目标检测入门论文YOLOV1精读以及pytorch源码复现(yolov1)
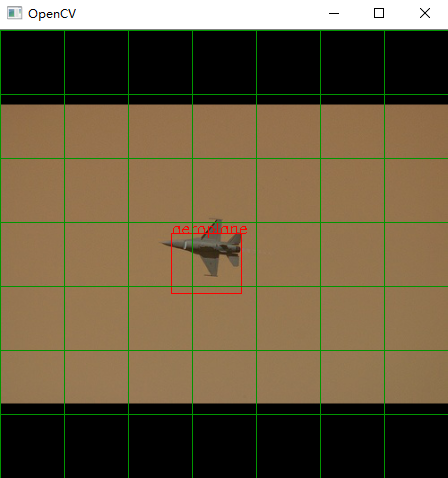
结果展示
其中绿线是我绘制的图像划分网格。
这里的loss是我训练的 0.77 ,由于损失函数是我自己写的,所以可能跟大家的不太一样,这个不重要,重要的是学习思路。

重点提示
yolov1是一个目标检测的算法,他是一阶段的检测算法。
一阶段(
one-stage):检测物体的同时进行分类。(代表论文:yolov1 - yolov5)二阶段(
two-stage):先检测出物体,再进行分类。(代表论文:rcnn,fast-rcnn)
重点要理解yolov1的数据特征标注方式。
只有理解了数据特征的标注方式才可以理解他为什么可以起作用。
论文剖析
1、理解
VOC数据集的数据形式。2、从
VOC数据集中提取出标注好的数据特征。3、
yolov1的数据组织。4、
yolov1的算法模型。5、
yolov1的准确率评估方式(IOU)。6、
yolov1的损失函数。
理解VOC数据集
首先需要知道我们使用的数据集的形式,因为每一个数据集的特征标注以及组织方式都不同。
我们可以去官网下载voc的数据集,这里使用的是voc2012数据集。
VOC数据集镜像网站. 下载voc2012的Train/Validation Data (1.9 GB)。
数据集下载之后解压出来是这样子:
每个文件夹存放的啥都标注好了,我们这里用不到那么多。
我们只用jpg原图,以及每个原图中目标的位置即可。(下边图片中画红框的两个文件夹)

