python数据分析Titanic_Survived预测
import pandas as pd
import matplotlib.pyplot as plt # matplotlib画图注释中文需要设置
from matplotlib.font_manager import FontProperties
titleYW_font_set = FontProperties(fname=r"c:\windows\fonts\Gabriola.ttf", size=15) test = pd.read_csv("test.csv")
train = pd.read_csv("train.csv")
gender_submission = pd.read_csv("gender_submission.csv") # print(test.head())
# print(train.head()) print(train.info()) # ----------------------------数据处理----------------------------- # 数据可视化 # # --------------对Name的处理----------------
# train_test_data = [train]
# for dataset in train_test_data:
# dataset['Title'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
# print(train['Title'].value_counts())
# # 统计名字前缀
#
# title_mapping = {"Mr": 0, "Miss": 1, "Mrs": 2,
# "Master": 3, "Dr": 3, "Rev": 3, "Col": 3, "Major": 3, "Mlle": 3,"Countess": 3,
# "Ms": 3, "Lady": 3, "Jonkheer": 3, "Don": 3, "Dona" : 3, "Mme": 3,"Capt": 3,"Sir": 3 }
# for dataset in train_test_data:
# dataset['Title'] = dataset['Title'].map(title_mapping) # --------------对Pclass的处理--------------
# 看看哪种乘客等级下的存活率高
train_pclass_0 = train['Pclass'][train['Survived'] == 0].value_counts()
train_pclass_1 = train['Pclass'][train['Survived'] == 1].value_counts()
train_pclass_01 = pd.concat([train_pclass_0, train_pclass_1], axis=1)
train_pclass_01.columns = ['Not_Surived', 'Survived']
train_pclass_01.plot(kind='bar', alpha=0.9)
plt.xticks([0, 1, 2], ['Pclass_1', 'Pclass_2', 'Pclass_3'], rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Pclass', size=20) # --------------对Sex的处理--------------
# 看看那种性别下的乘客存活率高
train_Sex_0 = train['Sex'][train['Survived'] == 0].value_counts()
train_Sex_1 = train['Sex'][train['Survived'] == 1].value_counts()
train_Sex_01 = pd.concat([train_Sex_0, train_Sex_1], axis=1)
train_Sex_01.columns = ['Not_Surived', 'Survived']
train_Sex_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Sex', size=20) # --------------对Embarked的处理--------------
# 看看那种登船港口下的乘客存活率高
train_Embarked_0 = train['Embarked'][train['Survived'] == 0].value_counts()
train_Embarked_1 = train['Embarked'][train['Survived'] == 1].value_counts()
train_Embarked_01 =pd.concat([train_Embarked_0, train_Embarked_1], axis=1)
train_Embarked_01.columns = ['Not_Surived', 'Survived']
train_Embarked_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Embarked', size=20) # 查看缺失值
# print(train.isnull().sum()) # 填补空缺值
train['Age'].fillna(train['Age'].median(), inplace=True) # print(train['Age'].describe()) # max80,min0.42
# --------------对Age的处理--------------
# 对年龄进行离散化,查看每一组的存活率
# 等宽离散化函数
bins = pd.IntervalIndex.from_tuples([(0, 13), (13, 26),(26,39), (39, 52), (52, 65), (65,90)])
train['Age_set'] = pd.cut(train['Age'], bins, labels=['child', 'Teenager', 'universe', 'Adults', 'elder', 'old man'])
