python数据分析Titanic_Survived预测
import pandas as pd
import matplotlib.pyplot as plt # matplotlib画图注释中文需要设置
from matplotlib.font_manager import FontProperties
titleYW_font_set = FontProperties(fname=r"c:\windows\fonts\Gabriola.ttf", size=15) test = pd.read_csv("test.csv")
train = pd.read_csv("train.csv")
gender_submission = pd.read_csv("gender_submission.csv") # print(test.head())
# print(train.head()) print(train.info()) # ----------------------------数据处理----------------------------- # 数据可视化 # # --------------对Name的处理----------------
# train_test_data = [train]
# for dataset in train_test_data:
# dataset['Title'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
# print(train['Title'].value_counts())
# # 统计名字前缀
#
# title_mapping = {"Mr": 0, "Miss": 1, "Mrs": 2,
# "Master": 3, "Dr": 3, "Rev": 3, "Col": 3, "Major": 3, "Mlle": 3,"Countess": 3,
# "Ms": 3, "Lady": 3, "Jonkheer": 3, "Don": 3, "Dona" : 3, "Mme": 3,"Capt": 3,"Sir": 3 }
# for dataset in train_test_data:
# dataset['Title'] = dataset['Title'].map(title_mapping) # --------------对Pclass的处理--------------
# 看看哪种乘客等级下的存活率高
train_pclass_0 = train['Pclass'][train['Survived'] == 0].value_counts()
train_pclass_1 = train['Pclass'][train['Survived'] == 1].value_counts()
train_pclass_01 = pd.concat([train_pclass_0, train_pclass_1], axis=1)
train_pclass_01.columns = ['Not_Surived', 'Survived']
train_pclass_01.plot(kind='bar', alpha=0.9)
plt.xticks([0, 1, 2], ['Pclass_1', 'Pclass_2', 'Pclass_3'], rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Pclass', size=20) # --------------对Sex的处理--------------
# 看看那种性别下的乘客存活率高
train_Sex_0 = train['Sex'][train['Survived'] == 0].value_counts()
train_Sex_1 = train['Sex'][train['Survived'] == 1].value_counts()
train_Sex_01 = pd.concat([train_Sex_0, train_Sex_1], axis=1)
train_Sex_01.columns = ['Not_Surived', 'Survived']
train_Sex_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Sex', size=20) # --------------对Embarked的处理--------------
# 看看那种登船港口下的乘客存活率高
train_Embarked_0 = train['Embarked'][train['Survived'] == 0].value_counts()
train_Embarked_1 = train['Embarked'][train['Survived'] == 1].value_counts()
train_Embarked_01 =pd.concat([train_Embarked_0, train_Embarked_1], axis=1)
train_Embarked_01.columns = ['Not_Surived', 'Survived']
train_Embarked_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Embarked', size=20) # 查看缺失值
# print(train.isnull().sum()) # 填补空缺值
train['Age'].fillna(train['Age'].median(), inplace=True) # print(train['Age'].describe()) # max80,min0.42
# --------------对Age的处理--------------
# 对年龄进行离散化,查看每一组的存活率
# 等宽离散化函数
bins = pd.IntervalIndex.from_tuples([(0, 13), (13, 26),(26,39), (39, 52), (52, 65), (65,90)])
