PageObject课程培训记录
前言
昨晚的培训课程讲了PO设计模式,对于PO模式我们需要去了解关于为什么要使用PO,而不使用PO是什么情况?什么是PO模式?PO怎么去使用?
第一,为什么要使用PO,而不使用PO是什么情况?
我们先来看看在使用PO之前,我们的自动化是怎么做的:
# -*- coding:utf-8 -*-
__author__ = "清风" from selenium import webdriver driver = webdriver.Firefox()
# 打开浏览器
driver.get("http://www.baidu.com")
# 百度搜索 输入selenium
driver.find_element("id","kw").send_keys("selenium")
# 点击搜索按钮
driver.find_element("id","su").click() driver.quit()
从上述代码中,我们能看出我们做UI自动化主要就是定位元素,然后进行输入或鼠标点击操作。可能大家感觉我们写的很简单,但是呢?如果再添加其他操作呢?而且这只是一个页面的操作,那再加上其他的页面呢?随着我们业务越来越多,脚本也就越来越庞大,如果我们要修改页面的元素定位,我们需要去庞大的脚本中寻找到元素,也可能这个元素在多个业务逻辑中都存在,那我们要找到所有存在这个元素的业务逻辑,然后修改这个元素,这就是一个很头疼的事了。一个元素的变动,都需要我们花费大量的代价去维护我们的代码,所以说这时候我们就要引入PO模式来解决这个问题。
第二,什么是PO模式?
PO模式:Page Object Model(也称POM),页面对象模型(POM)是一种设计模式,实现了对页面元素及方法的分离。
通过类来管理页面:程序的每一个页面都有一个对应的page class
通过属性来管理操作对象:每一个页面需要操作的元素都是一个页面类的属性
通过方法来管理业务:每一个业务逻辑都使用类方法去进行管理,方法名最好根据对应的业务场景进行命名。
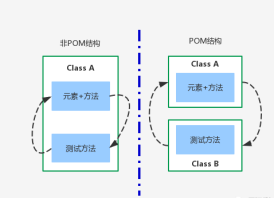
PO模式的好处:
POM提供了一种在将页面及元素对象、业务流程操作与验证分离的模式,这样会使得测试代码变得更加清晰和高可读性
对象库与用例分离,使得我们更好的重用对象,方便修改变化。
页面元素操作方法会使用例变得更加简洁。
简单明了的命名方式使得我们更方便的知道方法所操作的对象
第三,怎么去使用PO?
先来看下代码的目录结构:
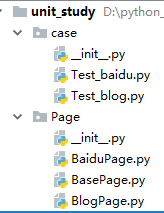
Page目录下存放的是页面对象,BasePage是基类,我们页面对象需要继承基类。
先看基类的代码:
# -*- coding:utf-8 -*-
__author__ = "清风" from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from TestTools.log import log class Base_page():
"""
Page基类,所有page类都需要继承该类
"""
def __init__(self,driver,base_url):
self.driver = driver
self.base_url = base_url
self.log = log() def find_element(self,*loc,timeout=20):
try:
WebDriverWait(self.driver,timeout).until(EC.presence_of_element_located(loc))
return self.driver.find_element(*loc) except:
self.log.error("对象没有找到!") def send_value(self,loc,text):
self.find_element(*loc).send_keys(text) def click(self,loc):
self.find_element(*loc).click()
基类主要是将selenium的元素操作进行了再次封装,方便我们的调用。
再看我们的Page页面类:
# -*- coding:utf-8 -*-
__author__ = "清风" from Page.BasePage import Base_page class BaiduSerch(Base_page):
search_input_loc = ("id","kw")
search_button_loc = ("id","su") def __init__(self,driver,base_url="http://www.baidu.com"):
Base_page.__init__(self,driver,base_url) def gotoBaidu(self,title):
self.driver.get(self.base_url)
self.is_title(title) def is_title(self,title):
assert title in self.driver.title def input_search(self,text="selenium"):
self.send_value(self.search_input_loc,text) def click_button(self):
self.click(self.search_button_loc) def search_baidu(self,title,text):
self.gotoBaidu(title)
self.input_search(text)
self.click_button()
Page类主要是将页面元素变为了类属性,将元素操作变为可调用方法,并且也将业务逻辑变为了方法。
再看测试类:
# -*- coding:utf-8 -*-
__author__ = "清风" import unittest
from selenium import webdriver
from TestTools.getCase import getCase
import ddt
from Page.BaiduPage import BaiduSerch test1 = [['1','test1','selenium','百度一下,你就知道']] @ddt.ddt
class testBaidu(unittest.TestCase):
excel = getCase()
cls = excel.excel_read() def setUp(self):
self.driver = webdriver.Firefox() @ddt.data(*test1)
def testBaidu(self,cls):
print("用例id=%s, 用例名称=%s" % (cls[0],cls[1]))
bsp = BaiduSerch(self.driver)
bsp.search_baidu(cls[3], cls[2]) def tearDown(self): self.driver.quit() if __name__ == '__main__':
unittest.main()
测试类只需要将driver初始化,然后去调用我们的页面类,直接调用我们封装的页面业务逻辑,就可以开始测试了。
最后,只需要运行我们的unittest测试集即可。
最后,关于重点需要指出内容:
我们在使用PO时,使用的selenium查找对象元素的方法是find_element,这时候我们去建立页面属性时使用的是变量存放,如:
search_input_loc = ("id","kw")
则我们需要这样使用driver.find_element(*search_input_loc),为什么加*呢?