# 看看那种年龄段的乘客存活率高
train_Age_set_0 = train['Age_set'][train['Survived'] == 0].value_counts()
train_Age_set_1 = train['Age_set'][train['Survived'] == 1].value_counts()
train_Age_set_01 =pd.concat([train_Age_set_0, train_Age_set_1], axis=1)
train_Age_set_01.columns = ['Not_Surived', 'Survived']
train_Age_set_01.plot(kind='bar', alpha=0.9)
plt.xticks(rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Age_Set', size=20) # --------------对SibSp和Parch的处理--------------
# 把SibSp与Parch相加
train['Family_N'] = train['Parch'] + train['SibSp']+1
# print(train[['Family_N', 'Survived']])
# 分组,按不同的家人数分组
bins = pd.IntervalIndex.from_tuples([(0, 1), (1, 2), (2, 20)])
train['Family_N'] = pd.cut(train['Family_N'], bins)
# 看看那种家庭人数的乘客存活率高
train_Family_N_0 = train['Family_N'][train['Survived'] == 0].value_counts()
train_Family_N_1 = train['Family_N'][train['Survived'] == 1].value_counts()
train_Family_N_01 = pd.concat([train_Family_N_0, train_Family_N_1], axis=1)
train_Family_N_01.columns = ['Not_Surived', 'Survived']
train_Family_N_01.plot(kind='bar', alpha=0.9)
plt.xticks([0, 1, 2], ['one', 'more_than_three', 'two'], rotation=0)
plt.grid(linestyle="--", color="green", alpha=0.5)
plt.title('Survived_Rate in Faminly_N', size=20)
# plt.show()
# train.info()
# train.drop(['SibSp', 'Parch', 'Ticket'], axis=1, inplace=True) # --------------对Cabin的处理--------------
# 对已知的Cbiin进行分组,聚合时采用众数的方法
# 这里构建数据透视表即可
train_notna = train.dropna()
train_C_F = pd.pivot_table(data=train_notna[['Cabin', 'Fare']], index='Cabin', values='Fare',
aggfunc=lambda x: x.mode())
# print(train_C_F)
# 发现众数可能不止一个,所以进行分离众数的操作
for i in range(train_C_F.shape[0]):
if type(train_C_F['Fare'][i]) != type(train_C_F['Fare'][1]):
train_C_F['Fare'][i] = train_C_F['Fare'][i][0] # 对众数进行排序
train_C_F_sort = train_C_F.sort_values(by=['Fare'])
# print(train_C_F_sort)
# 对缺失的Cabin进行填补
# 首先找出空白处
train_bool = train['Cabin'].isnull()
# print(train_bool)
na_index = train_bool[train_bool == True].index # 从上述的index来赋予客舱位置
for i in na_index:
for j in range(train_C_F_sort.shape[0]):
if train['Fare'][i] <= train_C_F_sort['Fare'][j]:
train['Cabin'][i] = train_C_F_sort.index[j]
break # print(train['Cabin'])
# ----------------------------------------------------------------- # 查看列名
# print(train.columns) # # 提取出训练集
X_train = train.drop(['Survived', 'PassengerId', 'Name', 'Age','Fare','SibSp', 'Parch', 'Ticket'], axis=1)
# X_train = train.drop(['Survived', 'PassengerId', 'Name', 'Age_set', 'SibSp', 'Parch', 'Ticket'], axis=1)
Y_train = train['Survived'] # print(X_train.columns)
# 哑变量处理
# 把空白值也当作变量处理
X_train = pd.get_dummies(X_train, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Age_set', 'Family_N'],