但是我们发现,Annotations文件夹中的目标位置信息是存放在xml中,所以我们往下分析一个xml文件看看。
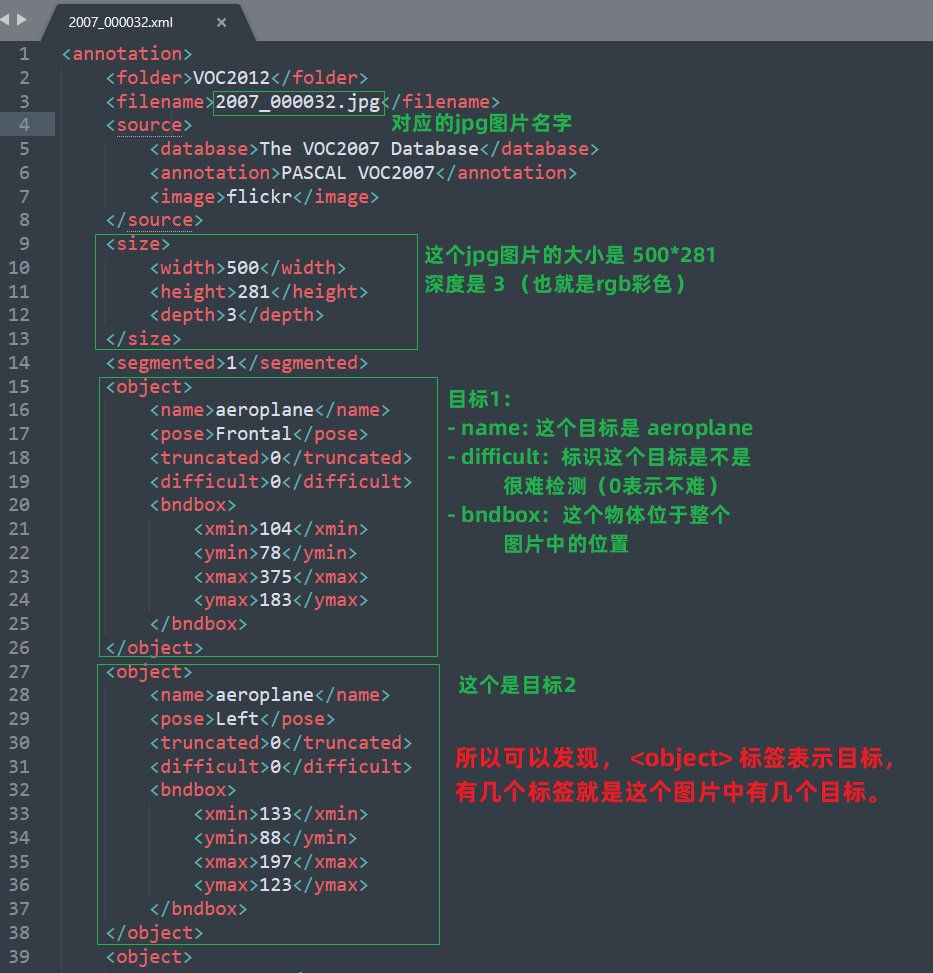
<filename>: 表示这个文件是对应于哪一个jpg图片的。
<size>:表示对应的jpg图片大小。
<object>:就是这个图片中的目标在图片中的信息。包括:目标名字,是否难识别,以及目标在整个图片中的坐标位置。(有几个 object 就是有几个目标)
提取目标初始数据
上边我们分析出每个图片中有什么目标都是存储在
xml文件中的,所以我们需要将xml文件的目标与类别数据提取出来,以便我们使用。
思路:
1、使用库
xml.etree.ElementTree读取xml格式的文件,从中提取出每一个xml文件中的所有<ojgect>标签数据(个数就是目标的数量)。2、将
<object>标签提取出类别、xmin、ymin、xmax、ymax,并且将其归一化为类别、x、y、w、h。
归一化就是根据从目标中提取出的
xmin、ymin、xmax、ymax得到目标的宽高,分别除以整个图片的宽高。
x:目标的中心位置x坐标。y:目标的中心位置y坐标。w:目标的宽度,h:目标的高度。
- 3、然后将归一化的数据按照上面的格式,整理为labels文件。
每一个
labels文件对应于一个图片,labels文件中的每一行就是这个图片中的一个目标的类别、x、y、w、h数据(一个图片有几个目标,对应的labels文件就有几行)。
