ElasticSearch核心知识 -- 索引过程
1、索引过程图解:
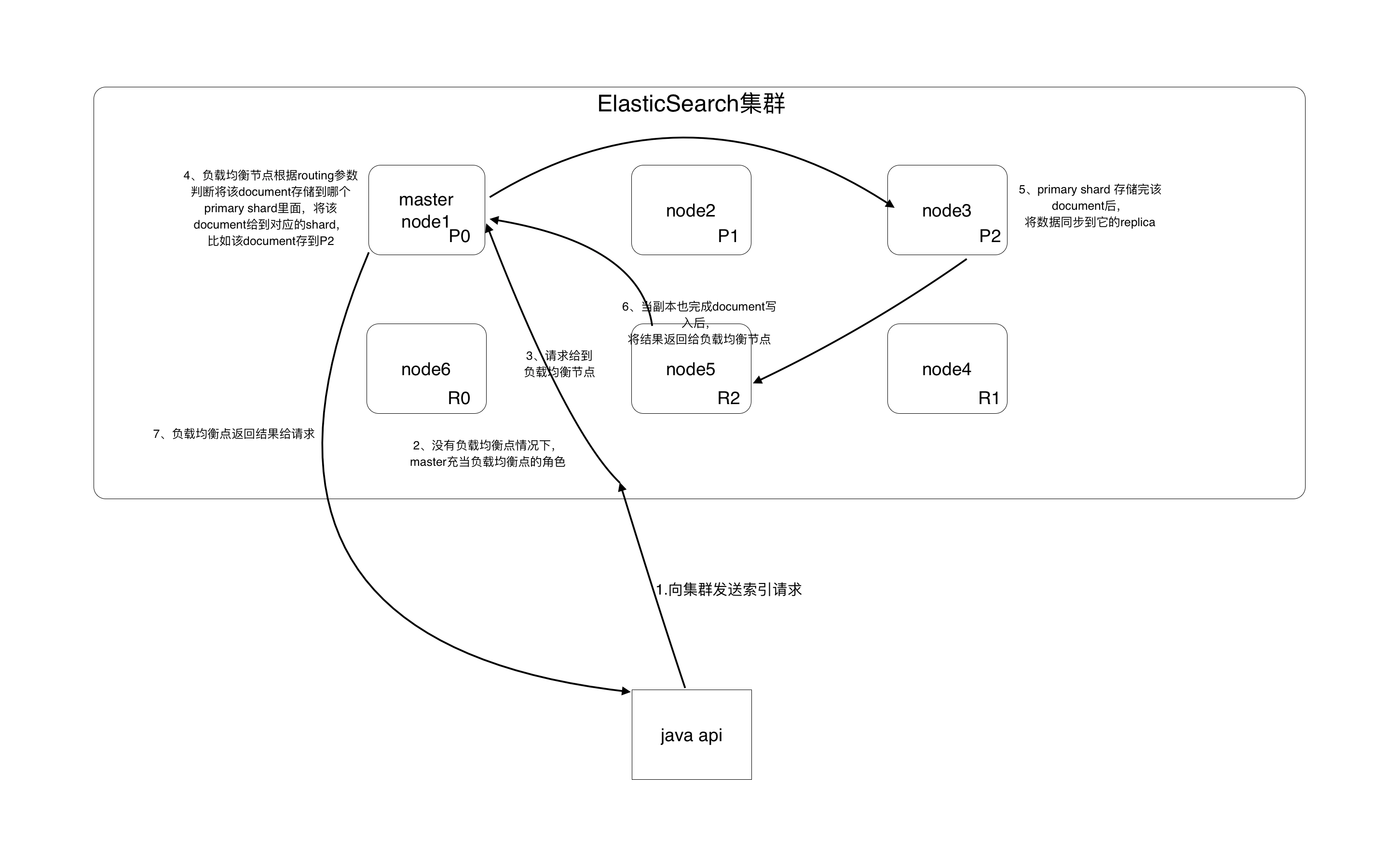
- api向集群发送索引请求,集群会使用负载均衡节点来处理该请求,如果没有单独的负载均衡点,master节点会充当负载均衡点的角色。
- 负载均衡节点根据routing参数来计算要将该索引存储到哪个primary shard上,然后将数据给到对应的shard。
- 对应的shard拿到数据后进行索引写入,写入成功后,将数据给到自己的replica shard。
- 当replica shard也将数据成功写入后,返回成功的结果到负载均衡节点。
- 此时负载均衡节点才认为数据写入成功,将成功索引的结果返回给请求的api
2、routing(路由)参数
2.1、routing参数的指定和计算原理
每个document存放在哪个shard上是由routing参数决定的,那这个参数的值是什么,ElasticSearch又是怎么通过该参数来确定存放在哪个shard上呢?