dummy_na=True) # X_train = pd.get_dummies(X_train, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Family_N'],
# dummy_na=True) X = X_train
y = Y_train
# 数据集划分
from sklearn.model_selection import train_test_split # 标准化
# X_train['Age'].transform(lambda x: (x - x.min())/(x.max()-x.min()))
# X_train['Fare'].transform(lambda x: (x - x.min())/(x.max()-x.min())) X_train, X_test, y_train, y_test = train_test_split(X_train,Y_train, test_size=0.2, random_state=123) # # 标准化
# from sklearn.preprocessing import StandardScaler
# Standard = StandardScaler().fit(X_train) # 训练产生标准化的规则,因为数据集分为训练与测试,测试相当于后来的。
#
# Xtrain = Standard.transform(X_train) # 将规则应用于训练集
# Xtest = Standard.transform(X_test) # 将规则应用于测试集 # 进行分类算法
# from sklearn.ensemble import GradientBoostingClassifier
# from sklearn import linear_model
from sklearn.neighbors import KNeighborsClassifier
# clf = GradientBoostingClassifier().fit(X_train, y_train)
# clf = linear_model.SGDClassifier().fit(Xtrain, y_train)
clf = KNeighborsClassifier(n_neighbors=10).fit(X_train,y_train)
y_pred =clf.predict(X_test)
# y_pred = clf.predict(Xtest)
# clf = linear_model.SGDClassifier().fit(X_train, y_train)
# y_pred = clf.predict(X_test) # 判定分类算法
from sklearn.metrics import classification_report, auc
print(classification_report(y_test, y_pred)) # 绘制roc曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 改字体
# 求出ROC曲线的x轴和Y轴
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print(auc(fpr, tpr))
plt.figure(figsize=(10, 6))
plt.xlim(0, 1) # 设定x轴的范围
plt.ylim(0.0, 1.1) # 设定y轴的范围
plt.xlabel('假正率')
plt.ylabel('真正率')
plt.plot(fpr, tpr, linewidth=2, linestyle="-", color='red')
plt.title('Line Roc of X_train by estimator KNN', size=20)
# plt.show() # # 交叉验证
# from sklearn.cross_validation import cross_val_score
# k_score = []
# for i in range(1,50):
# knn = KNeighborsClassifier(n_neighbors=i)
# score = cross_val_score(knn,X,y,scoring='accuracy',cv=5)
# k_score.append(score.mean())
# print(k_score) # ----------------------------------------------------------------------------
# 测试test # 对测试集做与训练集类似的操作 # 填补空缺值
test['Age'].fillna(test['Age'].median(), inplace=True) # test.info()
# 寻找Fare空值
# tt = test['Fare'].isnull()
# print(tt.sort_values()) 空值index为152 # print(test[151:153][['Fare','Cabin']]) # 发现此行数据fare 与 cabin均为空,所以授予其Cabin为随便一个即可,或者删除
test.dropna(subset=['Fare'],inplace=True) # 对age离散化时必须以训练集的规则
# test.info()
# --------------对Age的处理--------------
# 对年龄进行离散化,查看每一组的存活率
# 等宽离散化函数
bins = pd.IntervalIndex.from_tuples([(0, 13), (13, 26),(26,39),(39, 52), (52, 65), (65,90)])
test['Age_set'] = pd.cut(test['Age'], bins, labels=['child', 'Teenager', 'universe', 'Adults', 'elder', 'old man']) # test.info() # --------------对SibSp和Parch的处理--------------
