Boost.JSON Boost的JSON解析库(1.75首发)
目录
Boost的1.75版本新库
12月11日,Boost社区发布了1.75版本,相比较于原定的12月9日,推迟了两天。这次更新带来了三个新库:JSON,LEAF,PFR。
其中JSON自然是json格式的解析库,来自Vinnie Falco和Krystian Stasiowski。
LEAF是一个轻量的异常处理库,来自Emil Dotchevski。
PFR是一个基础的反射库,不需要用户使用宏和样版代码(由于还未仔细阅读此库,可能翻译有一些不准确),来自Antony Polukhin。
JSON库简介
其实在之前,Boost就已经有能够解析JSON的库了,名字叫做Boost.PropertyTree。Boost.PropertyTree不仅仅能够解析JSON,还能解析XML,INI和INFO格式的文件。但是由于成文较早及需要兼容其他的数据格式,相比较于其他的C++解析库,其显得比较笨重,使用的时候有很多的不方便。
Boost.JSON相对于Boost.PropertyTree来所,其只能支持JSON格式的解析,但是其使用方法更为简便,直接。华丽胡哨的东西也更多了。
JSON的简单使用
有两种方法使用Boost.JSON,一种是动态链接库,此时引入头文件boost/json.hpp,同时链接对应的动态库;第二种是使用header only模式,此时只需要引入头文件boost/json/src.hpp即可。两种方法各有优缺点,酌情使用。
编码
最通用的方法
我们要构造的json如下,包含了各种类型。
{
"a_string" : "test_string",
"a_number" : 123,
"a_null" : null,
"a_array" : [1, "2", {"123" : "123"}],
"a_object" : {
"a_name": "a_data"
},
"a_bool" : true
}
构造的方法也很简单:
boost::json::object val;
val["a_string"] = "test_string";
val["a_number"] = 123;
val["a_null"] = nullptr;
val["a_array"] = {
1, "2", boost::json::object({{"123", "123"}})
};
val["a_object"].emplace_object()["a_name"] = "a_data";
val["a_bool"] = true;
首先定义一个object,然后往里面塞东西就好。其中有一个emplace_object这个比较重要,后面会提到。
结果:

使用std::initializer_list
Boost.JSON支持使用std::initializer_list来构造自己的对象。所以也可以这样使用:
boost::json::value val2 = {
{"a_string", "test_string"},
{"a_number", 123},
{"a_null", nullptr},
{"a_array", {1, "2", {{"123", "123"}}}},
{"a_object", {{"a_name", "a_data"}}},
{"a_bool", true}
};
结果如下:

json对象的输出
生成了json对象以后,就可以使用serialize对对象进行序列化了。
std::cout << boost::json::serialize(val2) << std::endl;
结果如前两图。
除了直接把整个对象直接输出,Boost.JSON还支持分部分进行流输出,这种方法在数据量较大时,可以有效降低内存占用。
boost::json::serializer ser;
ser.reset(&val);
char temp_buff[6];
while (!ser.done()) {
std::memset(temp_buff, 0, sizeof(char) * 6);
ser.read(temp_buff, 5);
std::cout << temp_buff << std::endl;
}
结果:
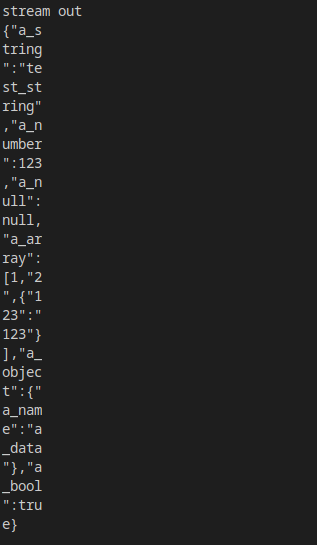
如果缓存变量是数组,还可以直接使用ser.read(temp_buff)。
需要注意的是,ser.read并不会默认在字符串末尾加\0,所以如果需要直接输出,在输入时对缓存置0,同时为\0空余一个字符。
也可以直接使用输出的boost::string_view。
两种对比
这两种方法对比的话,各有各的优点。前一种方法比较时候边运行边生成,后者适合一开始就需要直接生成的情形,而且相对来说,后者显得比较的直观。
但是第二种方法有一个容易出现问题的地方。比如以下两个json对象:
// json1
[["data", "value"]]
//json2
{"data": "value"}
如果使用第二种方法进行构建,如果一不小心的话,就有可能写出一样的代码:
boost::json::value confused_json1 = {{"data", "value"}};
boost::json::value confused_json2 = {{"data", "value"}};
std::cout << "confused_json1: " << boost::json::serialize(confused_json1) << std::endl;
std::cout << "confused_json2: " << boost::json::serialize(confused_json2) << std::endl;
而得到的结果,自然也是一样的:
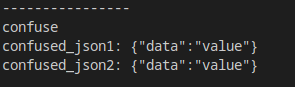
如果需要消除这一歧义,可以直接使用Boost.JSON提供的对象构建有可能产生歧义的地方:
boost::json::value no_confused_json1 = {boost::json::array({"data", "value"})};
boost::json::value no_confused_json2 = boost::json::object({{"data", "value"}});
结果为:
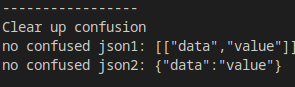
解码
JSON的解码也比较简单。
简单的解码
auto decode_val = boost::json::parse("{\"123\": [1, 2, 3]}");
直接使用boost::json::parse,输入相应的字符串就行了。
增加错误处理
boost::json::error_code ec;
