数据可视化之powerBI技巧(七)从Excel到PowerBI,生成笛卡尔积的几种方式
假如分别有100个不重复的姓和名,把每个姓和名进行组合匹配,就可以得到一万个不重复的姓名组合,这种完全匹配的方式就是生成一个姓名的笛卡尔积。
下面就来看看生成笛卡尔积的几种方式,为了展现的方便,以5个姓和5个名为例,更多的数据也是一样操作的。
在Excel中生成笛卡尔积
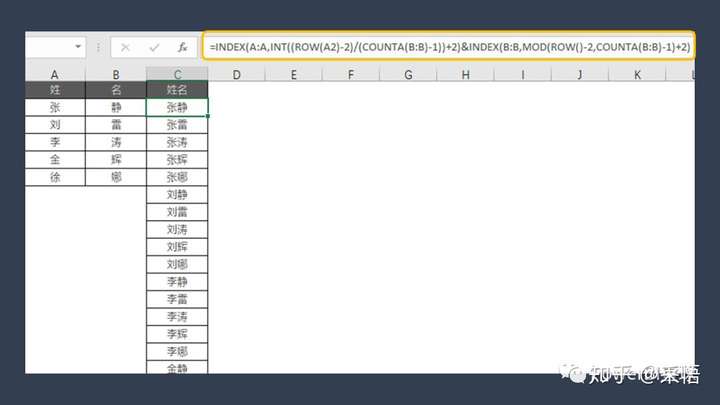
在Excel中可以利用INDEX函数实现,假如A列是姓,B列是名,那么在C2中输入公式:
C2=
INDEX(A:A,INT((ROW(A2)-2)/(COUNTA(B:B)-1))+2)&
INDEX(B:B,MOD(ROW()-2,COUNTA(B:B)-1)+2)
然后公式向下填充,就可以在C列生成笛卡尔积。
在Power Query中生成笛卡尔积
在PQ中相比Excel要简单的多,假如有两个表,'姓'和'名',操作步骤如下,
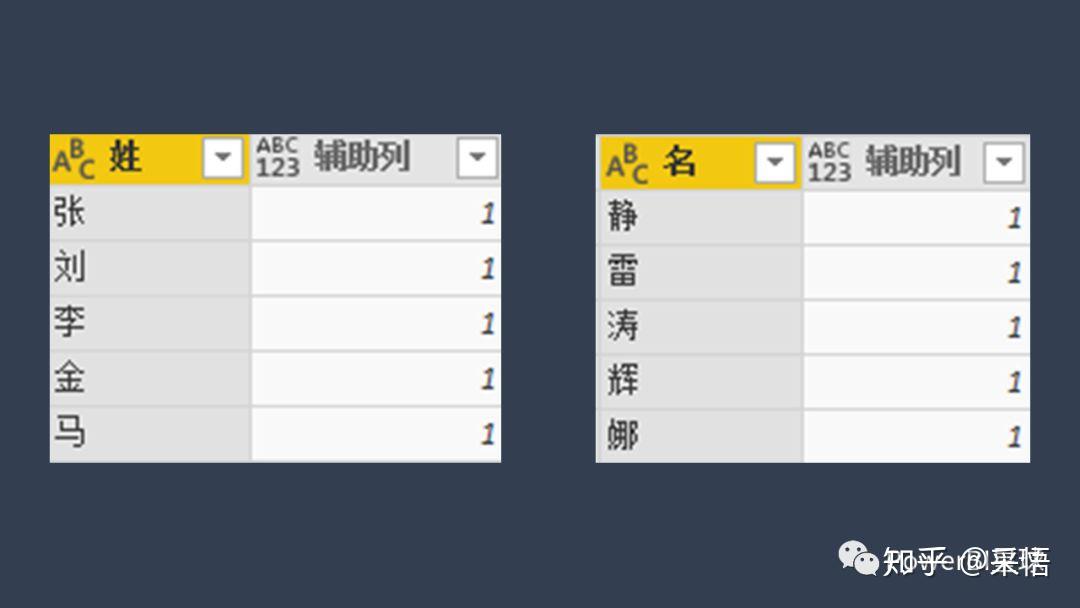 ↑添加辅助列,值设置为1(或其他任何值)
↑添加辅助列,值设置为1(或其他任何值)
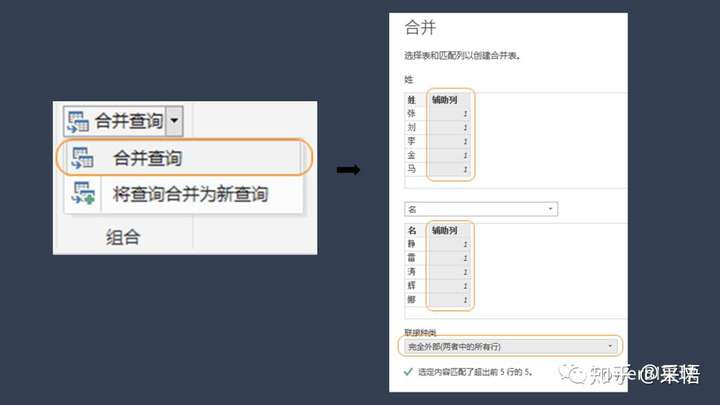 ↑合并查询-按辅助列-完全外部联结
↑合并查询-按辅助列-完全外部联结
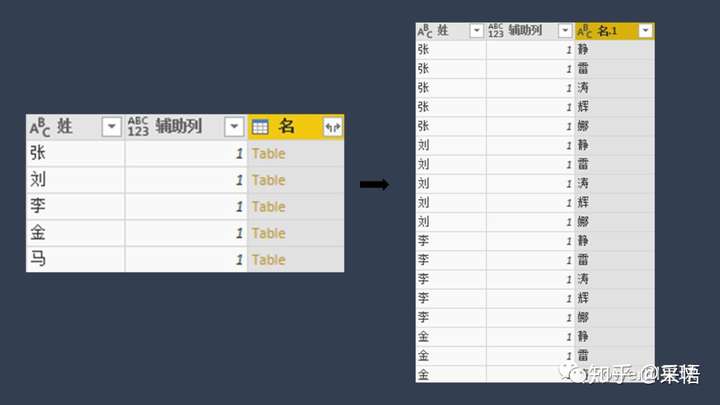 ↑展开合并查询