train['Age_set'] = pd.cut(train['Age'], bins, labels=['child', 'Teenager', 'universe', 'Adults', 'elder', 'old man'])
# 看看那种年龄段的乘客存活率高
train_Age_set_0 = train['Age_set'][train['Survived'] == 0].value_counts()
train_Age_set_1 = train['Age_set'][train['Survived'] == 1].value_counts()
train_Age_set_01 =pd.concat([train_Age_set_0, train_Age_set_1], axis=1)
train_Age_set_01.columns = ['Not_Surived', 'Survived']
train_Age_set_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Age_Set', size=20) # --------------对SibSp和Parch的处理--------------
# 把SibSp与Parch相加
train['Family_N'] = train['Parch'] + train['SibSp']+1
# print(train[['Family_N', 'Survived']])
# 分组,按不同的家人数分组
bins = pd.IntervalIndex.from_tuples([(0, 1), (1, 2), (2, 20)])
train['Family_N'] = pd.cut(train['Family_N'], bins)
# 看看那种家庭人数的乘客存活率高
train_Family_N_0 = train['Family_N'][train['Survived'] == 0].value_counts()
train_Family_N_1 = train['Family_N'][train['Survived'] == 1].value_counts()
train_Family_N_01 = pd.concat([train_Family_N_0, train_Family_N_1], axis=1)
train_Family_N_01.columns = ['Not_Surived', 'Survived']
train_Family_N_01.plot(kind='bar', alpha=0.9)
plt.xticks([0, 1, 2], ['one', 'more_than_three', 'two'], rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Faminly_N', size=20)
# plt.show()
# train.info()
# train.drop(['SibSp', 'Parch', 'Ticket'], axis=1, inplace=True) # --------------对Cabin的处理--------------
# 对已知的Cbiin进行分组,聚合时采用众数的方法
# 这里构建数据透视表即可
train_notna = train.dropna()
train_C_F = pd.pivot_table(data=train_notna[['Cabin', 'Fare']], index='Cabin', values='Fare',
aggfunc=lambda x: x.mode())
# print(train_C_F)
# 发现众数可能不止一个,所以进行分离众数的操作
for i in range(train_C_F.shape[0]):
if type(train_C_F['Fare'][i]) != type(train_C_F['Fare'][1]):
train_C_F['Fare'][i] = train_C_F['Fare'][i][0] # 对众数进行排序
train_C_F_sort = train_C_F.sort_values(by=['Fare'])
# print(train_C_F_sort)
# 对缺失的Cabin进行填补
# 首先找出空白处
train_bool = train['Cabin'].isnull()
# print(train_bool)
na_index = train_bool[train_bool == True].index # 从上述的index来赋予客舱位置
for i in na_index:
for j in range(train_C_F_sort.shape[0]):
if train['Fare'][i] <= train_C_F_sort['Fare'][j]:
train['Cabin'][i] = train_C_F_sort.index[j]
break # print(train['Cabin'])
# ----------------------------------------------------------------- # 查看列名
# print(train.columns) # # 提取出训练集
X_train = train.drop(['Survived', 'PassengerId', 'Name', 'Age','Fare','SibSp', 'Parch', 'Ticket'], axis=1)
# X_train = train.drop(['Survived', 'PassengerId', 'Name', 'Age_set', 'SibSp', 'Parch', 'Ticket'], axis=1)
Y_train = train['Survived'] # print(X_train.columns)
# 哑变量处理
# 把空白值也当作变量处理
X_train = pd.get_dummies(X_train, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Age_set', 'Family_N'],