boost::json::parse("{\"123\": [1, 2, 3]}", ec);
std::cout << ec.message() << std::endl;
boost::json::parse("{\"123\": [1, 2, 3}", ec);
std::cout << ec.message() << std::endl;
结果:
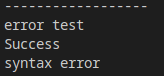
非严格模式
在这个模式下,Boost.JSON可以选择性的对一些不那么严重的错误进行忽略。
unsigned char buf[4096];
boost::json::static_resource mr(buf);
boost::json::parse_options opt;
opt.allow_comments = true; // 允许注释
opt.allow_trailing_commas = true; // 允许最后的逗号
boost::json::parse("[1, 2, 3, ] // comment test", ec, &mr, opt);
std::cout << ec.message() << std::endl;
boost::json::parse("[1, 2, 3, ] // comment test", ec, &mr);
std::cout << ec.message() << std::endl;
结果如下:
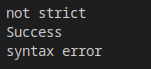
可以看到,增加了选项的解释器成功的解析了结果。
流输入
和输出一样,输入也有流模式。
boost::json::stream_parser p;
p.reset();
p.write("[1, 2,");
p.write("3]");
p.finish();
std::cout << boost::json::serialize(p.release()) << std::endl;
结果:
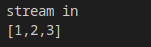
进阶应用
对象序列化
有时候我们需要将对象转换为JSON,对对象进行序列化然后保存。Boost.JSON提供了一个非常简单的方法,能够使我们非常简单的将一个我们自己定义的对象转化为JSON对象。
我们只需要在需要序列化的类的命名空间中,定义一个重载函数tag_invoke。注意,是类所在的命名空间,而不是在类里面定义。
使用示例:
namespace MyNameSpace {
class MyClass {
public:
int a;
int b;
MyClass (int a = 0, int b = 1):
a(a), b(b) {}
};
void tag_invoke(boost::json::value_from_tag, boost::json::value &jv, MyClass const &c) {
auto & jo = jv.emplace_object();
jo["a"] = c.a;
jo["b"] = c.b;
}
}
其中,boost::json::value_from_tag是作为标签存在的,方便Boost.JSON分辨序列化函数的。jv是输出的JSON对象,c是输入的对象。
boost::json::value_from(MyObj)
使用的话,直接调用value_from函数即可。
结果:
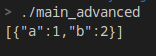
序列化还有一个好处就是,可以在使用std::initializer_list初始化JSON对象时,直接使用自定义对象。譬如:
boost::json::value val = {MyObj};
注意,这里的val是一个数组,里面包含了一个对象MyObj。
反序列化
有序列化,自然就会有反序列化。操作和序列化的方法差不多,也是定义一个tag_invoke函数,不过其参数并不一致。
MyClass tag_invoke(boost::json::value_to_tag<MyClass>, boost::json::value const &jv) {
auto &jo = jv.as_object();
return MyClass(jo.at("a").as_int64(), jo.at("b").as_int64());
}
需要注意的是,由于传入的jv是被const修饰的,所以不能类似于jv["a"]使用。
使用也和上面的类似,提供了一个value_to<>模板函数。
auto MyObj = boost::json::value_to<MyNameSpace::MyClass>(vj);
无论是序列化还是反序列化,对于标准库中的容器,Boost.JSON都可以直接使用。
Boost.JSON的类型
array
数组类型,用于储存JSON中的数组。实际使用的时候类似于std::vector<boost::json::value>,差异极小。
object
对象类型,用于储存JSON中的对象。实际使用时类似于std::map<std::string, boost::json::value>,但是相对来说,它们之间的差异较大。
string
字符串类型,用于储存JSON中的字符串。实际使用时和std::basic_string类似,不过其只支持UTF-8编码,如果需要支持其他编码,在解码时候需要修改option中相应的选项。
value
可以储存任意类型,也可以变换为各种类型。其中有一些特色的函数比如as_object,get_array,emplace_int64之类的。它们的工作都类似,将boost::json::value对象转化为对应的类型。但是他们之间也有一定的区别。
as_xxx返回一个引用,如果类型不符合,会抛出异常get_xxx返回一个引用,不检查类型,如果类型不符合,可能导致未定义行为is_xxx判断是否为xxx类型if_xxx返回指针,如果类型不匹配则返回nullptremplace_xxx返回一个引用,可以直接改变其类型和内容。
总结
大致的使用方法就这些了。如果还要更进一步的话,就是涉及到其内存管理了。
纵观整个库的话,感觉其对于模板的使用相当克制,能不使用就不使用,这在一定程度上也提高了编译的速度。
引用
博客原文:https://www.cnblogs.com/ink19/p/Boost_JSON.html
Boost.JSON Boost的JSON解析库(1.75首发)的更多相关文章
- C++的Json解析库:jsoncpp和boost
C++的Json解析库:jsoncpp和boost - hzyong_c的专栏 - 博客频道 - CSDN.NET C++的Json解析库:jsoncpp和boost 分类: 网络编程 开源库 201 ...