例子:
针对如下xml文件,可以得知:
- 对应的
jpg图片是2007_000042.jpg,并且图片的大小是500*335的三色图(这里的图片大小就是用来归一化的)。- 含有两个
<object>标签,所以这个图片中有两个目标,并且目标的类别、位置坐标可以根据name、xmin、ymin、xmax、ymax得到。
<annotation>
<folder>VOC2012</folder>
<filename>2007_000042.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size>
<width>500</width>
<height>335</height>
<depth>3</depth>
</size>
<segmented>1</segmented>
<object>
<name>train</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>263</xmin>
<ymin>32</ymin>
<xmax>500</xmax>
<ymax>295</ymax>
</bndbox>
</object>
<object>
<name>train</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1</xmin>
<ymin>36</ymin>
<xmax>235</xmax>
<ymax>299</ymax>
</bndbox>
</object>
</annotation>
大致如下:绿色框 与 蓝色框 分别是两个目标。
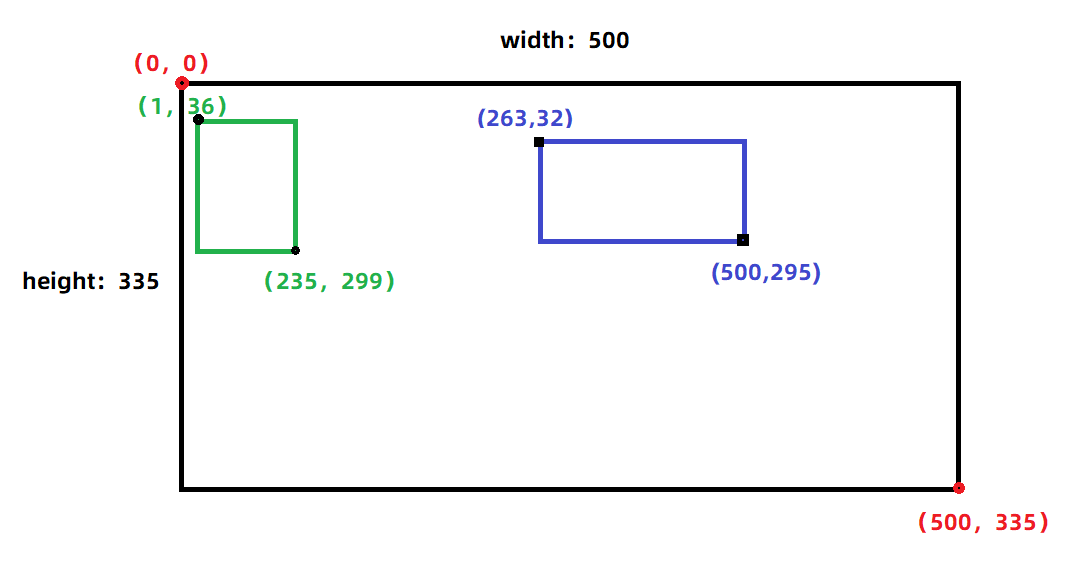
使用xml文件中已有数据,得到 labels文件如下:
其中每一行是一个物体,每行的数据表示的意义是:
类别,x,y,w,h. (数据都是归一化过了)

所以,这个就是最初的labels文件的形式。
下一步就是将这个初始labels文件数据形式,组织成可以 直接与对应图片运行 的数据形式。
YOLOV1的数据组织
其实yolo的思想可以用一句话来代替:将一个张图片划分网格(通常是
7*7),然后找目标的中心落在那个网格中(得到目标中心点坐标),并且以中心点坐标为参考找出目标边框的宽与高。
将图片进行网格划分
如图,针对图片进行
7*7的网格划分。

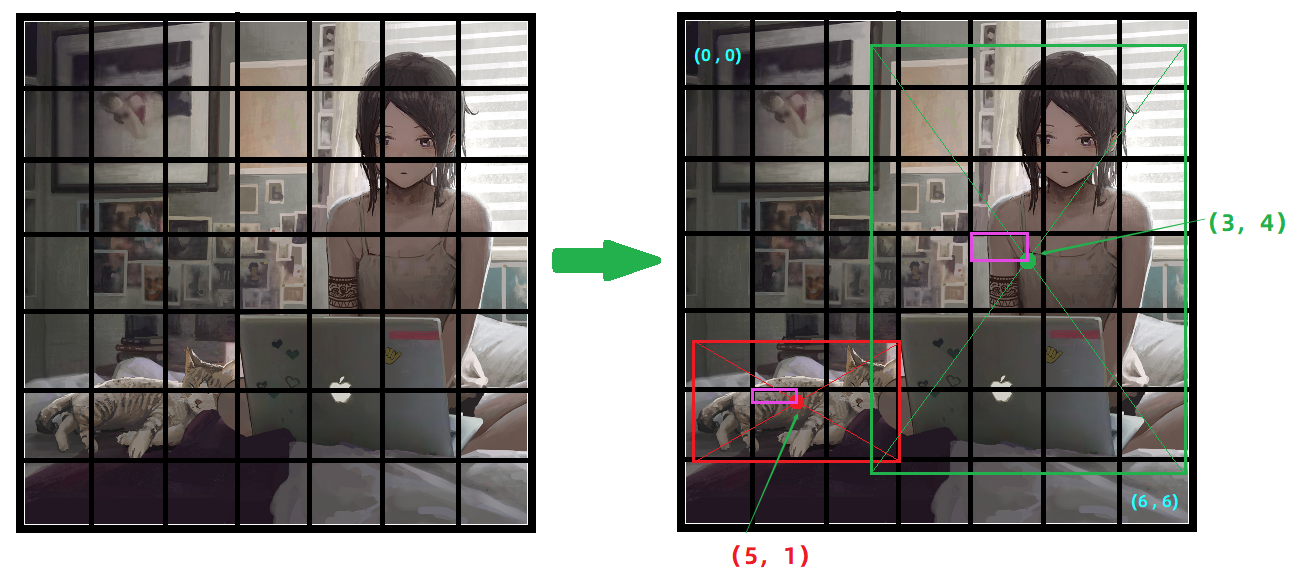
找目标物体中心落所在的网格
所以这个图片中的两个目标
cat与person的中心点分别落在网格中的(5,1)与(3,4)两个位置,并且可以知道这个中心点相对于当前网格的坐标(就是紫色框表示的内容)。
目标物体的宽高
在物体中心点找出之后,以中心点为坐标找出边框的宽与高即可。
经过上边的分析,我们可以发现:想要确定一个物体,只要知道它的中心点坐标,以及相对于中心点坐标的物体宽高即可。
所以:当我们的模型拿到一张图片之后
- 首先,将图片进行网格划分。
- 然后,判断每一个小网格中是否有物体。
- 如果预测有物体就预测出物体相对于本网格的坐标,以及相对于本坐标的物体宽高。
