Spark底层原理详细解析(深度好文,建议收藏)
Spark简介
Apache Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执行原理。
Spark运行流程
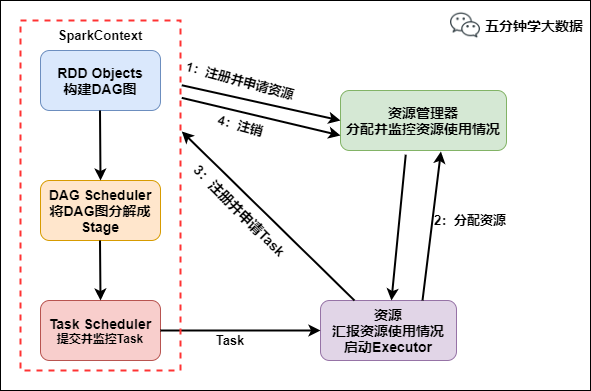
具体运行流程如下:
SparkContext 向资源管理器注册并向资源管理器申请运行Executor
资源管理器分配Executor,然后资源管理器启动Executor
Executor 发送心跳至资源管理器
SparkContext 构建DAG有向无环图
将DAG分解成Stage(TaskSet)
把Stage发送给TaskScheduler
Executor 向 SparkContext 申请 Task
TaskScheduler 将 Task 发送给 Executor 运行
同时 SparkContext 将应用程序代码发放给 Executor
Task 在 Executor 上运行,运行完毕释放所有资源
1. 从代码角度看DAG图的构建
Val lines1 = sc.textFile(inputPath1).map(...).map(...)
Val lines2 = sc.textFile(inputPath2).map(...)
Val lines3 = sc.textFile(inputPath3)
Val dtinone1 = lines2.union(lines3)
Val dtinone = lines1.join(dtinone1)
dtinone.saveAsTextFile(...)
dtinone.filter(...).foreach(...)
上述代码的DAG图如下所示:
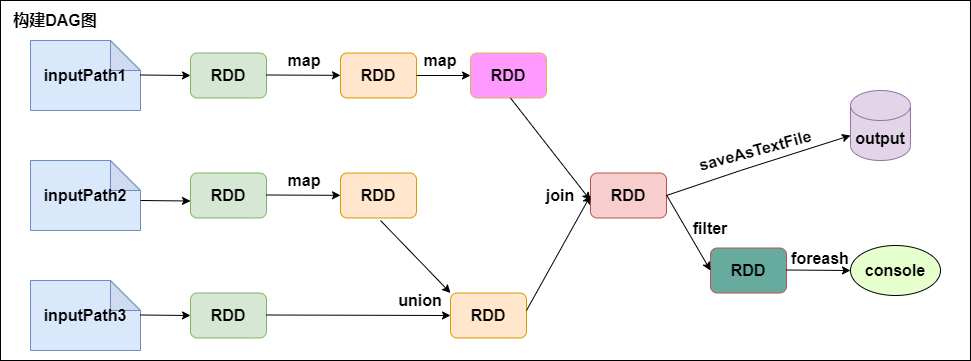
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是如上图所示的DAG。
Spark 的计算发生在RDD的Action操作,而对Action之前的所有Transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算。
2. 将DAG划分为Stage核心算法
一个Application可以有多个job多个Stage:
Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:
Stage划分的依据就是宽依赖,像reduceByKey,groupByKey等算子,会导致宽依赖的产生。
回顾下宽窄依赖的划分原则:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖。即一对一或者多对一的关系,可理解为独生子女。 常见的窄依赖有:map、filter、union、mapPartitions、mapValues、join(父RDD是hash-partitioned)等。
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)。即一对多的关系,可理解为超生。 常见的宽依赖有groupByKey、partitionBy、reduceByKey、join(父RDD不是hash-partitioned)等。