↑展开合并查询
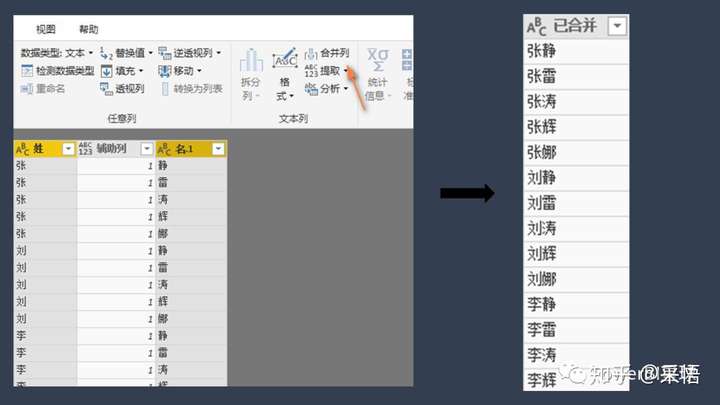 ↑合并列
↑合并列
通过简单的点击操作,就生成了一个笛卡尔积,虽然看起来步骤很多,其实就是秒秒钟的事。
使用DAX生成笛卡尔积
依然假设已经有两个表,'姓'和'名',在【建模】选项卡下点击"新表",输入,
姓名 = GENERATE('姓','名')
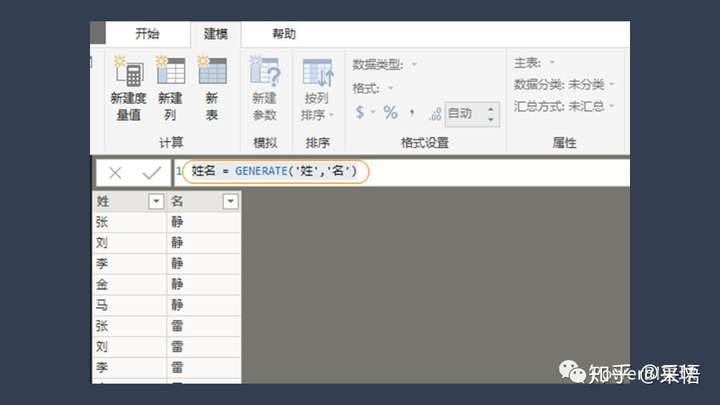
二者逐一匹配的笛卡尔积的结果就出来了,这里GENERATE函数还可以使用CROSSJOIN替代,效果是一样的。
当然我们并不想要姓和名分开为两列,而是想直接得到姓名合并的结果,可以用ADDCOLUMNS把这两列合并,再利用SELECTCOLUMNS函数提取出需要的列,把公式改为,
表=SELECTCOLUMNS(ADDCOLUMNS(CROSSJOIN('姓','名'),"姓名",[姓]&[名]),"姓名",[姓名])
一步实现最终结果,
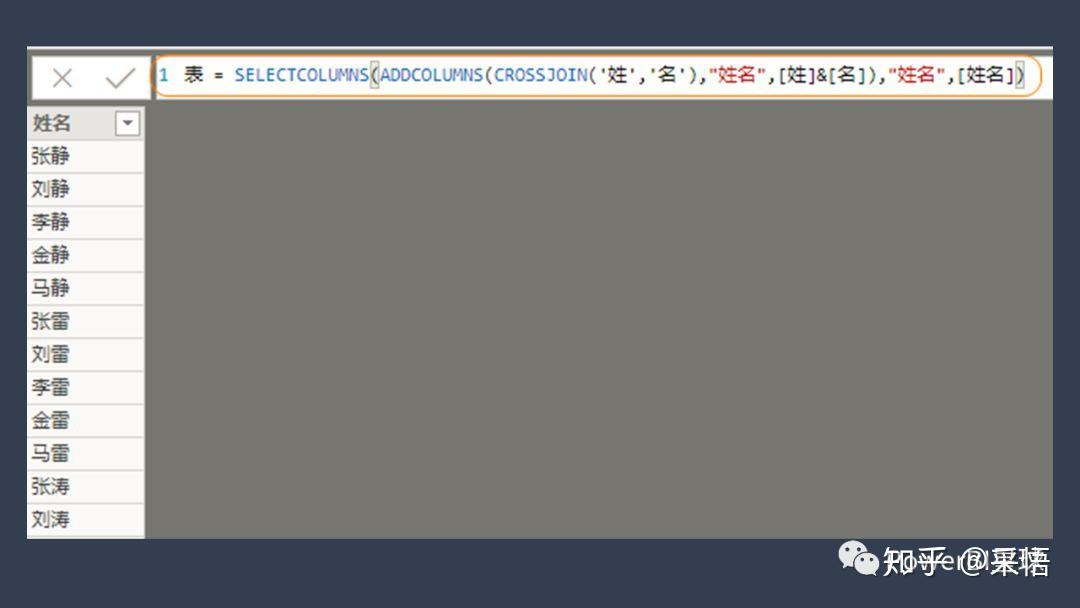
总结
以上三种方式操作起来都不难,数据处理虽不是DAX的长处,但也可以简单实现,学会这几个DAX函数,以后在数据分析时可以灵活构建度量。
当然在Power Query中最简单的,数据处理本来就是PQ的核心功能,这个案例中无需任何代码或者公式,只是通过简单的界面操作,就可以轻松完成。
