python实现文件查找功能,excel写入功能
因为要丛UE文档中过滤关键字来统计解码时间,第一次自己完成了一个自动化统计的小工具,用起来颇有成就感。
UE文件的内如如下:
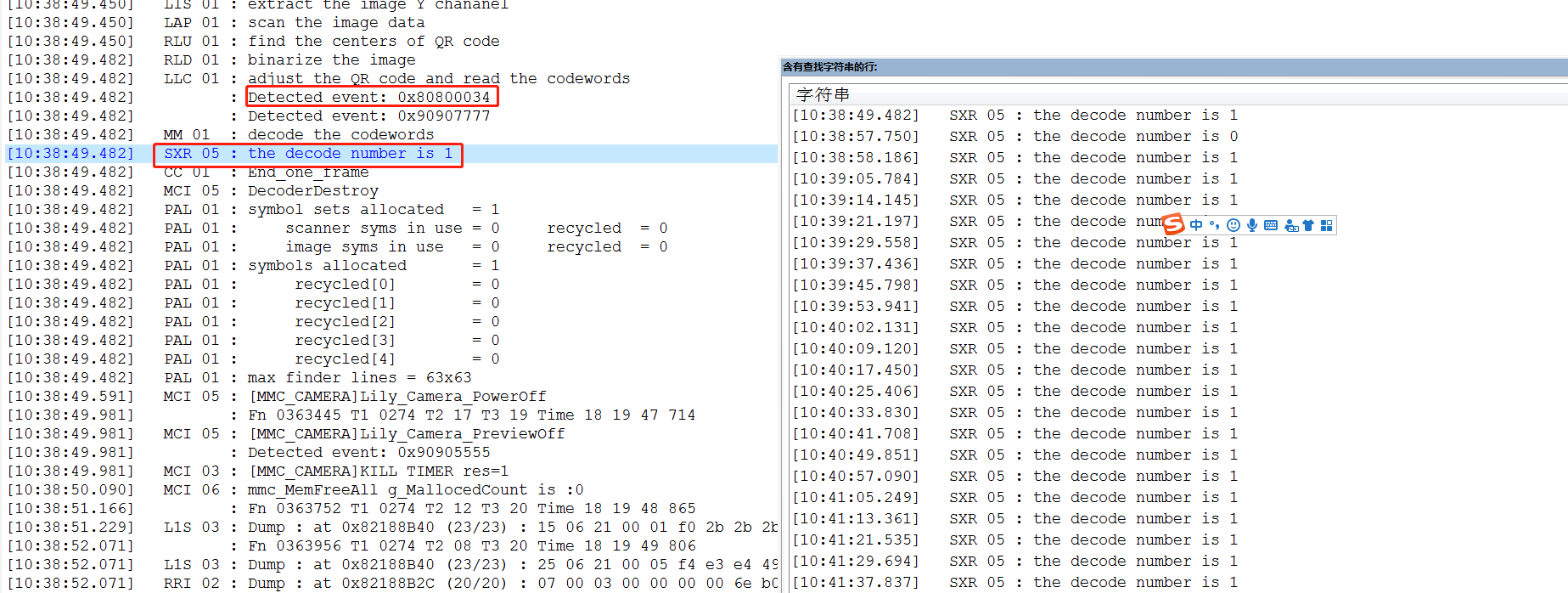
需要丛这份关键字中过滤红色标记的两个关键字,取 一个关键字的最后一位,和取一个关键字的最后3位,然后在excel表格中记录,并将值转为十进制
代码实现如下,虽然代码没那么简洁,但是功能是实现了
#coding :utf-8
#_author_=del
import os,sys
import re
import csv
import random
#import xlsxwriter
import xlwt
fdir = "E:/内部项目文档/2G扫码/多轴联动/亮度100%vivo/s002 29cm.trc" #文件路径
f1 = open(fdir,'r',errors='ignore')
keywordA ="number"
keywordB ="80800"
decoderesult = []
decodetime = []
data1=f1.readlines() #一次读取所有内容并按行返回列表
f1.close()
f2 = open('decode.txt', 'w')
f2s = open('result.txt','w')
f3 = open('time.txt','w')
f3s = open('decodetiem.txt','w')
# workbook = xlsxwriter.Workbook('解码时间.xls')
# worksheet = workbook.add_chartsheet('sheet1')
writebook = xlwt.Workbook()
sheet = writebook.add_sheet('sheet1')
headings = ['第N帧识别到','识读时间','识读时间(ms)'] #设置表头
for line in data1:
if keywordA in line:
# numlist = line.split('\t')
print(line)
f2.write(line+'\n')
f2s.write(line[-2:-1]+'\n')
decoderesult.append(int(line[-2:-1]))
f2.close()
f2s.close()
# print(decoderesult)
# for x in range(len(decoderesult)):---#列出 decoderusult数据的内容
# print(decoderesult[x])
# x+1
for line in data1:
if keywordB in line:
print(line)
if line[-4:-1] !='000'and line[-4:-1] !='001':
f3.write(line+'\n')
f3s.write(line[-4:-1]+'\n')
decodetime.append((line[-4:-1]))
f3.close()
f3s.close()
# print(decodetime)
# for y in range(len(decodetime)):
# print(decodetime[y])
# y+1
print(decoderesult)
