[算法入门]——深度优先搜索(DFS)
深度优先搜索(DFS)
深度优先搜索叫DFS(Depth First Search)。OK,那么什么是深度优先搜索呢?_?
样例:
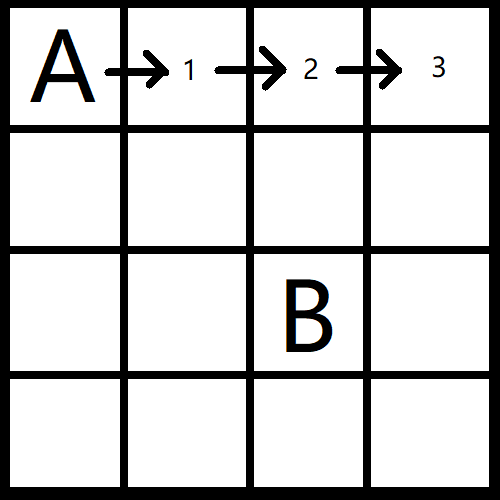
举个例子,你在一个方格网络中,可以简单理解为我们的地图,要从A点到B点找到最短路径:

我们要制定一个策略,以此来建立递归函数。在这种情况下,先往右一直走或往下走,如果往上走或往左走,便必然得不到最优解。
此时你从A点出发,一直朝着右走:
发现右边已经没有可以访问的节点了,再选择朝下递归:

此时找不到可以往右走或往下走的点了,所以只好返回,一直返回到第一个可用节点:
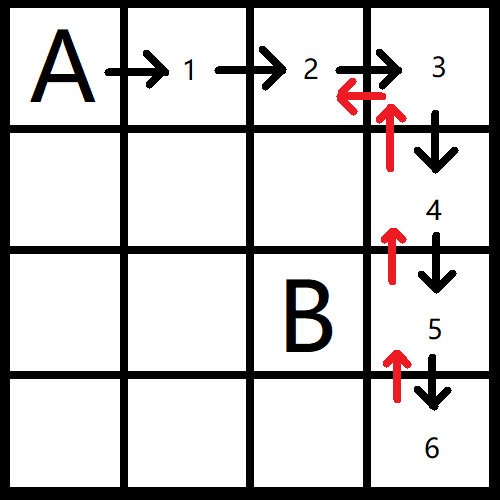
如上重复,在朝下递归:
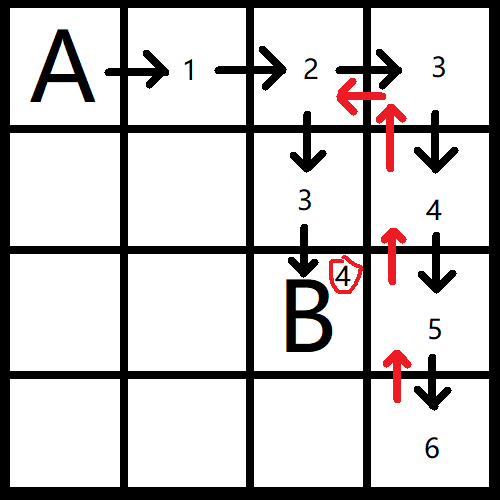
我们便得到了一个答案:4!虽然程序实际运行情况不会这么简单,所以有时需要考虑更加周到一点。但是我们知道这么多就够了。(你甚至可以写个断点来看它到底干了啥)。
以此,我们可以大体总结一下深度优先搜索的一个基本思想:从一个节点出发,一直到找不到可行节点时,再选择返回。
深度优先搜索是建立在以栈为基础的算法,而递归又恰好符合这个特性,我们可以大致写出深度优先搜索的伪代码:
void dfs(所走的次数, 其他参数)
{
if (找到了符合条件的节点)
{
//更新最小值
return;
}
for (遍历所有方法)
{
//如果找到了一个可行节点,便递归到下一个栈帧
if (该方法可行)
{
dfs(所走次数 + , 其他参数);
}
}
}
但是这样子写会有一个问题:同样的一个节点会被走很多次!这还不是最可怕的,在没有总结出 “如果往上走或往左走,便必然得不到最优解” 的情况下,甚至可能会出现程序放飞自我,A->B,然后B->A,如此死循环然后栈溢出。我们只好引用一个二维数组,只要走过这个节点便对其进行标记表示这里走过了,往后的递归就不能再访问此节点,来避免A->B B->A的尴尬情况。
void dfs(所走的次数, 其他参数)
{
if (找到了符合条件的节点)
{
//更新最小值
return;
}
for (遍历所有方法)
{
if (该方法可行)
{
//标记该节点走过
dfs(所走次数 + , 其他参数);
//回溯:将该节点标记未走过
}
}
}
既然我们写出了代码,为什么还要进行一个叫“回溯(sù)”的事情呢?我们写代码时不能保证一定可以得到最优解,或许从一条路搜索过来需要走5次,从另一条路走过来只要3次。如果没有回溯的话,就会使走过的节点无法再走,更优的解无法覆盖原来的解,需要3次的走法就无法覆盖只需要5次的走法,从而得不到最优解。尽管如此,深度优先搜索的时间开支依旧不小。再打个比方,你已经知道走这条路不是最优解了,但你还是不得不把它走完。所以,我们就需要用到剪枝来剔除不必要的搜索。在这里,剪枝方案就是:如果当前所使用的步数,已经大于等于到终点的所需的步数,那么就舍去这条路线。因为从此处为起点出发的任何一个节点都不可能是最优解了。
int ans = 0x7f7f7f7f //答案,初始值可以看做无限大
void dfs(所走的次数, 其他参数)
{
if (所走的次数 > ans)
{
return;
}
if (找到了符合条件的节点)
{
//更新最小值
return;
}
for (遍历所有方法)
{
if (该方法可行)
{
//标记该节点走过
dfs(所走次数 + , 其他参数);
//回溯:将该节点标记未走过
}
}
}
这样,就是一个标准的深度优先搜索模板。我们也可以针对其他例题进行修改(有些情况甚至连剪枝都剪不了)。
例题(洛谷P2404):
现在引入一道例题:
题目描述
任何一个大于1的自然数n,总可以拆分成若干个小于n的自然数之和。现在给你一个自然数n,要求你求出n的拆分成一些数字的和。每个拆分后的序列中的数字从小到大排序。然后你需要输出这些序列,其中字典序小的序列需要优先输出。