labels的组织方式
labels的数据都是来自上边xml中提取的数据。
经过上边yolo运作流程的讲解,可以得知labels数据需要 针对每一个小网格 组织出:相对于当前网格中心点的坐标,宽高,预测概率,目标类别。
其中:
- 预测概率的值是 1或0,有目标的时候预测值是1,没目标的时候预测值是0。
- 这里用20个类别,每一个网格预测的目标是什么类别,则对应的类别数字为1,否则为0 (细节见下图)。
注意:由于每一个网格中可能会有多个目标的中心点,所以这里的labels组织的时候,将每个格子预测两个中心点。(细节见下图)
这个图是所有网格的数据形式。数据长度为30.
**这个图中的所有数据都可以根据 上文从xml中提取的数据得到。 **
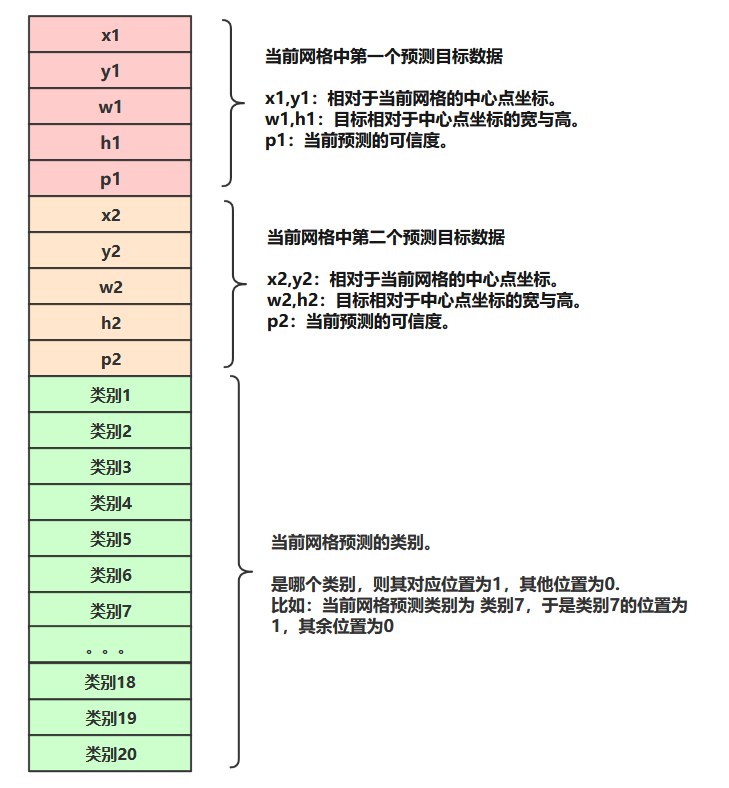
由此可知,每个网格的labels是由长度为30的上述数据组成的;因为我们的图片划分为7*7个网格,所以就是有7*7个长度为30的数据组成整个图片的lables。即整张图片的labels数据形式为:7*7*30。labels数据矩阵如下图所示。
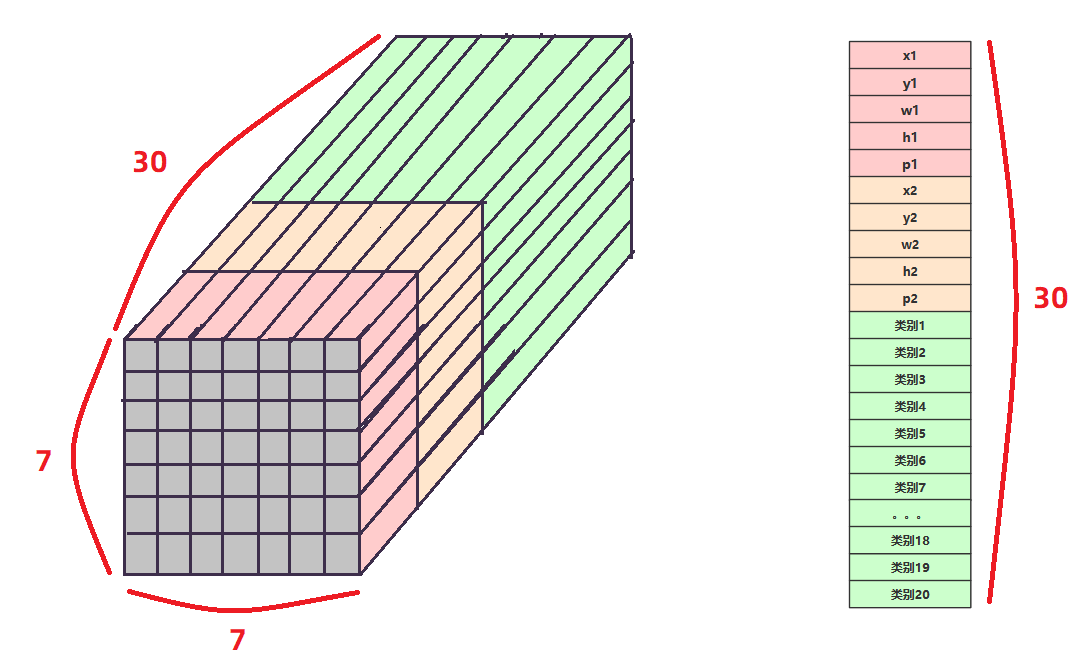
所以,我们输入网络的数据就是图片转为tensor的数据,inputs维度为:[batchsize,3,448,448].
网络的输入labels维度为:[batchsize,30,7,7]. 就是上边的数据矩阵。
网络的输出:[batchsize,30,7,7].