print(decodetime)
print(len(decodetime),len(decoderesult))
if len(decoderesult)==len(decodetime):
i = 0 # 行
j = 0 #列
count = 0 #计数
for value in range(len(headings)):
sheet.write(i, j + value, headings[value]) # 写入excel,i行j+value列
i = 1
j = 0
skip = 0 #跳过的行
for v in range(len(decoderesult)): #遍历decoderesult数组
if decoderesult[v] == 1:
if count ==0:
sheet.write(i+v-skip,j+0,1)
else:
sheet.write(i+v-skip,j+0,count+1)
print(decodetime[v])
sheet.write(i+v-skip,j+1,decodetime[v])
sheet.write(i+v-skip,j+2,int(decodetime[v], 16))
count = 0
else:
count += 1
skip +=1
else:
print("解码次数和时间次数不匹配")
writebook.save('解码时间.xls')
python实现文件查找功能,excel写入功能的更多相关文章
- 用 Python 实现文件查找
用 Python 实现文件查找(BIF实现及队列实现) (1)利用内置函数实现文件查找 1.功能:返回用户输入的文件的绝对路径 2.设计思路: (1)用户输入在哪个盘进行查找 (2)遍历此盘文件,若为 ...
- python修改文件中字符串并写入
python实际工作中,做一些小工具,很方便.最近在做一个格式转换工具时候,用到了替换文件中特定字符串的 功能.当初没直接想出来,就在网上查了一下,做个记录,方便后续使用. # -*- coding: ...
- Python学习笔记_Python向Excel写入数据
实验环境 1.OS:Win 10 64位 2.Python 3.7 3.如果没有安装xlwt库,则安装:pip install xlwt 下面是从网上找到的一段代码,网上这段代码,看首行注释行,是在L ...
- python txt文件数据转excel
txt content: perf.txt 2018-11-12 16:48:58 time: 16:48:58 load average: 0.62, 0.54, 0.56 mosquitto CP ...
- 个人永久性免费-Excel催化剂功能第38波-比Vlookup更好用的查找引用函数
谈起Excel的函数,有一个函数生来自带明星光环,在表哥表姐群体中无人不知,介绍它的教程更是铺天盖地,此乃VLOOKUP函数也.今天Excel催化剂在这里冒着被火喷的风险,大胆地宣布一个比VLOOKU ...
- 个人永久性免费-Excel催化剂功能第103波-批量打开多文件或多链接
有时简单的东西,却带来许多的便利,为了让大家可以记住并容易找寻到此功能,也将这么简单的功能归为一波,反正已经100+波了,也无需为了凑功能文章而故意罗列一些小功能带忽悠性地让人觉得很强大. 使用场景 ...