dummy_na=True) # X_train = pd.get_dummies(X_train, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Family_N'],
# dummy_na=True) X = X_train
y = Y_train
# 数据集划分
from sklearn.model_selection import train_test_split # 标准化
# X_train['Age'].transform(lambda x: (x - x.min())/(x.max()-x.min()))
# X_train['Fare'].transform(lambda x: (x - x.min())/(x.max()-x.min())) X_train, X_test, y_train, y_test = train_test_split(X_train,Y_train, test_size=0.2, random_state=123) # # 标准化
# from sklearn.preprocessing import StandardScaler
# Standard = StandardScaler().fit(X_train) # 训练产生标准化的规则,因为数据集分为训练与测试,测试相当于后来的。
#
# Xtrain = Standard.transform(X_train) # 将规则应用于训练集
# Xtest = Standard.transform(X_test) # 将规则应用于测试集 # 进行分类算法
# from sklearn.ensemble import GradientBoostingClassifier
# from sklearn import linear_model
from sklearn.neighbors import KNeighborsClassifier
# clf = GradientBoostingClassifier().fit(X_train, y_train)
# clf = linear_model.SGDClassifier().fit(Xtrain, y_train)
clf = KNeighborsClassifier(n_neighbors=10).fit(X_train,y_train)
y_pred =clf.predict(X_test)
# y_pred = clf.predict(Xtest)
# clf = linear_model.SGDClassifier().fit(X_train, y_train)
# y_pred = clf.predict(X_test) # 判定分类算法
from sklearn.metrics import classification_report, auc
print(classification_report(y_test, y_pred)) # 绘制roc曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 改字体
# 求出ROC曲线的x轴和Y轴
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print(auc(fpr, tpr))
plt.figure(figsize=(10, 6))
plt.xlim(0, 1) # 设定x轴的范围
plt.ylim(0.0, 1.1) # 设定y轴的范围
plt.xlabel('假正率')
plt.ylabel('真正率')
plt.plot(fpr, tpr, linewidth=2, linestyle="-", color='red')
plt.title('Line Roc of X_train by estimator KNN', size=20)
# plt.show() # # 交叉验证
# from sklearn.cross_validation import cross_val_score
# k_score = []
# for i in range(1,50):
# knn = KNeighborsClassifier(n_neighbors=i)
# score = cross_val_score(knn,X,y,scoring='accuracy',cv=5)
# k_score.append(score.mean())
# print(k_score) # ----------------------------------------------------------------------------
# 测试test # 对测试集做与训练集类似的操作 # 填补空缺值
test['Age'].fillna(test['Age'].median(), inplace=True) # test.info()
# 寻找Fare空值
# tt = test['Fare'].isnull()
# print(tt.sort_values()) 空值index为152 # print(test[151:153][['Fare','Cabin']]) # 发现此行数据fare 与 cabin均为空,所以授予其Cabin为随便一个即可,或者删除
test.dropna(subset=['Fare'],inplace=True) # 对age离散化时必须以训练集的规则
# test.info()
# --------------对Age的处理--------------
# 对年龄进行离散化,查看每一组的存活率
# 等宽离散化函数
bins = pd.IntervalIndex.from_tuples([(0, 13), (13, 26),(26,39),(39, 52), (52, 65), (65,90)])
test['Age_set'] = pd.cut(test['Age'], bins, labels=['child', 'Teenager', 'universe', 'Adults', 'elder', 'old man']) # test.info() # --------------对SibSp和Parch的处理--------------