ok,上边的数据组织完成,那么接下来就是将组织好的 inputs 与 labels 送入网络训练即可。
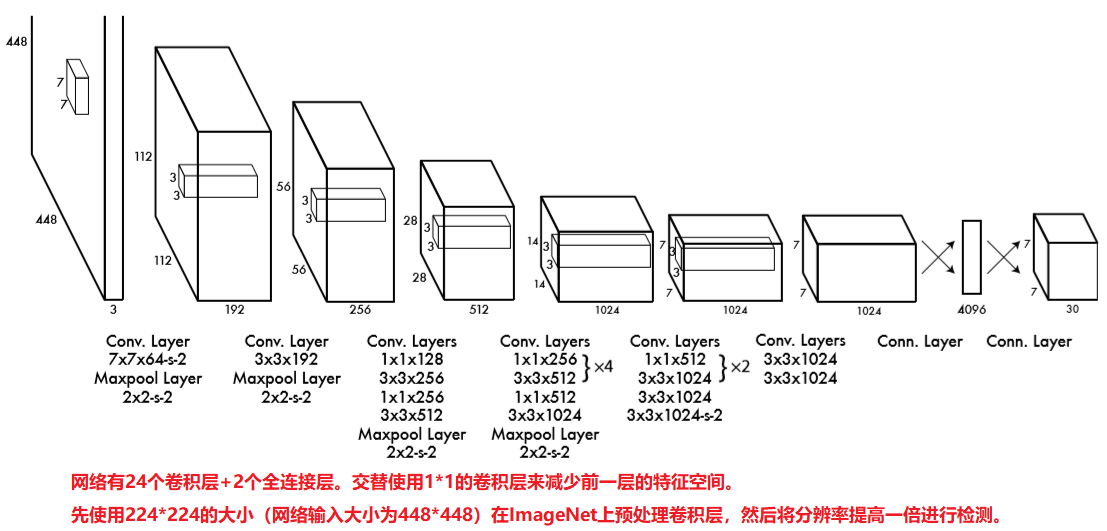
YOLOV1模型
- 网络有24个卷积层,然后是2个全连接层,简化了1×1还原层,由3×3个卷积层组成。
- (原文使用的是imageNet作为预处理模型,然后后边的输出重写成所需要的输出。)
- 我这里使用的是基于resnet的预处理模型。
评估标准IOU
IOU就是交并比,因为原来有一个正确的目标边框数据,此时我们预测一个边框数据之后,计算出两个边框相交的面积,在计算出相并的面积,然后求出比值,就是交并比。
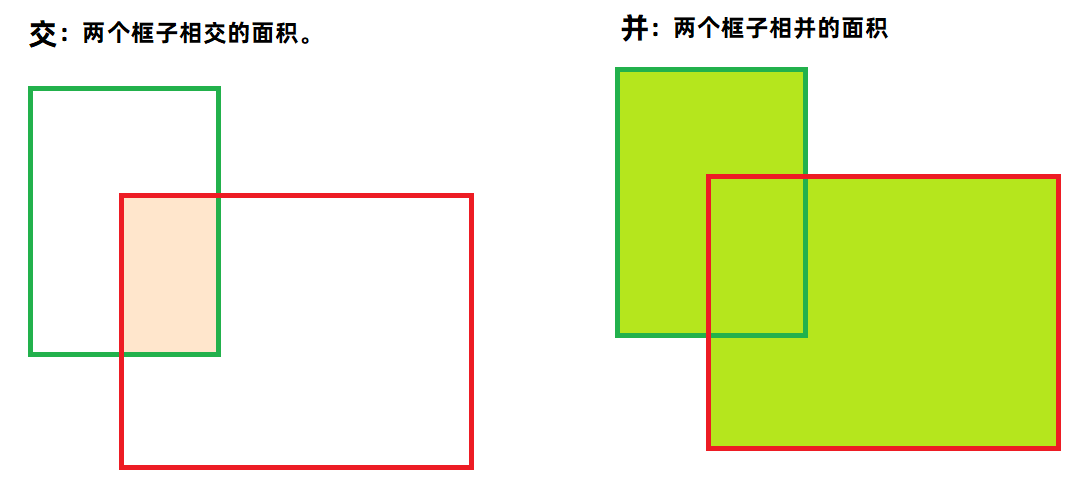
交并比越 大 ,说明两个框子越相似,说明预测结果越好。最大 IOU=1 ,就是预测框与真实框重合。
交并比越 小 ,说明两个框子越不相似,说明预测结果越差。最小 IOU=0 ,就是预测框与真实框没有一点相交的地方。
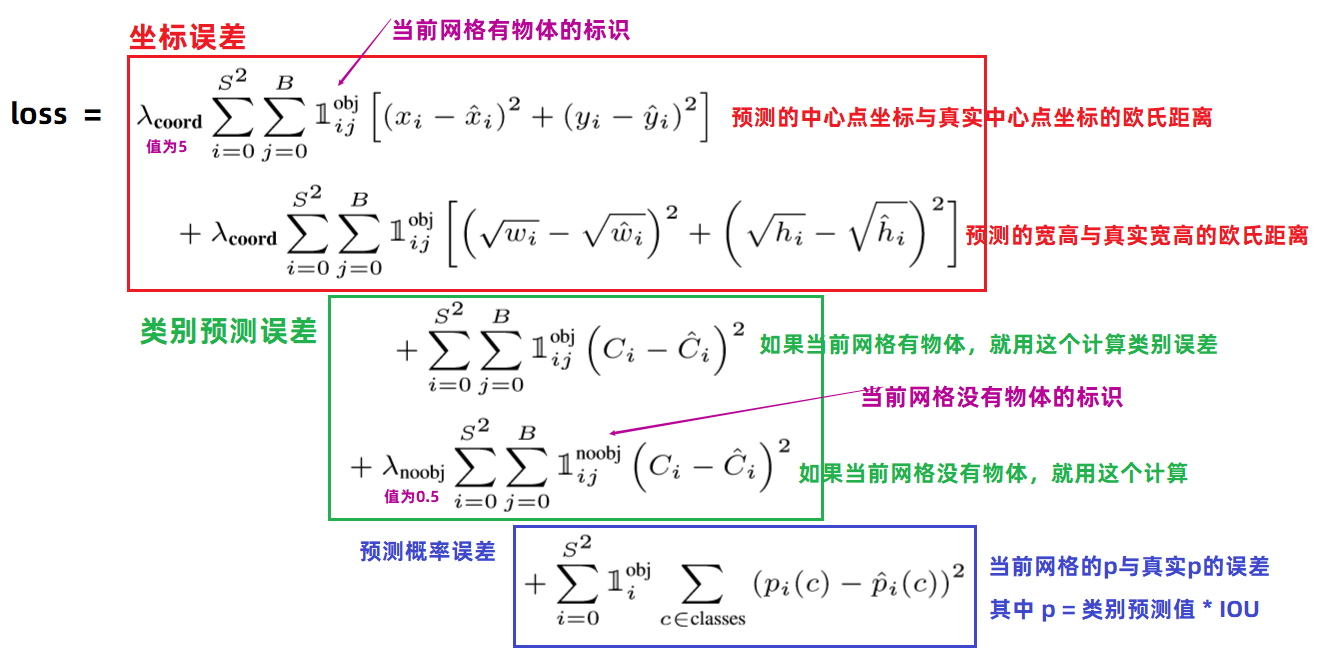
损失函数
三部分组成。
目标检测入门论文YOLOV1精读以及pytorch源码复现(yolov1)的更多相关文章
- ELMo解读(论文 + PyTorch源码)
