Kafka入门之broker-消息设计

消息设计
1.消息格式
Kafka的实现方式本质上是使用java NIO的ByteBuffer来保存消息,同时依赖文件系统提供的页缓存机制,而非依靠java的堆缓存。
2.版本变迁
0.11.0.0版本是kafka的一个里程碑式的大版本。特别是对于消息格式进行了改进和升级。kafka的消息版本变迁:
1.V0:指0.10.0.0之前的版本,是kafka最早的消息版本,格式如下:
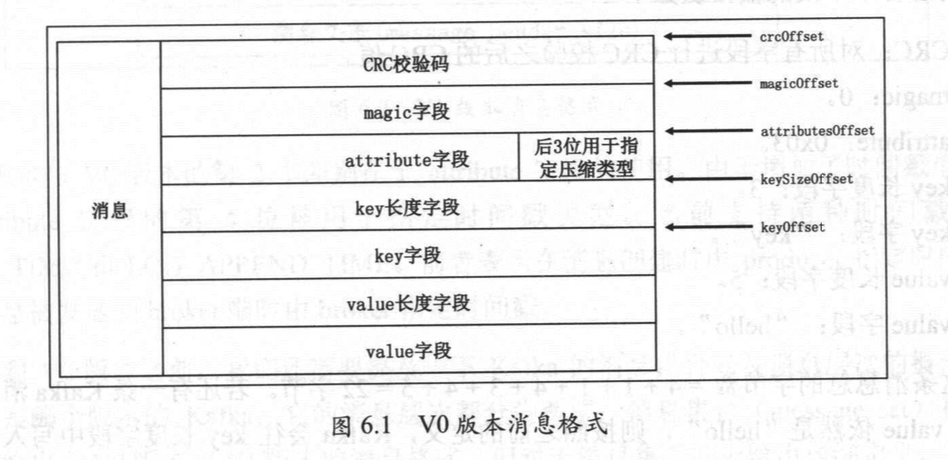
crc校验码:4字节,用于确保消息在传输过程中不会被恶意篡改。
magic:单字节的版本号,V0版本magic=0,V1版本magic=1,V2版本magic=2.
attribute:单字节属性字段,目前只使用低3位表示消息的压缩类型
key长度字段:4字节,若未指定key,则给该字段赋值为-1.
key值:
value长度字段:4字节,未指定value,则为-1。
value值:
2.V1:Kafka0.10.0.0中改进了V0版本的消息格式,推出了V1版本的格式,主要变化就是在消息中加入了时间戳字段。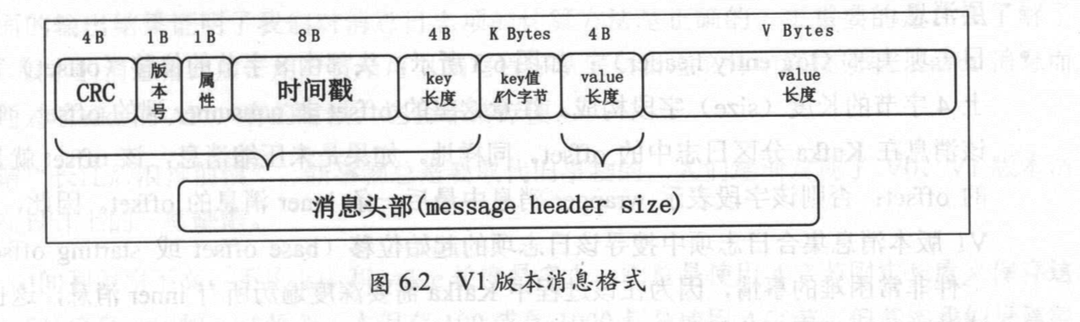
新增消息时间戳,并且attribute的第四位表示时间戳类型。
3.V2:
消息集合:一个消息集合包含若干日志项,而每个日志项都装了实际的消息和一组元数据信息。Kafka日志文件就是由一系列消息集合日志项构成的。Kafka不会在消息层面上直接操作,它总是在消息集合上进行写入操作。
V2版本之前的消息集合:

浅层消息+日志头部,头部由8字节位移(offset)字段加上4字节的长度(size)字段构成,这里的offset指的是该消息在Kafka分区日志中offset。如果未压缩该offset就是消息的offset,否则该字段表示wrapper消息中最后一条inner消息的offset。因此从v0,v1版本消息集合日志项中搜寻该日志项的起始位移是一件非常困难的事情,因为在该过程中Kafka需要深度便利所有inner消息,这也就意味着broker端需要执行解压缩的操作,可见代价之高。
V2版本消息格式: v2版本借鉴了Google ProtoBuffer中的zig-zag编码方式,使得绝对值较小的整数占用比较少的字节
v2版本借鉴了Google ProtoBuffer中的zig-zag编码方式,使得绝对值较小的整数占用比较少的字节
增加消息总长度字段:kafka操作消息时可直接获取总字节数,直接创建出等大小的ByteBuffer,然后分别填装其他字段,简化了消息处理过程,总字节数的引入还实现了消息遍历时的快速跳跃和过滤,省去了很多空间拷贝的开销。
保存时间戳增量:不再使用8字节保存时间戳信息,而是用可变长度保存与batch起始时间戳的差值
保存位移增量:保存消息位移与外层batch起始位置的差值,而不再固定保存8字节的位移值。
增加消息头部:对用户可见,v2版本中每条消息都必须有一个头部数组,每个头部信息都是一个key-value主要为了满足用户的一些定制化需求,比如,做集群间的消息路由或承载消息的一些特定元数据信息。
去除消息级CRC校验:对整个消息batch进行crc校验。
废弃attribute字段:v0,v1版本格式都有一个attribute字段,v2版本的消息正式废弃了这个字段,原先保存在attribute字段中的压缩类型,时间戳等信息都统一保存在外层的batch格式字段中,但v2版本依然保留了单字节的attribute字段留作以后扩展使用。
batch格式:

Kafka入门之broker-消息设计的更多相关文章
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- 【原创】Kafka 0.11消息设计
Kafka 0.11版本增加了很多新功能,包括支持事务.精确一次处理语义和幂等producer等,而实现这些新功能的前提就是要提供支持这些功能的新版本消息格式,同时也要维护与老版本的兼容性.本文将详细 ...
- Kafka设计解析(十六)Kafka 0.11消息设计
转载自 huxihx,原文链接 [原创]Kafka 0.11消息设计 目录 一.Kafka消息层次设计 1. v1格式 2. v2格式 二.v1消息格式 三.v2消息格式 四.测试对比 Kafka 0 ...
- 消息队列中间件(三)Kafka 入门指南
Kafka 来源 Kafka的前身是由LinkedIn开源的一款产品,2011年初开始开源,加入了 Apache 基金会,2012年从 Apache Incubator 毕业变成了 Apache 顶级 ...
- kafka入门教程链接
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12882 经典入门教程 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创 ...
- 【Kafka入门】Kafka基础结构和知识
基本概念的总结 在基本的Kafka架构中,producer将消息发布到Kafka话题中,一个Kafka话题通常指消息的类别或者名称,Kafka话题被集群中一个充当Kafka server角色的 bro ...
- Kafka 入门三问
目录 1 Kafka 是什么? 1.1 背景 1.2 定位 1.3 产生的原因 1.4 Kafka 有哪些特征 消息和批次 模式 主题和分区 生产者和消费者 broker 和 集群 1.5 Kafka ...
随机推荐
- 03 . Go框架之Gin框架从入门到熟悉(Cookie和Session,数据库操作)
Cookie Cookie是什么 HTTP是无状态协议,服务器不能记录浏览器的访问状态,也就是说服务器不能区分两次请求是否由同一个客户端发出 Cookie就是解决HTTP协议无状态的方案之一,中文是小 ...
- Luogu P1625 求和
题意 给定两个整数 \(n,m\),求 \[\sum\limits_{i=1}^{n}\frac{1}{\prod\limits_{j=i}^{i+m-1}j} \] \(\texttt{Data R ...
- 探索G1垃圾回收器
前言 最近王子因为个人原因有些忙碌,导致文章更新比较慢,希望大家理解,之后也会持续和小伙伴们一起共同分享技术干货. 上篇JVM的文章中我们对ParNew和CMS垃圾回收器已经有了一个比较透彻的认识,感 ...
- 用Matlab对导出的数据进行可视化
我这里是MapReduce导出的数据,MapReduce导出的数据中,Key和Value之间用制表符分隔的,可以直接作为表格型数据进行操作,复制一下导出的数据 1. 首先在Matlab工作区创建一个元 ...
- NoSQL数据库的四大分类的分析
分类 Examples举例 典型应用场景 数据模型 优点 缺点 键值(key-value) Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB 内容缓 ...
- Thinkphp3.2 cms之文章模块
二.文章模块 <?php namespace Admin\Controller; use Think\Controller; class NewController extends Common ...
- thinkphp之无限分类
namespace Home\Controller; use Home\Controller; class CategoryController extends Controller { //无限分类 ...
- leetcode1Minimum Depth of Binary Tree
题目描述 求给定二叉树的最小深度.最小深度是指树的根结点到最近叶子结点的最短路径上结点的数量. Given a binary tree, find its minimum depth.The mini ...
- PriorityQueue原理分析——基于源码
在业务场景中,处理一个任务队列,可能需要依照某种优先级顺序,这时,Java中的PriorityQueue(优先队列)便可以派上用场.优先队列的原理与堆排序密不可分,可以参考我之前的一篇博客: 堆排序总 ...
- Kubernetes+Promethues+Cloud Alert实践分享
前言 容器集群管理系统 Kubernetes(简称K8s),为容器化的应用提供部署运行.容器编排.负载均衡.服务发现和动态伸缩等一系列完整功能,Prometheus 对 K8s 支持非常棒,能够自动发 ...