mongodb与mysql区别(超详细)
MySQL是关系型数据库。
优势:
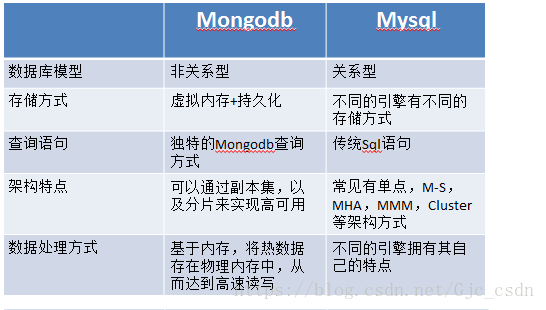
在不同的引擎上有不同 的存储方式。
查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
开源数据库的份额在不断增加,mysql的份额页在持续增长。
缺点:
在海量数据处理的时候效率会显著变慢。
Mongodb是非关系型数据库(nosql ),属于文档型数据库。文档是mongoDB中数据的基本单元,类似关系数据库的行,多个键值对有序地放置在一起便是文档,语法有点类似javascript面向对象的查询语言,它是一个面向集合的,模式自由的文档型数据库。
存储方式:虚拟内存+持久化。
查询语句:是独特的Mongodb的查询方式。
适合场景:事件的记录,内容管理或者博客平台等等。
架构特点:可以通过副本集,以及分片来实现高可用。
数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
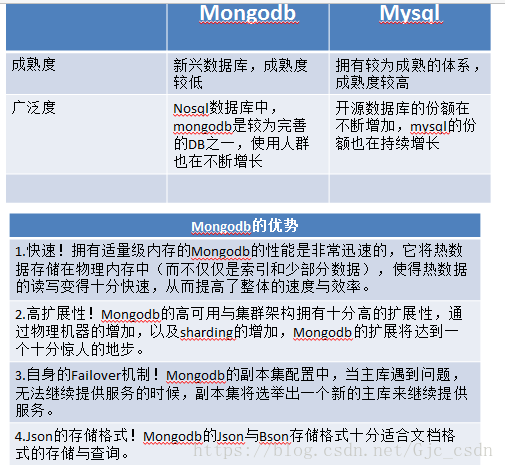
成熟度与广泛度:新兴数据库,成熟度较低,Nosql数据库中最为接近关系型数据库,比较完善的DB之一,适用人群不断在增长。
优点:
快速!在适量级的内存的Mongodb的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。高扩展性,存储的数据格式是json格式!
缺点:
不支持事务,而且开发文档不是很完全,完善。
Mysql和Mongodb主要应用场景
1.如果需要将mongodb作为后端db来代替mysql使用,即这里mysql与mongodb 属于平行级别,那么,这样的使用可能有以下几种情况的考量: (1)mongodb所负责部分以文档形式存储,能够有较好的代码亲和性,json格式的直接写入方便。(如日志之类) (2)从datamodels设计阶段就将原子性考虑于其中,无需事务之类的辅助。开发用如nodejs之类的语言来进行开发,对开发比较方便。 (3)mongodb本身的failover机制,无需使用如MHA之类的方式实现。
2.将mongodb作为类似redis ,memcache来做缓存db,为mysql提供服务,或是后端日志收集分析。 考虑到mongodb属于nosql型数据库,sql语句与数据结构不如mysql那么亲和 ,也会有很多时候将mongodb做为辅助mysql而使用的类redis memcache 之类的缓存db来使用。 亦或是仅作日志收集分析。
---------------------
What is NoSQL?
NoSQL encompasses a wide variety of different database technologies that were developed in response to the demands presented in building modern applications:
Developers are working with applications that create massive volumes of new, rapidly changing data types — structured, semi-structured, unstructured and polymorphic data.
Long gone is the twelve-to-eighteen month waterfall development cycle. Now small teams work in agile sprints, iterating quickly and pushing code every week or two, some even multiple times every day.
Applications that once served a finite audience are now delivered as services that must be always-on, accessible from many different devices and scaled globally to millions of users.
Organizations are now turning to scale-out architectures using open source software, commodity servers and cloud computing instead of large monolithic servers and storage infrastructure.
Relational databases were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the commodity storage and processing power available today.
Spin up a NoSQL cluster in minutes with the MongoDB Atlas: Hosted Database as a Service
Try out the easiest way to start learning and prototyping applications on MongoDB, the leading non-relational database.