# 把SibSp与Parch相加
test['Family_N'] = test['Parch'] + test['SibSp']+1
# print(train[['Family_N', 'Survived']])
# 分组,按不同的家人数分组
bins = pd.IntervalIndex.from_tuples([(0, 1), (1, 2), (2, 20)])
test['Family_N'] = pd.cut(test['Family_N'], bins) # 对缺失的Cabin进行填补
# 首先找出空白处
test_bool = test['Cabin'].isnull()
# print(train_bool)
na_index = test_bool[test_bool == True].index # 从上述的index来赋予客舱位置
for i in na_index:
for j in range(train_C_F_sort.shape[0]):
if test['Fare'][i] <= train_C_F_sort['Fare'][j]:
test['Cabin'][i] = train_C_F_sort.index[j]
break
# print(train['Cabin']) # test.info() X_test = test.drop(['PassengerId', 'Name', 'Age','Fare','SibSp', 'Parch', 'Ticket'], axis=1) y_test = gender_submission.drop(index=152)
y_test = y_test['Survived'].values # 哑变量处理
# 把空白值也当作变量处理
X_test = pd.get_dummies(X_test, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Age_set', 'Family_N'],
dummy_na=True) X.info()
# 发现维数不一样。所以应该对X_test添加一群0列,并且排号列序,必须与X_train(X)一致。 for i in X_test.columns:
if i not in X.columns:
X[i] = 0 for i in X.columns:
if i not in X_test.columns:
X_test[i] = 0
# X_test.info()
# X_train.info()
X_test = X_test[X.columns] X_train, XTrain_test, y_train, ytrain_test = train_test_split(X,y, test_size=0.2, random_state=123)
clf = KNeighborsClassifier(n_neighbors=10).fit(X_train,y_train)
y_pred =clf.predict(X_test) print(y_pred)
print(y_test) # 判定分类算法
from sklearn.metrics import classification_report, auc
print(classification_report(y_test, y_pred)) # 绘制roc曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 改字体
# 求出ROC曲线的x轴和Y轴
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print(auc(fpr, tpr))
plt.figure(figsize=(10, 6))
plt.xlim(0, 1) # 设定x轴的范围
plt.ylim(0.0, 1.1) # 设定y轴的范围
plt.xlabel('假正率')
plt.ylabel('真正率')
plt.plot(fpr, tpr, linewidth=2, linestyle="-", color='red')
plt.title('Line Roc of X_train by estimator KNN', size=20)
plt.show() ---------------------------------结果-----------------------------------------------
训练模型的roc曲线如下:
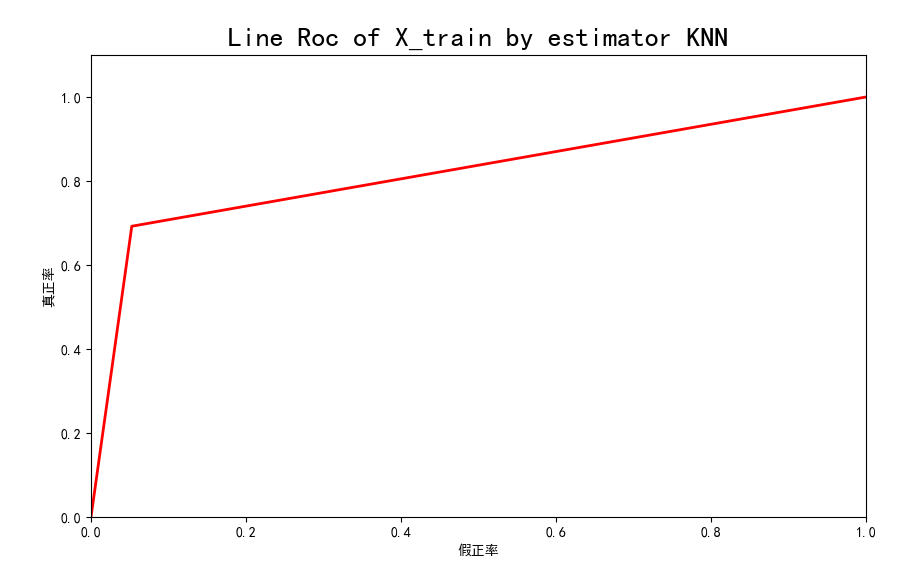
训练模型的召回率和精准率和roc曲线积分值如下:
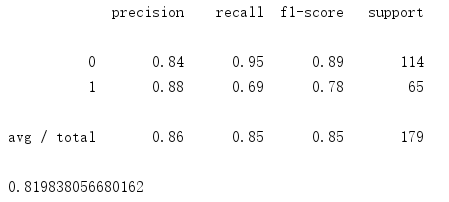
测试模型的roc曲线如下:
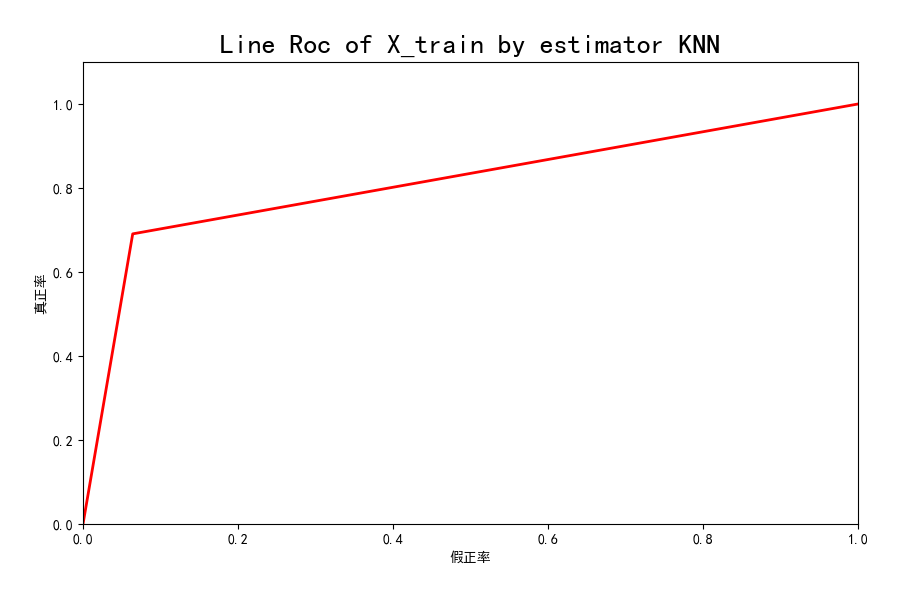
训练模型的召回率和精准率和roc曲线积分值如下:
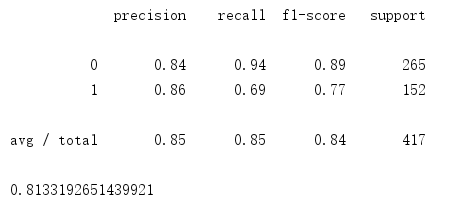
用来测试的survived如下:

训练模型得到的预测结果如下:

计算预测与实际的准确率:
k=0
# 有417个样本待预测
for i in range(417):
if y_test[i] == y_pred[i]:
k=k+1
print(k/417)
得到结果:
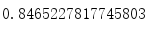
准确率有大约84.65%。
python数据分析Titanic_Survived预测的更多相关文章
- python数据分析Adult-Salary预测
具体文档戳下方网站 https://pan.wps.cn/l/s4ojed8 代码如下: import pandas as pdimport numpy as npimport matplotlib. ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- 小象学院Python数据分析第二期【升级版】
点击了解更多Python课程>>> 小象学院Python数据分析第二期[升级版] 主讲老师: 梁斌 资深算法工程师 查尔斯特大学(Charles Sturt University)计 ...
