Centos 搭建Hadoop
Centos搭建Hadoop
- 一、搭建Hadoop需要JDK环境,首先配置JDK
- 二、下载haoop
- 三、在Centos服务器上解压下载好的安装包
- 四、修改配置文件
- 五、配置环节变量/etc/profile
- 六、格式化NameNode
- 七、启动hadoop进程
- 八、测试访问50070端口
- 九、启动yarn
- 踩坑填坑记录:
- 官网下载hadoop包,切记要下载好正确的tar.gz包,第一次因为下错包,导致各种各样的错误出现。
- 配置文件的修改,修改配置文件时,一定要细心细心再细心,常常因为输入一个字母或符号导致出错,之前配置时,因为多输入一个:,导致排查错误很多次。
- 配置文件(*-site.xml)中的主机名都可以换为ip。
- 如果使用主机名配置时,需要注意修改系统主机名和映射文件
- 启动yarn和dfs时,如果不想重复输入密码,则需要进行ssh免密码登录配置。
- WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER.
- hadoop 3.x 启动过程中 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
- hadoop 集群开启之后datanode没有启动
一、搭建Hadoop需要JDK环境,首先配置JDK
二、下载haoop
官网地址:hadoop官网下载地址
三、在Centos服务器上解压下载好的安装包
tar -zxvf hadoop-3.1.2.tar.gz
四、修改配置文件
进入到/hadoop/etc/hadoop目录,首先修改
4.1 hadoop-env.sh
添加export JAVA_HOME=/usr/java/jdk1.8.0.144;
添加:
# set hadoop environment virables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
4.2 core-site.xml
添加如下信息:
<configuration>
<property>
<name>fs.default.name</name>
# 此处可能会埋坑,也可直接根据Ip进行设置如:hdfs://192.168.x.xx:9000
<value>hdfs://alary001:9000</value>
</property>
</configuration>
4.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
# 需要在目录/usr/local/处新建一个名为data的文件夹
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/data/tmp</value>
</property>
<property>
# hadoop的备份系数
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
dfs.replication一般设置多大的值比较合适?
dfs.replication=3表示冗余份数,这是hdfs的容错机制,防止有磁盘受损后数据损害。
Hadoop的备份系数是指每个block在hadoop集群中有几份,系数越高,冗余性越好,占用存储也越多。备份系数在hdfs-site.xml中定义,默认值为3.
4.4 mapred-site.xml
首先,需要查看是否有该配置文件,若无该文件,可以通过重命名mv mapred-site.xml.template mapred-site.xml改成此文件名。
修改内容如下:
<configuration>
<property>