# 把SibSp与Parch相加
test['Family_N'] = test['Parch'] + test['SibSp']+1
# print(train[['Family_N', 'Survived']])
# 分组,按不同的家人数分组
bins = pd.IntervalIndex.from_tuples([(0, 1), (1, 2), (2, 20)])
test['Family_N'] = pd.cut(test['Family_N'], bins) # 对缺失的Cabin进行填补
# 首先找出空白处
test_bool = test['Cabin'].isnull()
# print(train_bool)
na_index = test_bool[test_bool == True].index # 从上述的index来赋予客舱位置
for i in na_index:
for j in range(train_C_F_sort.shape[0]):
if test['Fare'][i] <= train_C_F_sort['Fare'][j]:
test['Cabin'][i] = train_C_F_sort.index[j]
break
# print(train['Cabin']) # test.info() X_test = test.drop(['PassengerId', 'Name', 'Age','Fare','SibSp', 'Parch', 'Ticket'], axis=1) y_test = gender_submission.drop(index=152)
y_test = y_test['Survived'].values # 哑变量处理
# 把空白值也当作变量处理
X_test = pd.get_dummies(X_test, columns=['Pclass', 'Sex', 'Cabin', 'Embarked', 'Age_set', 'Family_N'],
dummy_na=True) X.info()
# 发现维数不一样。所以应该对X_test添加一群0列,并且排号列序,必须与X_train(X)一致。 for i in X_test.columns:
if i not in X.columns:
X[i] = 0 for i in X.columns:
if i not in X_test.columns:
X_test[i] = 0
# X_test.info()
# X_train.info()
X_test = X_test[X.columns] X_train, XTrain_test, y_train, ytrain_test = train_test_split(X,y, test_size=0.2, random_state=123)
clf = KNeighborsClassifier(n_neighbors=10).fit(X_train,y_train)
y_pred =clf.predict(X_test) print(y_pred)
print(y_test) # 判定分类算法
from sklearn.metrics import classification_report, auc
print(classification_report(y_test, y_pred)) # 绘制roc曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 改字体
# 求出ROC曲线的x轴和Y轴
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print(auc(fpr, tpr))
plt.figure(figsize=(10, 6))
plt.xlim(0, 1) # 设定x轴的范围
plt.ylim(0.0, 1.1) # 设定y轴的范围
plt.xlabel('假正率')
plt.ylabel('真正率')
plt.plot(fpr, tpr, linewidth=2, linestyle="-", color='red')
plt.title('Line Roc of X_train by estimator KNN', size=20)
plt.show() ---------------------------------结果-----------------------------------------------
训练模型的roc曲线如下:
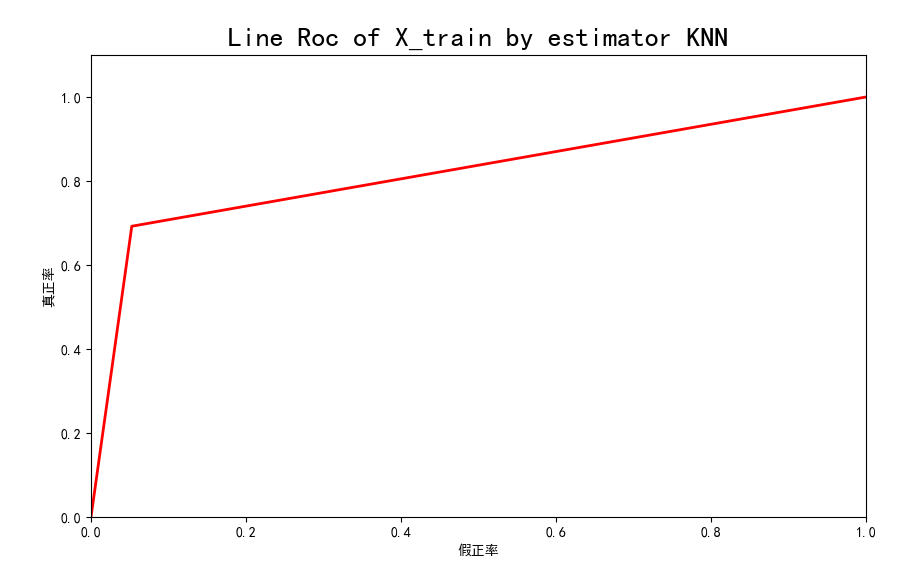
训练模型的召回率和精准率和roc曲线积分值如下:
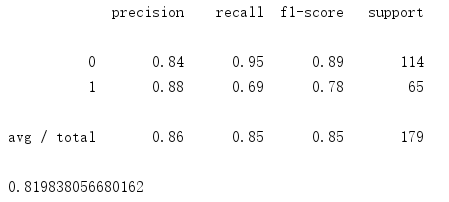
测试模型的roc曲线如下:
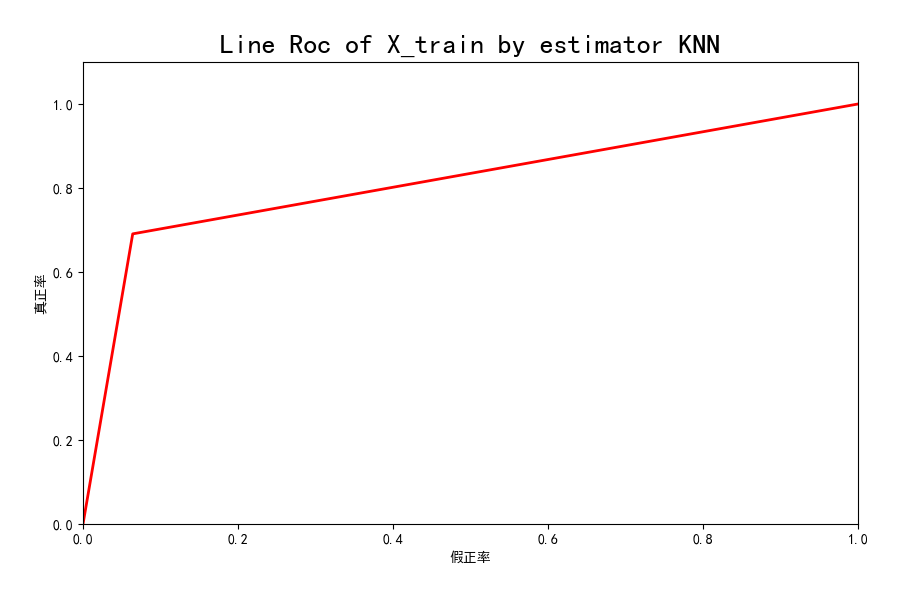
训练模型的召回率和精准率和roc曲线积分值如下:
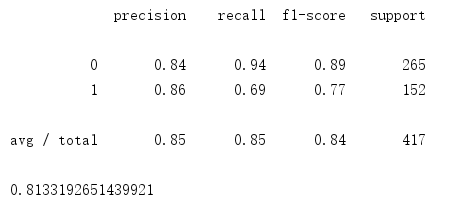
用来测试的survived如下:

训练模型得到的预测结果如下:

计算预测与实际的准确率:
k=0
# 有417个样本待预测
for i in range(417):
if y_test[i] == y_pred[i]:
k=k+1
print(k/417)
得到结果:
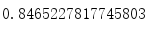
准确率有大约84.65%。
python数据分析Titanic_Survived预测的更多相关文章
- python数据分析Adult-Salary预测
具体文档戳下方网站 https://pan.wps.cn/l/s4ojed8 代码如下: import pandas as pdimport numpy as npimport matplotlib. ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- 小象学院Python数据分析第二期【升级版】
点击了解更多Python课程>>> 小象学院Python数据分析第二期[升级版] 主讲老师: 梁斌 资深算法工程师 查尔斯特大学(Charles Sturt University)计 ...