Launching an application on any database typically requires careful planning to ensure performance, high availability, security, and disaster recovery – and these obligations continue as long as you run the application. With MongoDB Atlas, you receive all of the features of MongoDB without any of the operational heavy lifting, allowing you to focus instead on learning and building your apps. Features include:
On-demand, pay as you go model
Seamless upgrades and auto-healing
Fully elastic. Scale up and down with ease
Deep monitoring & customizable alerts
Highly secure by default
Continuous backups with point-in-time recovery
NoSQL Database Types
Document databases pair each key with a complex data structure known as a document. Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
Graph stores are used to store information about networks of data, such as social connections. Graph stores include Neo4J and Giraph.
Key-value stores are the simplest NoSQL databases. Every single item in the database is stored as an attribute name (or 'key'), together with its value. Examples of key-value stores are Riak and Berkeley DB. Some key-value stores, such as Redis, allow each value to have a type, such as 'integer', which adds functionality.
Wide-column stores such as Cassandra and HBase are optimized for queries over large datasets, and store columns of data together, instead of rows.
The Benefits of NoSQL
When compared to relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several issues that the relational model is not designed to address:
Large volumes of rapidly changing structured, semi-structured, and unstructured data
Agile sprints, quick schema iteration, and frequent code pushes
Object-oriented programming that is easy to use and flexible
Geographically distributed scale-out architecture instead of expensive, monolithic architecture
Read our free white paper: Top 5 Considerations When Evaluating NoSQL Databases and learn about:
Selecting the appropriate data model: document, key-value & wide column, or graph model
The pros and cons of consistent and eventually consistent systems
Why idiomatic drivers minimize onboarding time for new developers and simplify application development
Dynamic Schemas
Relational databases require that schemas be defined before you can add data. For example, you might want to store data about your customers such as phone numbers, first and last name, address, city and state – a SQL database needs to know what you are storing in advance.
This fits poorly with agile development approaches, because each time you complete new features, the schema of your database often needs to change. So if you decide, a few iterations into development, that you'd like to store customers' favorite items in addition to their addresses and phone numbers, you'll need to add that column to the database, and then migrate the entire database to the new schema.
If the database is large, this is a very slow process that involves significant downtime. If you are frequently changing the data your application stores – because you are iterating rapidly – this downtime may also be frequent. There's also no way, using a relational database, to effectively address data that's completely unstructured or unknown in advance.
NoSQL databases are built to allow the insertion of data without a predefined schema. That makes it easy to make significant application changes in real-time, without worrying about service interruptions – which means development is faster, code integration is more reliable, and less database administrator time is needed. Developers have typically had to add application-side code to enforce data quality controls, such as mandating the presence of specific fields, data types or permissible values. More sophisticated NoSQL databases allow validation rules to be applied within the database, allowing users to enforce governance across data, while maintaining the agility benefits of a dynamic schema.
Auto-sharding
Because of the way they are structured, relational databases usually scale vertically – a single server has to host the entire database to ensure acceptable performance for cross- table joins and transactions. This gets expensive quickly, places limits on scale, and creates a relatively small number of failure points for database infrastructure. The solution to support rapidly growing applications is to scale horizontally, by adding servers instead of concentrating more capacity in a single server.
'Sharding' a database across many server instances can be achieved with SQL databases, but usually is accomplished through SANs and other complex arrangements for making hardware act as a single server. Because the database does not provide this ability natively, development teams take on the work of deploying multiple relational databases across a number of machines. Data is stored in each database instance autonomously. Application code is developed to distribute the data, distribute queries, and aggregate the results of data across all of the database instances. Additional code must be developed to handle resource failures, to perform joins across the different databases, for data rebalancing, replication, and other requirements. Furthermore, many benefits of the relational database, such as transactional integrity, are compromised or eliminated when employing manual sharding.
NoSQL databases, on the other hand, usually support auto-sharding, meaning that they natively and automatically spread data across an arbitrary number of servers, without requiring the application to even be aware of the composition of the server pool. Data and query load are automatically balanced across servers, and when a server goes down, it can be quickly and transparently replaced with no application disruption.
Cloud computing makes this significantly easier, with providers such as Amazon Web Services providing virtually unlimited capacity on demand, and taking care of all the necessary infrastructure administration tasks. Developers no longer need to construct complex, expensive platforms to support their applications, and can concentrate on writing application code. Commodity servers can provide the same processing and storage capabilities as a single high-end server for a fraction of the price.
Replication
Most NoSQL databases also support automatic database replication to maintain availability in the event of outages or planned maintenance events. More sophisticated NoSQL databases are fully self-healing, offering automated failover and recovery, as well as the ability to distribute the database across multiple geographic regions to withstand regional failures and enable data localization. Unlike relational databases, NoSQL databases generally have no requirement for separate applications or expensive add-ons to implement replication.