输入格式
输入:待拆分的自然数n。
输出格式
输出:若干数的加法式子。
输入输出样例
条件:
n ≤ 8
//从左到右的参数依次为:不能小于该数,现在选择第几个数字,数字之和
void dfs(int num, int now, int sum)
{
...
}
其中的num可以简化略掉,但是为了方便阅读还是加上去了。
那么,我们还需要一个数组来保存所找到的解,我们把它定义为s[10]。题目中n不会大于8,但是为了避免一些奇奇怪怪的错误,故开为10。很多以索引为1开头的写法,都推荐把数组开大一点(反正评测姬上的内存也不是自家的)。
//s数组用来存储当前的解。题目中给定n不可能大于8,但是为了避免一些奇怪的错误,故将数组s开大一点
int s[], n;
那么,如何判断是否找到了一个可行解呢?其实不难,当参数sum刚好等于n时,即可输出答案(不是大于等于),这样就无需去计算当期解的和,减少运算量。
//找到了一个可行解便打印出来
if (sum == n)
{
for (int i = ;i < now - ;i++)
printf ("%d+", s[i]);
printf ("%d\n", s[now - ]);
return;
}
那么接下来就是枚举所有可行的数字,此时num就派上用场了:接下来可行的数字一定在num到n之间。而now就是存储当前操作第几个数字的索引(索引听不懂的回去补课)
//遍历所有可行数字,如果是i<=n的话,深搜到最后会将n自己打印出来
for (int i = num;i < n;i++)
{
s[now] = i;
dfs(i, now + , sum + i);
s[now] = ; //此行可省略
}
代码中第6行可以省略。为什么可以省略呢?因为以我们的写法,是不会再次访问s[now]的,所以就没必要回溯。
全部代码:
#include <cstdio>
//s数组用来存储当前的解。题目中给定n不可能大于8,但是为了避免一些奇怪的错误,故将数组s开大一点
int s[], n;
//从左到右的参数依次为:不能小于该数,现在选择第几个数字,数字之和
void dfs(int num, int now, int sum)
{
//如果总和超过了n,就直接返回
if (sum > n)
return;
//找到了一个可行解便打印出来
if (sum == n)
{
for (int i = ;i < now - ;i++)
printf ("%d+", s[i]);
printf ("%d\n", s[now - ]);
return;
}
//遍历所有可行数字,如果是i<=n的话,深搜到最后会将n自己打印出来
for (int i = num;i < n;i++)
{
s[now] = i;
dfs(i, now + , sum + i);
s[now] = ; //此行可省略
}
}
int main()
{
scanf ("%d", &n);
dfs(, , );
return ;
}
总结:
深度优先搜索其中函数很好写,但是大体思路有一点难以理解,甚至会出现玄学代码的情况(改一个符号便出现完全例外的情况),所以写代码的时候要尽可能严谨,并且不要乱剪枝。深度优先搜索本质上是一个暴力算法,并且多以递归+回溯的形式出现,如果优化和剪枝不好并且数据刁钻,经常出现TLE的情况。
题外话:
这是我写的第一个博客,可能会出现一些奇奇怪怪的错误,不过可以在评论区留言,我一定会改的(艾玛好紧张QAQ)
[算法入门]——深度优先搜索(DFS)的更多相关文章
- 算法总结—深度优先搜索DFS
深度优先搜索(DFS) 往往利用递归函数实现(隐式地使用栈). 深度优先从最开始的状态出发,遍历所有可以到达的状态.由此可以对所有的状态进行操作,或列举出所有的状态. 1.poj2386 Lake C ...