在Excel中虽然也仅需一个公式,但能灵活使用INDEX函数的都是高手级的,能达到这个水平的人少之又少,大部分人看到这个公式可能也不理解,并且如果数据量较大,通过Excel处理速度也会变得很慢。
所以说学习Power Query可以让你在数据处理上弯道超车,轻松逆袭,之前在Excel中很难处理,或者需要用到各种稀奇古怪函数才能得到的结果,在PQ中都显得毫不费力。
数据可视化之powerBI技巧(七)从Excel到PowerBI,生成笛卡尔积的几种方式的更多相关文章
- 数据可视化之powerBI技巧(六)在PowerBI中简单的操作,实现复杂的预测分析
时间序列预测就是利用过去一段时间内的数据来预测未来一段时间内该数据的走势,比如根据过去5年的销售数据进行来年的收入增长预测,根据上个季度的股票走势推测未来一周的股价变化等等. 对于大部分人来说,这是个 ...
- 数据可视化之DAX篇(十)在PowerBI中累计求和的两种方式
https://zhuanlan.zhihu.com/p/64418286 假设有一组数据, 已知每一个产品贡献的利润,如果要计算前几名产品的贡献利润总和,或者每一个产品和利润更高产品的累计贡献占总体 ...
- 数据可视化之DAX篇(五) 使用PowerBI的这两个函数,灵活计算各种占比
https://zhuanlan.zhihu.com/p/57861350 计算个体占总体的比例是一个很常见的分析方式,它很简单,就是两个数字相除,但是当需要计算的维度.总体的范围发生动态变化时,如何 ...