# 指的是使用yarn运行mapreduce程序
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
启动了HDFS之后,就可以启动yarn了。执行命令start-yarn.sh即可启动MapReduce集群。
4.5 yarn-site.xml
修改内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>alary001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
YARN中的资源管理器(Resource Manager)负责整个系统的资源管理和调度,并内部维护了各个应用程序的ApplictionMaster信息,NodeManager信息,资源使用信息等。在2.4版本之后,Hadoop Common同样提供了HA的功能,解决了这样一个基础服务的可靠性和容错性问题。
ResourceManager (RM)负责跟踪集群中的资源,以及调度应用程序(例如,MapReduce作业)。在Hadoop 2.4之前,集群中只有一个ResourceManager,当其中一个宕机时,将影响整个集群。高可用性特性增加了冗余的形式,即一个主动/备用的ResourceManager对,以便可以进行故障转移。
YARN HA的架构如下图所示: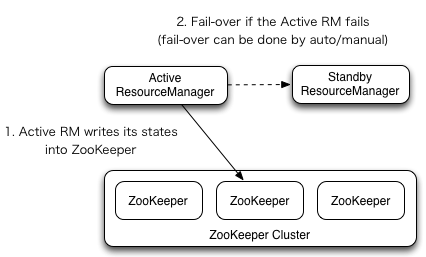
五、配置环节变量/etc/profile
需要配置JAVA_HOME以及HADOOP的相关配置,配置内容如下:
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# set hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
然后执行source /etc/profile,让配置文件生效
六、格式化NameNode
在任意目录下(配置Hadoop环境变量的情况下)执行命令:
hdfs namenode -format或者hadoop namenode -format
实现格式化。
七、启动hadoop进程
执行start-dfs.sh(注意中间没有空格);没有配置ssh免密登录之前,会不停的需要输入yes和密码,最后界面如图:

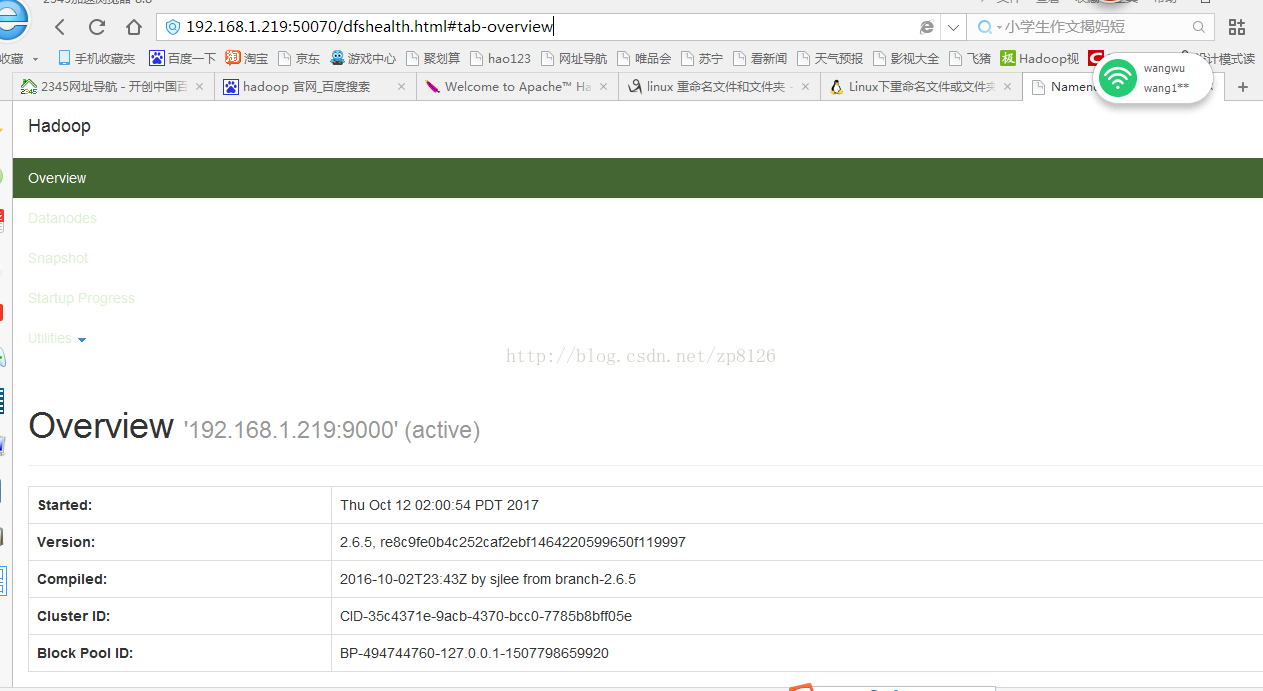
八、测试访问50070端口
关闭防火墙后,
service iptables stop
打开浏览器输入:http://192.168.x.xxx:50070/
九、启动yarn
执行start-yarn.sh启动yarn计算进程。
在浏览器中:http://192.168.x.xxx:8088/打开主页面:

踩坑填坑记录:
官网下载hadoop包,切记要下载好正确的tar.gz包,第一次因为下错包,导致各种各样的错误出现。
配置文件的修改,修改配置文件时,一定要细心细心再细心,常常因为输入一个字母或符号导致出错,之前配置时,因为多输入一个:,导致排查错误很多次。
配置文件(*-site.xml)中的主机名都可以换为ip。
如果使用主机名配置时,需要注意修改系统主机名和映射文件
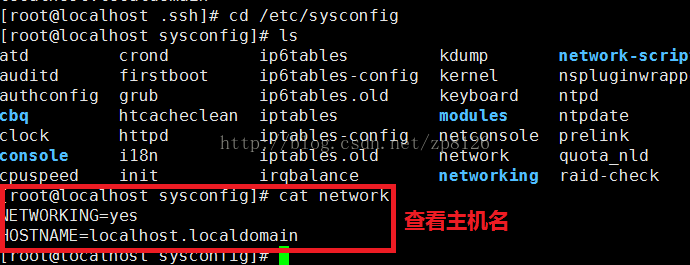
修改主机名称:
vi /etc/sysconfig/network
HOSTNAME=xxxx
配置映射信息:

启reboot,之后就可以使用主机名访问了 ,但是使用主机名访问只能虚拟机内。若需要在外部也使用主机名访问,在windows中配置hosts即可。
启动yarn和dfs时,如果不想重复输入密码,则需要进行ssh免密码登录配置。
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER.