- 个人永久性免费-Excel催化剂功能第88波-批量提取pdf文件信息(图片、表格、文本等)
日常办公场合中,除了常规的Excel.Word.PPT等文档外,还有一个不可忽略的文件格式是pdf格式,而对于想从pdf文件中获取信息时,常规方法将变得非常痛苦和麻烦.此篇给大家送一pdf文件提取信息 ...
- 个人永久性免费-Excel催化剂功能第80波-按条件查找数字,扩展原生查找功能
Excel的查找替换功能,只能对文本类数据查找较为得力,若需查找数字类型的数据,如查找大于100的数字,就无能为力,此篇Excel催化剂补足其短板. Excel数据类型知识背景介绍 用好Excel,必 ...
- 有关文件夹与文件的查找,删除等功能 在 os 模块中实现
最近在写的程序频繁地与文件操作打交道,这块比较弱,还好在百度上找到一篇不错的文章,这是原文传送门,我对原文稍做了些改动. 有关文件夹与文件的查找,删除等功能 在 os 模块中实现.使用时需先导入这个模 ...
随机推荐
- chrome实现网页高清截屏(F12、shift+ctrl+p、capture)
打开需要载屏的网页,在键盘上按下F12,出现以下界面 上图圈出的部分有可能会出现在浏览器下方,这并没有关系.此时按下 Ctrl + Shift + P(Mac 为 ⌘Command +⇧Shift + ...
- Redis原理知识点集锦
1.Redis有哪些数据结构? 字符串String.字典Hash.列表List.集合Set.有序集合SortedSet. 高级数据结构 HyperLogLog:基数统计 GEO:地理位置 PUB/SU ...
- 出现org.apache.ibatis.binding.BindingException异常
出现绑定式异常 查看target文件夹里面再mapper中,发现运行时缺少xml文件 解决办法 1.将xml文件复制到target中Mapper文件夹下面. 2.将xml放到resource目录下 3 ...
- pydub "Couldn't find ffmpeg or avconv - defaulting to ffmpeg" 问题解决
我通过 命令行安装了pydub库,运行报了如下错误 RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but ...
- 如何利用Typora编写博客,快速发布到多平台?
在不同的平台发布同样的文章,最让人头疼的就是图片问题,如果要手动一个个去重新上传,耗时耗力,还容易搞错.下面分享的方法,可以将Typora编写的文章快速发布到CSDN.微信公众号.博客园.简书等平台. ...
- API接口的安全设计验证—ticket,签名,时间戳
概述 与前端对接的API接口,如果被第三方抓包并进行恶意篡改参数,可能会导致数据泄露,甚至会被篡改数据,我主要围绕时间戳,token,签名三个部分来保证API接口的安全性 1.用户成功登陆站点后,服务 ...
- i5 11300h和R5 5600H 的区别 哪个好
酷睿i5-11300H配置为4个内核及8个线程,具备8MB的L3缓存和5MB的L2缓存,基础频率3.10GHz最高睿频4.40GHz.Intel的显卡将集成Xe GPU内核.至于TDP,i5-1130 ...
- Web Service 服务无法连接Oracle数据库
这个问题之前部署就遇到过,但是后来忘了,所以记录一下吧. 我部署Web Service服务的时候,服务没法正常运行,与Oracle数据库无法正常通信. 检查了数据库连接字没有任何问题,写了个测试接口, ...
- #2020征文-开发板# 用鸿蒙开发AI应用(二)系统篇
目录: 前言 安装虚拟机 安装 Ubuntu 设置共享文件夹 前言上回说到,我们在一块 HarmonyOS HiSpark AI Camera 开发板,并将其硬件做了一下解读和组装.要在其上编译鸿蒙系 ...
- 记一次flask上传文件返回200前端却504的问题
前言 好久没写了, 主要是太忙了, 本篇记一下今天解决的一个问题吧, 耗了我大半天的时间才解决 问题 今天在调试代码时, 发现了一个诡异的问题, 我之前写了一个接口, 作用是接收上传的文件, 因为这个 ...