ELMo的概念也是很早就出了,应该是18年初的事情了.但我仍然是后知后觉,居然还是等BERT出来很久之后,才知道有这么个东西.这两天才仔细看了下论文和源码,在这里做一些记录,如果有不详实的地方,欢迎指 ...
- EAST结构分析+pytorch源码实现
目录 EAST结构分析+pytorch源码实现 @ 一. U-Net的前车之鉴 1.1 FCN网络结构 1.2 U-NET网络 1.3 CTPN网络 二. EAST结构分析 2.1 结构简述 2.2 ...
- 精读《syntax-parser 源码》
1. 引言 syntax-parser 是一个 JS 版语法解析器生成器,具有分词.语法树解析的能力. 通过两个例子介绍它的功能. 第一个例子是创建一个词法解析器 myLexer: import { ...
- python编程从入门到实践 alien invasion 项目源码
现在上传一个 python编程从入门到实践 alien invasion 项目源码 以供大家学习参考 跟官方版本可能不太一样,因为是自己写的 也算是给新手一个参考 我用的环境是pycharm 可能需要 ...
- 精读《sqorn 源码》
1 引言 前端精读<手写 SQL 编译器系列> 介绍了如何利用 SQL 生成语法树,而还有一些库的作用是根据语法树生成 SQL 语句. 除此之外,还有一种库,是根据编程语言生成 SQL.s ...