Integrated Caching
A number of products provide a caching tier for SQL database systems. These systems can improve read performance substantially, but they do not improve write performance, and they add operational complexity to system deployments. If your application is dominated by reads then a distributed cache could be considered, but if your application has just a modest write volume, then a distributed cache may not improve the overall experience of your end users, and will add complexity in managing cache invalidation.
Many NoSQL database technologies have excellent integrated caching capabilities, keeping frequently-used data in system memory as much as possible and removing the need for a separate caching layer. Some NoSQL databases also offer fully managed, integrated in-memory database management layer for workloads demanding the highest throughput and lowest latency.
NoSQL vs. SQL Summary
| SQL Databases | NoSQL Databases | |
|---|---|---|
| Types | One type (SQL database) with minor variations | Many different types including key-value stores, document databases, wide-column stores, and graph databases |
| Development History | Developed in 1970s to deal with first wave of data storage applications | Developed in late 2000s to deal with limitations of SQL databases, especially scalability, multi-structured data, geo-distribution and agile development sprints |
| Examples | MySQL, Postgres, Microsoft SQL Server, Oracle Database | MongoDB, Cassandra, HBase, Neo4j |
| Data Storage Model | Individual records (e.g., 'employees') are stored as rows in tables, with each column storing a specific piece of data about that record (e.g., 'manager,' 'date hired,' etc.), much like a spreadsheet. Related data is stored in separate tables, and then joined together when more complex queries are executed. For example, 'offices' might be stored in one table, and 'employees' in another. When a user wants to find the work address of an employee, the database engine joins the 'employee' and 'office' tables together to get all the information necessary. | Varies based on database type. For example, key-value stores function similarly to SQL databases, but have only two columns ('key' and 'value'), with more complex information sometimes stored as BLOBs within the 'value' columns. Document databases do away with the table-and-row model altogether, storing all relevant data together in single 'document' in JSON, XML, or another format, which can nest values hierarchically. |
| Schemas | Structure and data types are fixed in advance. To store information about a new data item, the entire database must be altered, during which time the database must be taken offline. | Typically dynamic, with some enforcing data validation rules. Applications can add new fields on the fly, and unlike SQL table rows, dissimilar data can be stored together as necessary. For some databases (e.g., wide-column stores), it is somewhat more challenging to add new fields dynamically. |
| Scaling | Vertically, meaning a single server must be made increasingly powerful in order to deal with increased demand. It is possible to spread SQL databases over many servers, but significant additional engineering is generally required, and core relational features such as JOINs, referential integrity and transactions are typically lost. | Horizontally, meaning that to add capacity, a database administrator can simply add more commodity servers or cloud instances. The database automatically spreads data across servers as necessary. |
| Development Model | Mix of open-source (e.g., Postgres, MySQL) and closed source (e.g., Oracle Database) | Open-source |
| Supports multi-record ACID transactions | Yes | Mostly no. MongoDB 4.0 and beyond support multi-document ACID transactions. Learn more |
| Data Manipulation | Specific language using Select, Insert, and Update statements, e.g. SELECT fields FROM table WHERE… | Through object-oriented APIs |
| Consistency | Can be configured for strong consistency | Depends on product. Some provide strong consistency (e.g., MongoDB, with tunable consistency for reads) whereas others offer eventual consistency (e.g., Cassandra). |
Implementing a NoSQL Database
Often, organizations will begin with a small-scale trial of a NoSQL database in their organization, which makes it possible to develop an understanding of the technology in a low-stakes way. Most NoSQL databases are also open-source, meaning that they can be downloaded, implemented and scaled at little cost. Because development cycles are faster, organizations can also innovate more quickly and deliver superior customer experience at a lower cost.
As you consider alternatives to legacy infrastructures, you may have several motivations: to scale or perform beyond the capabilities of your existing system, identify viable alternatives to expensive proprietary software, or increase the speed and agility of development. When selecting the right database for your business and application, there are five important dimensions to consider.
Free White Paper
Read our free white paper:Top 5 Considerations When Evaluating NoSQL Databases and learn about:
Selecting the appropriate data model: document, key-value & wide column, or graph model
The pros and cons of consistent and eventually consistent systems
Why idiomatic drivers minimize onboarding time for new developers and simplify application development
mongodb与mysql区别(超详细)的更多相关文章
- Mongodb学习总结(2)——MongoDB与MySQL区别及其使用场景对比
对于只有SQL背景的人来说,想要深入研究NoSQL似乎是一个艰巨的任务,MySQL与MongoDB都是开源常用数据库,但是MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数 ...
- Linux服务器上迁移项目路径,修改nginx配置,迁移及备份MongoDB数据库流程 (超详细)!!!