核心算法:回溯算法
从后往前回溯/反向解析,遇到窄依赖加入本Stage,遇见宽依赖进行Stage切分。
Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个Stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的Stage,那个RDD就是新的Stage的最后一个RDD。
然后依次类推,继续倒推,根据窄依赖或者宽依赖进行Stage的划分,直到所有的RDD全部遍历完成为止。
3. 将DAG划分为Stage剖析
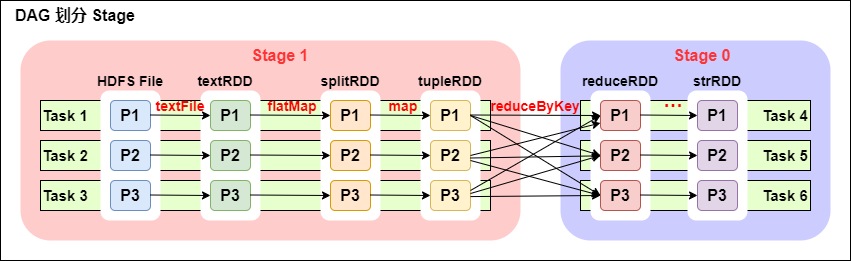
一个Spark程序可以有多个DAG(有几个Action,就有几个DAG,上图最后只有一个Action(图中未表现),那么就是一个DAG)。
一个DAG可以有多个Stage(根据宽依赖/shuffle进行划分)。
同一个Stage可以有多个Task并行执行(task数=分区数,如上图,Stage1 中有三个分区P1、P2、P3,对应的也有三个 Task)。
可以看到这个DAG中只reduceByKey操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage。
同时我们可以注意到,在图中Stage1中,从textFile到flatMap到map都是窄依赖,这几步操作可以形成一个流水线操作,通过flatMap操作生成的partition可以不用等待整个RDD计算结束,而是继续进行map操作,这样大大提高了计算的效率。
4. 提交Stages
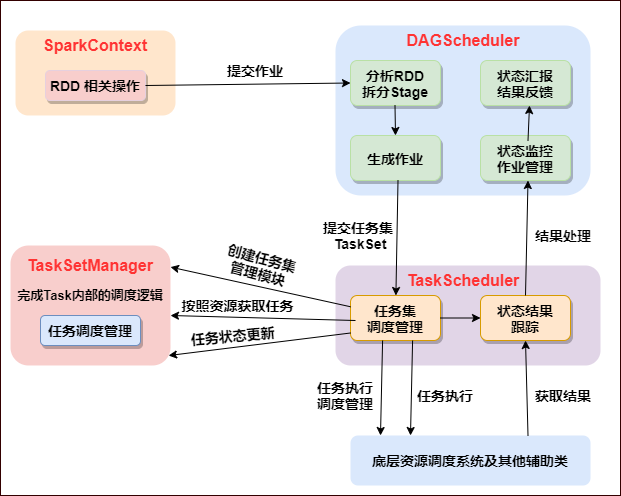
调度阶段的提交,最终会被转换成一个任务集的提交,DAGScheduler通过TaskScheduler接口提交任务集,这个任务集最终会触发TaskScheduler构建一个TaskSetManager的实例来管理这个任务集的生命周期,对于DAGScheduler来说,提交调度阶段的工作到此就完成了。
而TaskScheduler的具体实现则会在得到计算资源的时候,进一步通过TaskSetManager调度具体的任务到对应的Executor节点上进行运算。
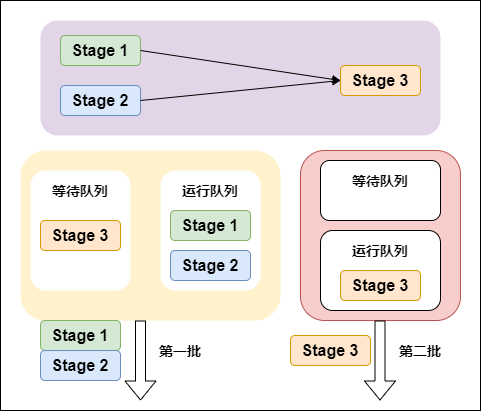
5. 监控Job、Task、Executor
- DAGScheduler监控Job与Task:
要保证相互依赖的作业调度阶段能够得到顺利的调度执行,DAGScheduler需要监控当前作业调度阶段乃至任务的完成情况。
这通过对外暴露一系列的回调函数来实现的,对于TaskScheduler来说,这些回调函数主要包括任务的开始结束失败、任务集的失败,DAGScheduler根据这些任务的生命周期信息进一步维护作业和调度阶段的状态信息。
- DAGScheduler监控Executor的生命状态:
TaskScheduler通过回调函数通知DAGScheduler具体的Executor的生命状态,如果某一个Executor崩溃了,则对应的调度阶段任务集的ShuffleMapTask的输出结果也将标志为不可用,这将导致对应任务集状态的变更,进而重新执行相关计算任务,以获取丢失的相关数据。