routing参数的默认值为_id,也可以进行手动指定routing参数,可以是值,也可以是某个字段:
PUT /index/type/id?routing=user_id
{
"user_id":"M9472323048",
"name":"zhangsan",
"age":54
}
ElasticSearch有个哈希算法,通过 Hash(routing) % number_of_shards算得存储到哪个shard上面去,比如上面的语句,假设Hash("M9472323048") = 23,该index含有3个shard,则存储到 23 % 3 = 2,即P2上面。shard编号取值为0 number_of_shards - 1。
2.2、手动指定routing和自动routing的区别
routing的值默认为_id字段,_id可以保证在集群中唯一,但是有时候需要手动指定routing来优化后续的查询过程。因为routing确定,那就可以指定用哪个routing进行查询,缩减了目标结果集,减少了ElasticSearch集群的压力。
- 使用自动routing:
- 优点: 简单,可以很均衡的分配每个shard中的文档数量,做到负载均衡
- 缺点: 当查询一下复杂的数据时,需要到多个shard中查找,查询偏慢
- 使用手动routing:
- 优点: 查询时指定当初入库的routing进行查询,锁定shard,直达目标,查询速度快
- 缺点: 麻烦,要保证存储的均衡比较复杂
ElasticSearch核心知识 -- 索引过程的更多相关文章
- ElasticSearch核心知识总结(二)
如何超出扩容极限,以及如何提升容错性 primary&replica自动负载均衡,6个shared,3个primary,3个replica,随着机器扩容,会被均衡分配到多台机器上 6个shar ...
- ElasticSearch核心知识总结(一)es的六种搜索方式和数据分析
es的六种搜索方式 query string search GET /ecommerce/product/_search //查询所有数据 { "took": 4,//耗费几毫秒 ...
- elasticsearch核心知识梳理
https://blog.csdn.net/laoyang360/article/details/52244917
- Elasticsearch核心知识大纲脑图
- Elasticsearch基础知识要点QA
前言:本文为学习整理实践他人成果的记录型博客.在此统一感谢各原作者,如果你对基础知识不甚了解,可以通过查看Elasticsearch权威指南中文版, 此处注意你的elasticsearch版本,版本不 ...
- Elasticsearch学习随笔(一)--原理理解与5.0核心插件部署过程
最近由于要涉及一些安全运维的工作,最近在研究Elasticsearch,为ELK做相关的准备.于是把自己学习的一些随笔分享给大家,进行学习,在部署常用插件的时候由于是5.0版本的Elasticsear ...
- ElasticSearch优化系列六:索引过程
大家可能会遇到索引数据比较慢的过程.其实明白索引的原理就可以有针对性的进行优化.ES索引的过程到相对Lucene的索引过程多了分布式数据的扩展,而这ES主要是用tranlog进行各节点之间的数据平衡. ...
- ElasticSearch入门知识扫盲
ElasticSearch 入门介绍 tags: 第三方 lucene [toc] 1. what Elastic Search(ES)是什么 全文检索和lucene 全文检索 优点:高效,准确,分词 ...
- Elasticsearch 基础知识要点与性能监控
本文的来源是我翻译国外的一篇技术博客,感谢原作者Emily Chang,原文地址通过如下的知识,我们能大致学到关于ES的一些基本知识,进而对elasticsearch的性能进行监控和调优 注意elas ...
随机推荐
- JavaScript系列----数据类型以及传值和传引用
1.简单数据类型 在JavaScript中简单数据类型分为5种.分别为 Undefined, Null,Boolean,Number,String. Undefined类型Undefined类型只有一 ...
- netty常用使用方式
最近在重新看netty,在这里总结一些netty的一些常用的使用方式,类似于模板,方便速查. 以netty 4.1.x的API作记录,不同版本可能API有略微差异,需要注意netty5被废弃掉了(辨别 ...
- 四:java调接口实现发送手机短信验证码功能
1.点击获取验证码之前的样式: 2.输入正确的手机号后点击获取验证码之后的样式: 3.如果手机号已经被注册的样式: 4.如果一个手机号一天发送超过3次就提示不能发送: 二:前台的注册页面的代码:reg ...
- C#的XML文件的读取与写入
在设计程序的时候,对于一些变化性较强的数据,可以保存在XML文件中,以方便用户修改.尤其是对于一些软硬件的配置文件,很多都选择了用XML文件来存取.XML文件简单易用,而且可以在任何应用程序中读写数据 ...
- 多线程+socket实现多人聊天室
最近在学习多线程的时候打算做一个简单的多线程socke聊天的程序,结果发现网上的代码都没有完整的实现功能,所以自己实现了一个demo: demo功能大致就是,有一个服务端负责信息转发,多个客户端发送消 ...
- mac 安装protobuf,并编译
因公司接口协议是PB文件,需要将 PB 编译成JAVA文件,且MAC 电脑,故整理并分享MAC安装 google 下的protobuf 文件 MAC 安装protobuf 流程 1.下载 http ...
- unique & lower_bound C++
原来C++也有unique和lower_bound,只需头文件iostream unique unique可以对数组进行相邻元素的"去重",实现效果是把所有不重复的元素按顺序放在数 ...
- x86平台上的Windows页表映射机制
首先,在x86架构的处理器上,一个正常页面大小为4KB,非PAE模式下,CR3持有页目录页面的物理地址,PDE和PTE格式相同大小为4字节.此时每个页表页面包含1024个PTE,可以映射1024个页面 ...
- JavaEE中的MVC(四)AOP代理
咱们来吹牛,JDK的动态代理在AOP(Aspect Oriented Programming,面向切面编程)中被称为AOP代理,而AOP是Spring框架中的重要组成部分. 代理模式 但是什么是代理模 ...
- Dynamics 365创建电子邮箱字段包含值的联系人同时更改负责人的方法。
摘要: 本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复267或者20171129可方便获取本文,同时可以在第一间得到我发布的最新的博文信息,follow me!我的网站是 www.luoyon ...