在python中,如果是在函数调用中,* args表示将可迭代对象扩展为方法的参数列表;如果是函数定义中参数前的*表示的是将调用时的多个参数放入元组中;
这里是重点,因为如果这里没写好,就会报错。
PageObject课程培训记录的更多相关文章
- 76.培训记录信息 Extjs 页面
1.培训记录信息页面jsp <%@ page language="java" import="java.util.*" pageEncoding=&quo ...
- .NET 提升教育 第一期:VIP 付费课程培训通知!
为响应 @当年在远方 同学的建议,在年前尝试进行一次付费的VIP培训. 培训的课件:点击下载培训周期:10个课程左右,每晚1个半小时培训价格:1000元/人.报名方式:有意向的请加QQ群:路过秋天.N ...
- .NET在线培训 | C#在线培训 | .NET培训 | 最课程培训
最课程(www.zuikc.com) 软件开发培训,在线软件培训的创新者!我们的创新在于: 1:一次购买,终身服务.每个最课程学员都会分配一位专职教师及一位监管教师,点对点跟进课程进度,直到您学会课程 ...
- 【MOOC课程学习记录】数据结构
看了中国大学MOOC zju的<数据结构>2019夏的第九次开课.做了一些PTA上的习题,没有全做,因为做得慢,老是不会,加上并不能做到一有空就学习,所以做不完了,给跪了Orz. 以后有时 ...
- 【MOOC课程学习记录】程序设计与算法(一)C语言程序设计
课程结课了,把做的习题都记录一下,告诉自己多少学了点东西,也能给自己一点鼓励. ps:题目都在cxsjsxmooc.openjudge.cn上能看到,参考答案在差不多结课的时候也会在mooc上放出来. ...
- 组内Linq培训记录
注: 由于该培训是在组内分享,先写成了Word,而word中的代码都以截图方式呈现了,而在博客园不能很方便的粘贴截图进来,所以我用插入代码的方式加进来,如果文中说“如下图”或“如下图代码”,那么就直接 ...
- YC(Y Combinator)斯坦福大学《如何创业》课程要点记录(粗糙)
20节课程,每节都是干货满满,时常听说理论无用,但是好的理论,绝对能帮助你少走一些弯路. YC简介: Y Combinator成立于2005年,是美国著名创业孵化器,Y Combinator扶持初创企 ...
- vue培训记录
在公司做了一次vue相关的培训,自己整理了一些大纲.供大家参考学习! ### 1. 项目构成及原理 [Vue](https://cn.vuejs.org/)###* 主流框架见解及差别 * react ...
- IP,路由,交换基础培训记录
IP 掩码 子网划分 vlan划分(有助于减少广播压力) vlan之间互通通过交换机打通. 路由,静态路由,动态路由(学习到的),路由表,下一跳,网络位长的优先级高. 交换机,hub集线器. hub ...
随机推荐
- Mysql探索之索引详解,又能和面试官互扯了~
前言 索引是什么?有什么利弊?一旦在面试中被问道,对于新入门的小白可能是个棘手的问题. 本篇文章将会详细讲述什么是索引.索引的优缺点.数据结构等等常见的知识. 什么是索引 索引就是一种的数据结构,存储 ...
- go语言之抛出异常
一: panic和recover 作用:panic 用来主动抛出错误: recover 用来捕获 panic 抛出的错误. 概述: ,引发panic有两种情况 )程序主动调用panic函数 )程序产生 ...
- 2020.08.31 Unit 10(暂未完成)
[重点短语] 01.at night 在晚上 02.in a more natural environment 在一个更加自然的环境中 03.all year round 一年到头,终年 04.be ...
- 前端模块化IIFE,commonjs,AMD,UMD,ES6 Module规范超详细讲解
目录 为什么前端需要模块化 什么是模块 是什么IIFE 举个栗子 模块化标准 Commonjs 特征 IIFE中的例子用commonjs实现 AMD和RequireJS 如何定义一个模块 如何在入口文 ...
- JAVA集合类简要笔记 - 内部类 包装类 Object类 String类 BigDecimal类 system类
常用类 内部类 成员内部类.静态内部类.局部内部类.匿名内部类 概念:在一个类的内部再定义一个完整的类 特点: 编译之后可生成独立的字节码文件 内部类可直接访问外部类私有成员,而不破坏封装 可为外部类 ...
- 轻轻松松学CSS:媒体查询
轻轻松松学CSS:利用媒体查询创建响应式布局 媒体查询,针对不同的媒体类型定制不同的样式规则.在网站开发中,可以创建响应式布局. 一.初步认识媒体查询在响应式布局中的应用 下面实例在屏幕可视窗口尺寸大 ...
- SQL Node 1.05版
输出: select a.f1, b.f2 from table01 a, ( select a from tb ) b where a.f1=1 and b.f2=2 or b.f3=3 order ...
- MyBatis源码骨架分析
源码包分析 MyBatis 源码下载地址:https://github.com/MyBatis/MyBatis-3 MyBatis源码导入过程: 下载MyBatis的源码 检查maven的版本,必须是 ...
- JavaScript浮点数及其运算
.普及两个函数Math.pow(底数,几次方)Number.toFixed(小数位数)2.浮点数相加function accAdd(arg1,arg2){ var r1,r2,m; try{r ...
- Android 4.X 系统加载 so 失败的原因分析
1 so 加载过程 so 加载的过程可以参考小米的系统工程师的文章loadLibrary动态库加载过程分析 2 问题分析 2.1 问题 年前项目里新加了一个 so库,但发现native 方法的找不到的 ...