6. 获取任务执行结果
- 结果DAGScheduler:
一个具体的任务在Executor中执行完毕后,其结果需要以某种形式返回给DAGScheduler,根据任务类型的不同,任务结果的返回方式也不同。
- 两种结果,中间结果与最终结果:
对于FinalStage所对应的任务,返回给DAGScheduler的是运算结果本身。
而对于中间调度阶段对应的任务ShuffleMapTask,返回给DAGScheduler的是一个MapStatus里的相关存储信息,而非结果本身,这些存储位置信息将作为下一个调度阶段的任务获取输入数据的依据。
- 两种类型,DirectTaskResult与IndirectTaskResult:
根据任务结果大小的不同,ResultTask返回的结果又分为两类:
如果结果足够小,则直接放在DirectTaskResult对象内中。
如果超过特定尺寸则在Executor端会将DirectTaskResult先序列化,再把序列化的结果作为一个数据块存放在BlockManager中,然后将BlockManager返回的BlockID放在IndirectTaskResult对象中返回给TaskScheduler,TaskScheduler进而调用TaskResultGetter将IndirectTaskResult中的BlockID取出并通过BlockManager最终取得对应的DirectTaskResult。
7. 任务调度总体诠释
一张图说明任务总体调度:
Spark运行架构特点
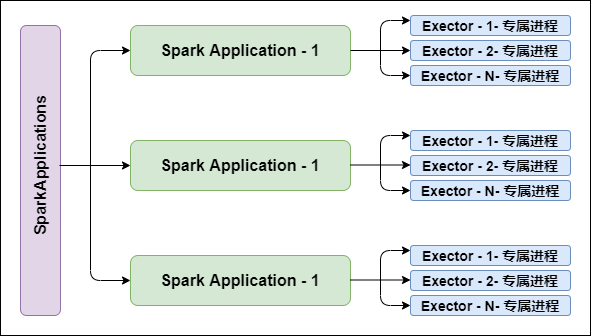
1. Executor进程专属
每个Application获取专属的Executor进程,该进程在Application期间一直驻留,并以多线程方式运行Tasks。
Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。如图所示:
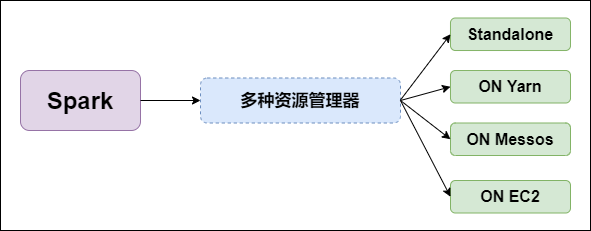
2. 支持多种资源管理器
Spark与资源管理器无关,只要能够获取Executor进程,并能保持相互通信就可以了。
Spark支持资源管理器包含: Standalone、On Mesos、On YARN、Or On EC2。如图所示:
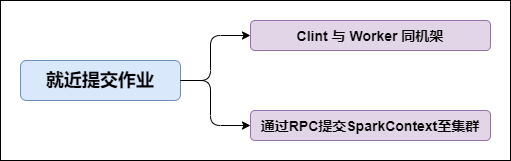
3. Job提交就近原则
提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack(机架)里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;
如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
如图所示:
4. 移动程序而非移动数据的原则执行
移动程序而非移动数据的原则执行,Task采用了数据本地性和推测执行的优化机制。
关键方法:taskIdToLocations、getPreferedLocations。
如图所示:
搜索公众号:五分钟学大数据,深度钻研大数据技术!