adoop启动时WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.错误。
解决方案,在$ vim sbin/start-dfs.sh $ vim sbin/stop-dfs.sh 将
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
改为:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
hadoop 3.x 启动过程中 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
出现这种状况是因为当前账号没有配置ssh免密登录;
hadoop 3.x 启动过程中 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
hadoop 集群开启之后datanode没有启动
这个问题困扰了我很久,Master机器的各项都成功没有问题,slave机器的datanode各种启动不出来,尝试了网上的各种说法,最后还是有问题,但怀疑还是有部分配置没设置对,待查看。
hadoop 集群开启之后datanode没有启动
Centos 搭建Hadoop的更多相关文章
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- Centos搭建spark
Centos搭建spark 一.spark介绍 二.spark安装前提 三.集群规划 四.spark安装 五.修改spark环境变量 六.修改spark-env.sh 七.修改slaves 八.将安装 ...
- hadoop集群搭建--CentOS部署Hadoop服务
在了解了Hadoop的相关知识后,接下来就是Hadoop环境的搭建,搭建Hadoop环境是正式学习大数据的开始,接下来就开始搭建环境!我们用到环境为:VMware 12+CentOS6.4 hadoo ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- Hadoop 3.0完全分布式集群搭建方法(CentOS 7+Hadoop 3.2.0)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是3.2.0,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
随机推荐
- Linux操作系统的文件目录结构
一 --- 导读 首先记住一句经典的话:"linux世界中,万事万物皆为文件" 二---linux的目录结构示意图和windows下的目录结构示意图(本图需要背诵) 三---各目录 ...
- .net通过iTextSharp.pdf操作pdf文件实现查找关键字签字盖章
之前这个事情都CA公司去做的,现在给客户做demo,要模拟一下签字盖章了,我们的业务PDF文件是动态生成的所以没法通过坐标定位,只能通过关键字查找定位了. 之前在网上看了许多通多通过查询关键字,然后图 ...
- 软件工程与UML代码互改
这个作业属于哪个课程https://edu.cnblogs.com/campus/fzzcxy/2018SE1/ 这个作业的要求在哪里https://edu.cnblogs.com/campus/fz ...
- DHCP.md
DHCP 主配置文件 从 /usr/share/doc/dhcp 复制 dhcpd.conf.sample 到/etc/dhcp下 ...
- flask为多个接口添加同一个拦截器的方法
前言 最近又抽掉出来写一个 Python 项目, 框架使用 Flask , 又有些新心得, 比如本篇所说, 想要将某个蓝图加上统一的权限控制, 比如 admin 蓝图全部有一个统一的拦截器判断是否有权 ...
- Flutter 应用入门:路由管理
路由(Route)在移动开发中通常指页面(Page),这跟web开发中单页应用的Route概念意义是相同的,Route在Android中通常指一个Activity,在iOS中指一个ViewContro ...
- Vim 自动添加脚本头部信息
每次写脚本还在为忘记添加头部信息啥的烦恼? 按照下面这么做,帮你减轻点烦恼. # 打开配置文件: vim /root/.vimrc # 添加如下信息: autocmd BufNewFile *.sh ...
- ctfshow—web—web7
打开靶机 发现是SQL注入,盲注 过滤了空格符,可以用/**/绕过,抓包 直接上脚本 import requestss=requests.session()url='https://46a0f98e- ...
- SAP RFC的相关的术语说明
工作比较忙,很少有时间写点文章,抽空写点吧,给需要的人看看,虽然徒弟很多了,不过还是不要固步自封,在这里也指导更多的人进步吧. RFC(Remote Function Call)是SAP系统和其他(S ...
- USB限流IC,输入5V,输出5V,最大3A限流
USB限流芯片,5V输入,输出5V电压,限流值可以通过外围电阻进行调节,PWCHIP产品中可在限流范围0.4A-4.8A,并具有过压关闭保护功能. 过压关闭保护: 如芯片:PW1555,USB我们一半 ...