- 【算法入门】深度优先搜索(DFS)
深度优先搜索(DFS) [算法入门] 1.前言深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法.它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解 ...
- [算法&数据结构]深度优先搜索(Depth First Search)
深度优先 搜索(DFS, Depth First Search) 从一个顶点v出发,首先将v标记为已遍历的顶点,然后选择一个邻接于v的尚未遍历的顶点u,如果u不存在,本次搜素终止.如果u存在,那么从u ...
- 深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记 引入 深度优先搜索 DFS 是图论中最基础,最重要的算法之一.DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 利用广度优先搜索(BFS)与深度优先搜索(DFS)实现岛屿个数的问题(java)
需要说明一点,要成功运行本贴代码,需要重新复制我第一篇随笔<简单的循环队列>代码(版本有更新). 进入今天的主题. 今天这篇文章主要探讨广度优先搜索(BFS)结合队列和深度优先搜索(DFS ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- 算法与数据结构基础 - 深度优先搜索(DFS)
DFS基础 深度优先搜索(Depth First Search)是一种搜索思路,相比广度优先搜索(BFS),DFS对每一个分枝路径深入到不能再深入为止,其应用于树/图的遍历.嵌套关系处理.回溯等,可以 ...
- 图的深度优先搜索(DFS)和广度优先搜索(BFS)算法
深度优先(DFS) 深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接 ...
随机推荐
- shell脚本带参数启动项目
用maven工程打包时,会将数据库连接一并打进去,如果需要经常修改数据库连接,则需要打开jar包然后修改配置,这样很麻烦耗时并且容易出错. 因此需要将数据库配置放入项目外,这样修改数据库时去固定的配置 ...
- Docker 概念-1
阅读本文大概需要15分钟,通过阅读本文你将知道一下概念: 容器 什么是Docker? Docker思想.特点 Docker容器主要解决什么问题 容器 VS 虚拟机 Docker基本概念: 镜像(Ima ...
- SpringBoot + Spring Cloud Eureka 服务注册与发现
什么是Spring Cloud Eureka Eureka是Netflix公司开发的开源服务注册发现组件,服务发现可以说是微服务开发的核心功能了,微服务部署后一定要有服务注册和发现的能力,Eureka ...
- 32,初探c++标准库
1. 有趣的重载 (1)操作符<<:原义是按位左移,重载“<<”可将变量或常量左移到对象中 重载左移操作符(仿cout类) #include<stdio.h> co ...
- webpack 4.x版本手动配置
运行 npm init -y 快速初始化项目 在项目根目录创建src源代码目录和dist产品目录 在src目录下创建 index.html mani.js文件如果后期使用entry打包,这里可以手动创 ...
- 动态规划入门(dp)
dp的基本思想,是把大问题转化成一个个小问题,然后递归解决. 所以本质思想的话还是递归. dp最重要的是要找到状态转移方程,也就是把大问题化解的过程. 举个例子 一个数字金字塔 在上面的数字三角形中寻 ...
- Day13_Thymeleaf简介
学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"乐优商城"获取视频和教程资料! b站在线视频 1.Th ...
- 设在起始地址为STRING的存储空间存放了一个字符串(该串已存放在内存中,无需输入,且串长不超过99),统计字符串中字符“A”的个数,并将结果显示在屏幕上。
问题 设在起始地址为STRING的存储空间存放了一个字符串(该串已存放在内存中,无需输入,且串长不超过99),统计字符串中字符"A"的个数,并将结果显示在屏幕上. 代码 data ...
- luogu P6087 [JSOI2015]送礼物 二分 单调队列 决策单调性
LINK:送礼物 原本想了一个 \(nlog^2\)的做法 然后由于线段树常数过大 T到30. 以为这道题卡\(log^2\)没想到真的有神仙写\(log^2\)的过了 是我常数大了 抱歉. 能过的\ ...
- 回首Java——再回首JDK
如果你是刚要被Java军训的新兵,可有几时对环境搭建而不知所措?又如若你是驰骋Java战场多年的老将,可曾拿起陪伴你许久的82年的JDK回味一番?今天我们就来道一道JDK,重新来认识认识这个既熟悉又陌 ...