Spark底层原理详细解析(深度好文,建议收藏)的更多相关文章
- Flink 中极其重要的 Time 与 Window 详细解析(深度好文,建议收藏)
前言 Flink 是流式的.实时的 计算引擎 上面一句话就有两个概念,一个是流式,一个是实时. 流式:就是数据源源不断的流进来,也就是数据没有边界,但是我们计算的时候必须在一个有边界的范围内进行,所以 ...
- C++多态的实现及原理详细解析
C++多态的实现及原理详细解析 作者: 字体:[增加 减小] 类型:转载 C++的多态性用一句话概括就是:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型 ...
- jdk动态代理和cglib动态代理底层实现原理详细解析(cglib动态代理篇)
代理模式是一种很常见的模式,本文主要分析cglib动态代理的过程 1. 举例 使用cglib代理需要引入两个包,maven的话包引入如下 <!-- https://mvnrepository.c ...
- Spark底层原理简化版
目录 Spark SQL/DF的执行过程 集群运行部分 Aggregation Join Shuffle Tungsten 内存管理机制 缓存敏感计算(Cacheaware computation) ...
- spring boot 启动原理详细解析
我们开发任何一个Spring Boot项目,都会用到如下的启动类 1 @SpringBootApplication 2 public class Application { 3 public stat ...
- delphi程序设计之底层原理(有些深度)
虽然用delphi也有7,8年了,但大部分时间还是用在系统的架构上,对delphi底层还是一知半解,今天在网上看到一篇文章写得很好,虽然是07年的,但仍有借鉴的价值. 现摘录如下: Delphi程序设 ...
- NormalMap原理详细解析
NormalMap的实现标志着对渲染流水线的各个环节以及矩阵变化有了正确和深入的认识.这里记录一下学习过程,以及关于NormalMap的诸多细节. 刚开始想要实现NormalMap程序的时候,查阅的是 ...
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 0x00 摘要 0 ...
随机推荐
- idea修改项目名导致无法找到主类
描述 本地创建项目copy或者是修改项目名和文件夹名称后 启动springboot项目失败 控制台报错 错误无法找到主类 解决办法 1. 求助互联网得知 需要执行 mvn clean install( ...
- 为什么MySQL不推荐使用uuid作为主键?
前言 在mysql中设计表的时候,mysql官方推荐不要使用uuid或者不连续不重复的雪花id(long形且唯一,单机递增),而是推荐连续自增的主键id,官方的推荐是auto_increment,那么 ...
- 在 easyui中获取form表单中所有提交的数据 拼接到table列表中
form表单===== <!-- 并用药品填写信息弹框 --> <div id="usingProdctMsgDiv" style="display: ...
- C#自定义TemplateImage使用模板底图,运行时根据用户或产品信息生成海报图(1)
由于经常需要基于固定的一个模板底图,生成微信小程序分享用的海报图,如果每次都调用绘图函数,手动编写每个placeholder的填充,重复而且容易出错,因此,封装一个TemplateImage,用于填充 ...
- JDBC访问数据库的基本步骤是什么?
1.加载(注册)数据库驱动(到JVM) 2.建立(获取)数据库连接. 3.创建(获取)数据库操作对象. 4.定义操作的SQL语句. 5.执行数据库操作. 6.获取并操作结果集. 7.关闭对象,回收数据 ...
- yum被系统升级锁定
Another app is currently holding the yum lock; waiting for it to exit... 可能是系统自动升级正在运行,yum在锁定状态中. 已经 ...
- Java JVM——8.堆
堆的核心概念 堆针对一个 JVM 进程来说是唯一的,也就是一个进程只有一个JVM,但是进程包含多个线程,他们是共享同一堆空间的. 一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域. J ...
- leetcode网站中找到的关于trie树的JAVA版本介绍
class TrieNode { // R links to node children private TrieNode[] links; private final int R = 26; pri ...
- IDEA中配置Git,在Github上clone项目到IDEA
一.安装git 1.用homebrew安装git 运行以下命令安装 brew install git 默认的安装位置是 /usr/local/Cellar目录中(后面会用到) 二.在idea中配置Gi ...
- 使用postman添加cookie失败和cookie消失问题
例如 groupId=2; path=/; domain=.www.baidu.com; HttpOnly; Expires=Tue, 16 Jul 2019 03:42:12 GMT; 添加失败和c ...