- 皮卡丘检测器-CNN目标检测入门教程
目标检测通俗的来说是为了找到图像或者视频里的所有目标物体.在下面这张图中,两狗一猫的位置,包括它们所属的类(狗/猫),需要被正确的检测到. 所以和图像分类不同的地方在于,目标检测需要找到尽量多的目标物 ...
- ICCV2013、CVPR2013、ECCV2013目标检测相关论文
CVPapers 网址: http://www.cvpapers.com/ ICCV2013 Papers about Object Detection: 1. Regionlets for Ge ...
- 第三十七节、人脸检测MTCNN和人脸识别Facenet(附源码)
在说到人脸检测我们首先会想到利用Harr特征提取和Adaboost分类器进行人脸检测(有兴趣的可以去一看这篇博客第九节.人脸检测之Haar分类器),其检测效果也是不错的,但是目前人脸检测的应用场景逐渐 ...
- 分布式架构-Redis 从入门到精通 完整案例 附源码
导读 篇幅较长,干货十足,阅读需要花点时间,全部手打出来的字,难免出现错别字,敬请谅解.珍惜原创,转载请注明出处,谢谢~! NoSql介绍与Redis介绍 什么是Redis? Redis是用C语言开发 ...
随机推荐
- L3-015. 球队“食物链”【DFS + 剪枝】
L3-015. 球队"食物链" 时间限制 1000 ms 内存限制 262144 kB 代码长度限制 8000 B 判题程序 Standard 作者 李文新(北京大学) 某国的足球 ...
- CSS 解决Float后塌陷问题
当父级元素没有设定高度时候,而子集元素设定float类型时候,此时父级元素不能靠子集元素撑起来,所以就形成了塌陷: 示例分析 **1.Float之前的效果** <!DOCTYPE html> ...
- 计蒜客 2019南昌邀请网络赛J Distance on the tree(主席树)题解
题意:给出一棵树,给出每条边的权值,现在给出m个询问,要你每次输出u~v的最短路径中,边权 <= k 的边有几条 思路:当时网络赛的时候没学过主席树,现在补上.先树上建主席树,然后把边权交给子节 ...
- 015.NET5_MVC_Razor局部视图
局部视图 1. 可以增加代码的重用性 如何定义? 1.添加一cshtml文件 2. 在页面中调用局部视图:@html.Partial("局部视图的名称") 问题:局部视图中不能访问 ...
- Apple Screen Recorder All In One
Apple Screen Recorder All In One Apple macOS 自带录屏 QuickTime Player https://support.apple.com/zh-cn/g ...
- asm movbe 指令
movbe MOVBE 目标操作数,源操作数 复制源操作数的数据,交换字节后,移动数据 假如: movbe eax,(float)1000.0 eax == 0x00007A44 movbe eax, ...
- NGK团队是如何打造超高回报率的BGV项目的?
NGK旨在激励网络的供给端引导去中心化的节点集群,用于促进网络使用和增加带宽流动. 具体来讲,在未来的24个月内,NGK会将部分生态参与者纳入白名单系统有兴趣的参与者可关注官方信息. 对内,NGK采用 ...
- NGK Global伦敦路演:“区块链+能源”必将推动世界性能源革命
随着区块链技术的发展和应用的不断完善深入,市场的热情也开始活跃高涨,在万众期待下,NGK Global在英国伦敦的路演于7月25日圆满举办. 此次伦敦路演会议中众多行业精英,各社区代表.星盟投资公司资 ...
- Linux 内核和 Windows 内核有什么区别?
Windows 和 Linux 可以说是我们比较常见的两款操作系统的. Windows 基本占领了电脑时代的市场,商业上取得了很大成就,但是它并不开源,所以要想接触源码得加入 Windows 的开发团 ...
- 大数据开发-linux下常见问题详解
1.user ss is currently user by process 3234 问题原因:root --> ss --> root 栈递归一样 解决方式:exit 退出当前到ss再 ...