- Python数据分析【炼数成金15周完整课程】
点击了解更多Python课程>>> Python数据分析[炼数成金15周完整课程] 课程简介: Python是一种面向对象.直译式计算机程序设计语言.也是一种功能强大而完善的通用型语 ...
- Python数据分析简介
1,Python作为一门编程语言开发效率快,运行效率被人诟病,但是Python核心部分使用c/c++等更高效的语言来编写的还有强大的numpy, padnas, matplotlib,scipy库等应 ...
- Python数据分析常用的库总结
Python之所以能够成为数据分析与挖掘领域的最佳语言,是有其独特的优势的.因为他有很多这个领域相关的库可以用,而且很好用,比如Numpy.SciPy.Matploglib.Pandas.Scikit ...
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...
- python数据分析与应用
python数据分析与应用笔记 使用sklearn构建模型 1.使用sklearn转换器处理数据 import numpy as np from sklearn.datasets import loa ...
随机推荐
- 线程相关代码分析->常见面试题(一、Thead类)
As always,我们直接看jdk的代码切入: 首先是最简单的Runnable接口: public interface Runnable { public abstract void run(); ...
- Android开发之jdk安装及环境变量配置
然后开始配置环境变量,JAVA_HOME,Path和classpath三部分: (1)在变量名输入框中写入“JAVA_HOME”,在变量值输入框中写入“C:\Program Files\Java\jd ...
- WorldWind源码剖析系列:可渲染对象类RenderableObject
RenderableObject是WorldWind中所有需要渲染的对象的父类,继承了接口IRenderable和Icomparable.其派生类体系如下所示.RenderableObject的成员如 ...
- OpenCV——KAZE、AKAZE特征检测、匹配与对象查找
AKAZE是KAZE的加速版 特征点查找和绘制:把surf中的surf改成KAZE或AKAZE即可 #include <opencv2/opencv.hpp> #include < ...
- JAVA框架Struts2 结果页配置
一: Action类的返回逻辑视图,一般会出现一个场景就是:当前package 标签下,几个action类需要返回同一个页面的时候.这个时候需要全局结果. 全局结果(使用标签<global-re ...
- Oracle 批量修改某个用户下表的表空间
说明:一般来说要修改表的表空间需要同时修改表的表空间和其对应的索引表空间,并且在修改含有BOLB字段的表的表空间时又不一样,具体请参考末尾的链接 思路:拼凑一个满足条件的批处理查询语句,将查询的结果复 ...
- 常用的php数组函数
以下是自己比较常用的数组函数 数组元素增加减少array_pusharray_poparray_shiftarray_unshift array_splice (对数组的增删改) array_sli ...
- 虚拟机上不能使用CUDA
虚拟机的显卡是虚拟的,不能使用CUDA(至少很难),搞了一天才晃过神来: lspci 查找目前主机的硬件配备 用 grep -i 进行大小写无关的搜索
- HUE配置HBase
HBase的配置 修改配置hue.ini的配置文件 [hbase] hbase_clusters=(Cluster|node1:) hbase_conf_dir=/usr/hbase-0.98.12. ...
- Swoole Timer 的应用
目录 你好,Swoole Timer 应用场景 参考文档 你好,Swoole PHP 的协程高性能网络通信引擎,使用 C/C++ 语言编写,提供了多种通信协议的网络服务器和客户端模块. Swoole ...