[Spark RDD_1] RDD 基本概念
0. 说明
RDD 概述 && 创建 RDD 的方式 && RDD 编程 API(Transformation 和 Action Operations) && RDD 的依赖关系
1. RDD 概述
Spark 围绕弹性分布式数据集(RDD)的概念展开,RDD 是可以并行操作的容错的容错集合。
resilient distributed dataset,弹性分布式数据集。
不可变集合,可以进行并行操作的分区化数据集合。
该类包含了 RDD 常见操作,比如 map、filter、persist 等。
对于 key-value 的 RDD,会自动转换成(隐式转换)PairRDDFunction,该类提供了所有的 ByKey 操作。
内部,每个 RDD 主要含有 5 个主要属性:
- 分区列表(轻量级数据集合,没有实际数据)
- 计算每个切片的计算函数
- 和其他RDD的依赖列表
- 针对 K-V 类型 RDD,还有一个分区类(可选)
- 计算每个切片的首选位置列表(可选)
2. 创建 RDD 的方式
创建 RDD 有两种方法
【方法一】
并行化 驱动程序中的现有集合。
例子如下

【方法二】
引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase 或提供 Hadoop InputFormat 的任何数据源。
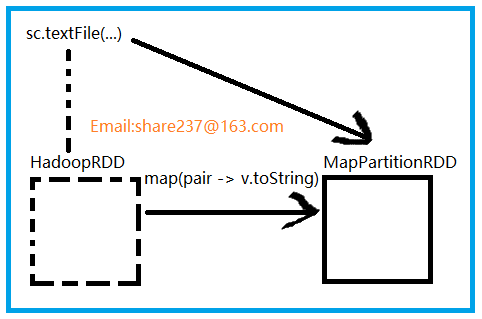
textFile() 方法最初创建的是 HadoopRDD,HadoopRDD 提供了读取 HDFS 文件核心功能。
sc.textFile()
产生了两个 RDD
HadoopRDD -> MapPartitionRDD
3. RDD 编程 API(Transformation 和 Action Operations)
【变换 Transformation】
返回值为新的 RDD
map
flatMap
filter()
reduceByKey()
【动作 Actions】
返回值为具体的值
collect()
save()
reduce()
count()
4. RDD 的依赖关系
【依赖】
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
【说明】
构造 RDD 时使用的是 One2OneDependency
[Spark RDD_1] RDD 基本概念的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- Spark中的一些概念
最近工作用到Spark,这里记一些自己接触到的Spark基本概念和知识. 本文链接:https://www.cnblogs.com/hhelibeb/p/10288915.html 名词 RDD:在高 ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- Spark之RDD的定义及五大特性
RDD是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象. RDD底层存储原理:其数据分布存储于多台机器上 ...
随机推荐
- BackgroundWorker简单实用(简便的异步操作)
微软提供了一个快捷使用多线程的帮助类BackgroundWorker,能够快速创建一个新的线程,并能报告进度,暂停,以及在线程完成后处理别的任务. 1.BackgroundWorker类介绍 1.1. ...
- *2 FastCGI sent in stderr: "PHP message: PHP Parse error: syntax error, unexpected '[' in /application/nginx-1.6.3/html/zabbix/index.php on line 32" while reading response header from upstream, clien
今天呢想学习一下zabbix监控一下我的服务情况,然后就开始安装我的zabbix服务,首先LNMP环境准备好了,Nginx版本为1.6.3,php版本为5.3.27,MySQL版本为二进制包安装的5. ...
- redis学习(五) redis过期时间
redis过期时间 1.redis过期时间介绍 有时候我们并不希望redis的key一直存在.例如缓存,验证码等数据,我们希望它们能在一定时间内自动的被销毁.redis提供了一些命令,能够让我们对ke ...
- 在Bootstrap框架中,form-control的效果
在Bootstrap框架中,通过定制了一个类名`form-control`,也就是说,如果这几个元素使用了类名“form-control”,将会实现一些设计上的定制效果. 1.宽度变成了100% 2. ...
- [转载] npm 一些操作
npm i module_name -S = > npm install module_name --save 写入到 dependencies 对象 npm i module_name -D ...
- VS_C#快捷键
Ctrl+E,D: 格式化全部代码 Ctrl+E,C / Ctrl+K,C: 注释选定内容 Ctrl+E,U / Ctrl+K,U: 取消选定注释内容 Ctrl+E,S: 查看空白 Ctrl+E,W: ...
- c#FTP应用---FileZilla Server
一.下载Filezilla Server 官网网址:https://filezilla-project.org FileZilla Server是目前稍有的免费FTP服务器软件,比起Serv-U F ...
- sql 中有关时间的语句
1.比较得到两个时间相差的间隔 SELECT datediff(minute, ’2009-04-28 12:05:00′, getdate()); SELECT datediff(month, ’2 ...
- JVM调优命令-jmap
jmap JVM Memory Map命令用于生成heap dump文件,如果不使用这个命令,还可以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候自动 ...
- Fragment的坑
http://www.jianshu.com/p/d9143a92ad94 使用add()加入fragment时将触发onAttach(),使用attach()不会触发onAttach() 使用rep ...