- C++的Json解析库:jsoncpp和boost(转)
原文转自 http://blog.csdn.net/hzyong_c/article/details/7163589 JSON(JavaScript Object Notation)跟xml一样也是一 ...
- [转]C++的Json解析库:jsoncpp和boost
JSON(JavaScript Object Notation)跟xml一样也是一种数据交换格式,了解json请参考其官网http://json.org,本文不再对json做介绍,将重点介绍c++的j ...
- Tomjson - 一个"短小精悍"的 json 解析库
Tomjson,一个"短小精悍"的 json 解析库,tomjson使用Java语言编写,主要作用是把Java对象(JavaBean)序列化为json格式字符串,将json格式字符 ...
- fastjson是阿里巴巴的开源JSON解析库
fastjson的API十分简洁. String text = JSON.toJSONString(obj); //序列化 VO vo = JSON.parseObject("{...}&q ...
- iOS开源JSON解析库MJExtension
iOS中JSON与NSObject互转有两种方式:1.iOS自带类NSJSONSerialization 2.第三方开源库SBJSON.JSONKit.MJExtension.项目中一直用MJExte ...
- python 中的json解析库
当一个json 数据很大的时候.load起来是很耗时的.python中常见的json解析库有cjson,simplesjson,json, 初步比较了一下, 对于loads来讲 simplejson ...
- Tomjson - json 解析库
Tomjson - 一个"短小精悍"的 json 解析库 Tomjson,一个"短小精悍"的 json 解析库,tomjson使用Java语言编写,主要作用是把 ...
- 开源解析库 - JSON
Json及其实现 JSON作为一种轻量级的数据交换格式,多被用于跨语言通信(比如CPP与PHP之间的数据交互). 至于何为JSON,其详细解释参考 官网. 既然是一种格式,那便必然有相应的编码实现.在 ...
随机推荐
- UnitTest_墨振文档
目录 一.框架介绍 1 二.四大组件 2 三.ddt数据驱动 3 一.框架介绍 unittest框架是python 自带的一个作为单元测试的测试框架,在最初叫pyUnit,相当与Java语言中的Jun ...
- 使用iOS 设备管理器 iMazing导出苹果设备中的录音文件
iMazing是一款功能强大的苹果设备管理软件,能为用户提供便捷的录音文件导出功能.用户可以直接将录音文件从苹果设备中导出,接下来,就让小编为大家演示一下如何操作吧. 图1:iMazing界面 1.打 ...
- 如何在Guitar Pro上添加吉他和弦
Guitar Pro是一款很适合广大吉他爱好者的优秀吉他谱学习与制谱软件,吉他爱好者可以使用它来更好的辅助自己学习吉他.在我们根据弹唱时,都会跟着谱子上标记的和弦来弹奏,不同的和弦有着不同的风格,或暗 ...
- FL Studio 插件使用教程 —— 3x Osc(下)
我们继续深入研究一下fl的3x Osc教程. 包络线是修饰音色非常重要的一个部件,有了它,音色不再是单调的长音,而能有长有短,有深有浅,变得丰富多彩.因此,学习包络线的运作原理很重要. 图1:包络线界 ...
- yii2.0 删除文件夹
/** * 删除文件缓存 */public function actionDelfilecache(){ $cachePath = Yii::getAlias('@app/runtime/cache' ...
- ucore操作系统学习(五) ucore lab5用户进程管理
1. ucore lab5介绍 ucore在lab4中实现了进程/线程机制,能够创建并进行内核线程的调度.通过上下文的切换令线程分时的获得CPU,使得不同线程能够并发的运行. 在lab5中需要更进一步 ...
- 体育成绩统计/ Score
偏水向,请部分学术控谅解 题目过长,不再描述. 很显然就是一道大模拟对吧,我在这里贡献一下我打此题的思路与过程. 或许有些奇淫巧技可以供一些没有过掉的神犇借鉴一下. 2020.11.26 中午: 昨天 ...
- uniapp分包(详尽版)
PS:本文是笔者对基于uniapp的一小程序项目进行分包后的复盘文档,不足之处请多多指教. 一:分包相关概念 本质上是改变项目的路由以及优化项目各个模块的启动时间的一种优化技术. 主包与分包的概念 1 ...
- Kafka速度为什么那么快
记录一下 Kafka速度为什么那么快 Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率. 即使是普通 ...
- 【GDKOI2014】JZOJ2020年8月13日提高组T3 壕壕的寒假作业
[GDKOI2014]JZOJ2020年8月13日提高组T3 壕壕的寒假作业 题目 Description Input Output 输出n行.第i行输出两个整数,分别表示第i份作业最早完成的时刻以及 ...