缘由:客户服务器项目路径不是很合理,导致Jenkins自动部署时还需要添加路径后再更新部署,所以需要把项目路径统一和规范化. 迁移项目路径,保证路径合规,同时做好备份和迁移.迁移后先安装好依赖. 项目 ...
- spring中的web上下文,spring上下文,springmvc上下文区别(超详细)
web上下文(Servlet context),spring上下文(WebApplication Context),springmvc上下文(mlWebApplicationCont)之间区别. 上下 ...
- MongoDB之一介绍(MongoDB与MySQL的区别、BSON与JSON的区别)
MySQL与MongoDB的操作对比,以及区别 MySQL与MongoDB都是开源的常用数据库,但是MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数据库,是一种NoSQL ...
- Python-__builtin__与__builtins__的区别与关系(超详细,经典)(转)
Python-__builtin__与__builtins__的区别与关系(超详细,经典) (2013-07-23 15:27:32) 转载▼ 分类: Python 在学习Python时,很多人会 ...
- mongodb,redis,mysql的区别和具体应用场景
一.MySQL 关系型数据库. 在不同的引擎上有不同 的存储方式. 查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高. 开源数据库的份额在不断增加,mysql的份额页在持续增长. 缺点就 ...
- 超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数
超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数 介绍galera cluster原理的文章已经有一大堆了,百度几篇看一看就能有相关了解,这里就不赘述了.本文主 ...
- Linux系统部署JavaWeb项目(超详细tomcat,nginx,mysql)
转载自:Linux系统部署JavaWeb项目(超详细tomcat,nginx,mysql) 我的系统是阿里云的,香港的系统,本人选择的是系统镜像:CentOS 7.3 64位. 具体步骤: 配置Jav ...
- mongodb,redis,mysql的区别和具体应用场景(转)
一.MySQL 关系型数据库. 在不同的引擎上有不同 的存储方式. 查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高. 开源数据库的份额在不断增加,mysql的份额页在持续增长. 缺点就 ...
随机推荐
- linux只读文件系统
一般方法如下 首先试下重新挂载行不行 mount -o remount,rw /dev/sda3 不行的话用fsck,具体方法如下 1. mount命令查看变成只读文件的位置,比如/dev/sda32 ...
- 利用净现值(NPV)分析对比方案的可行性
最近在学经济管理方面课程,发现一个挺有意思的例题,mark一下. 题目描述 某投资项目有A.B两个方案,有关数据如下表,基准折现率为10%,请问那个方案较优? 项目 A方案 B方案 投资 15 3 年 ...
- MVC3学习:利用mvc3+ajax实现删除记录
首先根据模板生成list视图,上面就会有一个delete的链接,但是模板自带的这种删除,需要另外再打开一个删除页,再进行删除.我们可以利用ajax来改写,实现在当前页删除. 在视图上面,将原来的 @H ...
- Java中的日志管理
日志是应用程序运行中不可缺少的一部分,JAVA中有很多已经成熟的方案,尽管记录日志是应用开发中并不可少的功能,在 JDK 的最初版本中并不包含日志记录相关的 API 和实现.相关的 API(java. ...
- Spring Boot打包war jar 部署tomcat
概述 1.Spring Boot聚合工程打包war部署Tomcat 2.Spring Boot打包Jar,通过Java -jar直接运行. 3.提供完整pom.xml测试项目 至github 4.项目 ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装用来向微信好友发送消息的itchat库(图文详解)
不多说,直接上干货! Anaconda2 里 PS C:\Anaconda2\Scripts> PS C:\Anaconda2\Scripts> pip.exe install itch ...
- docker 非root用户修改mount到容器的文件出现“Operation not permitted
使用环境centos7 x86-64 内核版本4.19.9 docker使用非root用户启动,daemon.json配置文件内容如下: # cat daemon.json { "usern ...
- Vue + Element UI 实现权限管理系统 前端篇(二):Vue + Element 案例
导入项目 打开 Visual Studio Code,File --> add Folder to Workspace,导入我们的项目. 安装 Element 安装依赖 Element 是国内饿 ...
- 【IT笔试面试题整理】数组中出现次数超过一半的数字
[试题描述]数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字. [试题分析]时间复杂度O(n),空间复杂度O(1) 思路1: 创建一个hash_map,key为数组中的数,value为此数 ...
- 【K8S学习笔记】Part3:同一Pod中多个容器间使用共享卷进行通信
本文将展示如何使用共享卷(Volume)来实现相同Pod中的两个容器间通信. 注意:本文针对K8S的版本号为v1.9,其他版本可能会有少许不同. 0x00 准备工作 需要有一个K8S集群,并且配置好了 ...