的优化 五.CLR加载程序集代码时,JIT编译器对性能的产生的影响中介绍了CLR下托管应用程序的二次编译对性能产生的影响.事实上,在IL编译成本机代码的时候的时候 ...
- Centos配置vsftpd
#安装vsftpdyum install vsftpd #限制用户只能访问配置的目录,不能访问其他路径#修改vi /etc/vsftpd/vsftpd.conf chroot_list_enable= ...
- SQL Server性能优化(7)理解数据库文件组织
一.基本单位"页" SQL Server是用8KB的页来存储数据.物理I/O操作也是在页级执行.页的种类有很多,具体参考(MSDN).我们关注更多的是数据页的结构,包括三部 ...
- CentOS安装PHP7+Nginx+MySQL
本文属于动手搭建PHP开发环境的一部分,更多点击链接查看. 本文以centos6为例.命令部分均省略sudo命令. 安装PHP 下载 http://cn2.php.net/distributions/ ...
- tsung压力测试——Tsung测试统计报告说明【转】
1.主要统计信息 Tsung统计数据是平均每十秒重置一次,所以这里的响应时间(连接.请求.页面.会话)是指每十秒的平均响应时间: connect: 表示 每个连接持续时间: Hightest 10se ...
- [深入Maven源代码]maven绑定命令行参数到具体插件
maven的插件 我们知道Maven具体构建动作都是由插件执行的,maven本身只是提供一个框架,这样就提供了高度可定制化的功能,我们用maven命令执行比如mvn clean package这样的命 ...
- 让IIS Express 也支持外部链接