- 数据可视化之PowerQuery篇(十九)PowerBI数据分析实践第三弹 | 趋势分析法
https://zhuanlan.zhihu.com/p/133484654 本文为星球嘉宾"海艳"的PowerBI数据分析工作实践系列分享之三,她深入浅出的介绍了PowerBI ...
- 数据可视化基础专题(七):Pandas基础(六) 数据增删改以及相关操作
首先第一部还是导入 Pandas 与 NumPy ,并且要生成一个 DataFrame ,这里小编就简单的使用随机数的形式进行生成,代码如下: import numpy as np import pa ...
- Java常见重构技巧 - 去除不必要的!=null判断空的5种方式,很少有人知道后两种
常见重构技巧 - 去除不必要的!= 项目中会存在大量判空代码,多么丑陋繁冗!如何避免这种情况?我们是否滥用了判空呢?@pdai 常见重构技巧 - 去除不必要的!= 场景一:null无意义之常规判断空 ...
- HTML技巧篇:实现元素水平与垂直居中的几种方式
如何使用html+css实现元素的水平与垂直居中效果,这也是我们网页在编码制作中会经常用到的问题. 1)单行文本的居中 主要实现css代码: 水平居中:text-align:center;垂直居中:l ...
- 两种方式实现java生成Excel
Web应用中难免会遇到需要将数据导出并生成excel文件的需求.同样,对于本博客中的总结,也是建立在为了完成这样的一个需求,才开始去了解其实现形式,并且顺利完成需求的开发,先将实现过程总结于此.本博文 ...
- 超级干货 :一文读懂数据可视化 ZT
前言 数据可视化,是指将相对晦涩的的数据通过可视的.交互的方式进行展示,从而形象.直观地表达数据蕴含的信息和规律. 早期的数据可视化作为咨询机构.金融企业的专业工具,其应用领域较为单一,应用形态较为保 ...
随机推荐
- IAT表
0X0 0 DLL介绍 DLL翻译器为动态链接库,原来不存在DLL的概念只有,库的概念,编译器会把从库中获取的二进制代码插入到应用程序中.在现在windows操作系统使用了数量庞大的库函数(进程,内存 ...
- fopen函数中的mode参数
fopen FILE * fopen ( const char * filename, const char * mode ); 其中,参数mode可取以下值: "r"read: ...
- 使用三台云服务器搭建真正的Redis集群
三台云服务器搭建redis集群# 今天花了一天的时间弄集群redis:遇到了很多坑,从头开始吧 环境讲解: 两台配置:1核2G,另一台:1核1G: 操作系统:Centos 7.6 Redis:3.2. ...
- dB是乘以10还是乘以20
dB即分贝(decibel),经常用来表示信号的大小.然而,今天在学习计算机网络的时候发现分贝的公式有两种:10lg(X) 或者 20lg(X) 很迷惑所以查找资料.得到的结果是dB在表示功率的时候用 ...
- 无法解析的外部符号 "public: virtual struct CRuntimeClass * _
SetupPropertyPage.obj : error LNK2001: 无法解析的外部符号 "public: virtual struct CRuntimeClass * __this ...
- 对 JsonConvert 的认识太肤浅了,终于还是遇到了问题
一:背景 1. 讲故事 在开始本文之前,真的好想做个问卷调查,到底有多少人和我一样,对 JsonConvert 的认识只局限在 SerializeObject 和 DeserializeObject ...
- redis配置文件中slave-serve-stale-data的解释
redis.conf文件中可以看到slave-serve-stale-data这个参数,作用是什么? 原文解释: # When a slave loses its connection with th ...
- Java多线程之volatile详解
本文目录 从多线程交替打印A和B开始 Java 内存模型中的可见性.原子性和有序性 Volatile原理 volatile的特性 volatile happens-before规则 volatile ...
- 阿里巴巴--java多线程的两种实现方式,以及二者的区别
阿里巴巴面试的时候,昨天问了我java面试的时候实现java多线程的两种方式,以及二者的区别当时只回答了实现线程的两种方式,但是没有回答上二者的区别: java实现多线程有两种方式: 1.继承Thre ...
- caffe的python接口学习(5)生成deploy文件
如果要把训练好的模型拿来测试新的图片,那必须得要一个deploy.prototxt文件,这个文件实际上和test.prototxt文件差不多,只是头尾不相同而也.deploy文件没有第一层数据输入层, ...