- Python数据分析【炼数成金15周完整课程】
点击了解更多Python课程>>> Python数据分析[炼数成金15周完整课程] 课程简介: Python是一种面向对象.直译式计算机程序设计语言.也是一种功能强大而完善的通用型语 ...
- Python数据分析简介
1,Python作为一门编程语言开发效率快,运行效率被人诟病,但是Python核心部分使用c/c++等更高效的语言来编写的还有强大的numpy, padnas, matplotlib,scipy库等应 ...
- Python数据分析常用的库总结
Python之所以能够成为数据分析与挖掘领域的最佳语言,是有其独特的优势的.因为他有很多这个领域相关的库可以用,而且很好用,比如Numpy.SciPy.Matploglib.Pandas.Scikit ...
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...
- python数据分析与应用
python数据分析与应用笔记 使用sklearn构建模型 1.使用sklearn转换器处理数据 import numpy as np from sklearn.datasets import loa ...
随机推荐
- Android与js交互拍照上传资料
应用场景:h5通知android端拍照,选相册,然后将图片路径上传成功之后,获取到网络路径,将此路径返还给h5界面,并展示出来. android与js快速交互 效果图如下: 1.在Activity ...
- 抽象类、final关键字、多态
1.1 抽象类 1.1.1 抽象类概念 C extends B,B extends A,在继承过程中,形成一个继承金字塔,位于金字塔底部的类越来越具体(强大),位于塔顶的越来越抽象(简单). 例如:人 ...
- windows 环境下如何使用virtualenv python环境管理工具
1.安装工具 pip install virtualenv 2.新建项目文件夹并在文件夹内安装环境并命名为my_env,加入 virtualenv C:\Users\yxx\wp\my_env 3.激 ...
- leetcode650—2 Keys Keyboard
Initially on a notepad only one character 'A' is present. You can perform two operations on this not ...
- Python2.7-SciPy
SciPy函数库在NumPy库的基础上增加了众多的数学.科学以及工程计算中常用的库函数.例如线性代数.常微分方程数值求解.信号处理.图像处理.稀疏矩阵等等 1.最小二乘拟合 详细介绍:https:// ...
- 树莓派学习笔记(3):利用VNC远程控制树莓派
转载请注明:@小五义http://www.cnblogs.com/xiaowuyi 等了一个十一假期,新买的B+终于到了.按照前两节的方法,重新安装了操作系统. 一.添加国内软件源 Rasp ...
- poj 1364 King(线性差分约束+超级源点+spfa判负环)
King Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 14791 Accepted: 5226 Description ...
- python3 Beautifulsoup <class 'bs4.element.ResultSet'> <class 'bs4.element.Tag'> 取值
1.<class 'bs4.element.ResultSet'> 这里是字典外套了一个列表 textPid = pid[0] 2.<class 'bs4.element.Tag ...
- Python3入门(八)——面向对象OOP
一.概述 老生常谈了,万物皆对象.Python作为一门面向对象的语言,也不例外 直接看一个简单的类定义和实例化类的示例: class Student: pass stu = Student() // ...
- 20155302《网络对抗》Exp8 Web基础
20155302<网络对抗>Exp8 Web基础 实验内容 (1).Web前端HTML(0.5分) 能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个 ...