从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space
同步自我的知乎专栏文章:https://zhuanlan.zhihu.com/p/32135185
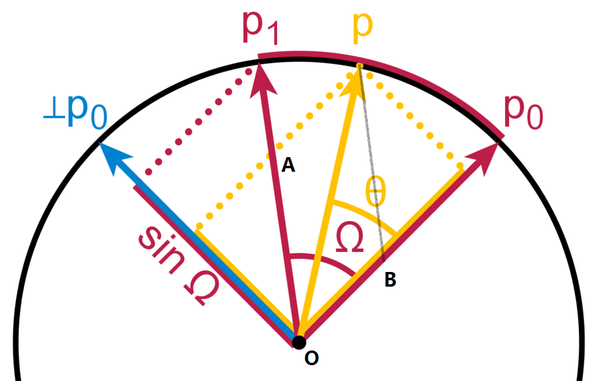
import numpy
from matplotlib import pyplot def dist_o2l(p1, p2):
# distance from origin to the line defined by (p1, p2)
p12 = p2 - p1
u12 = p12 / numpy.linalg.norm(p12)
l_pp = numpy.dot(-p1, u12)
pp = l_pp*u12 + p1
return numpy.linalg.norm(pp) dim = 100
N = 100000 rvs = []
dists2l = []
for i in range(N):
u = numpy.random.randn(dim)
v = numpy.random.randn(dim)
rvs.extend([u, v])
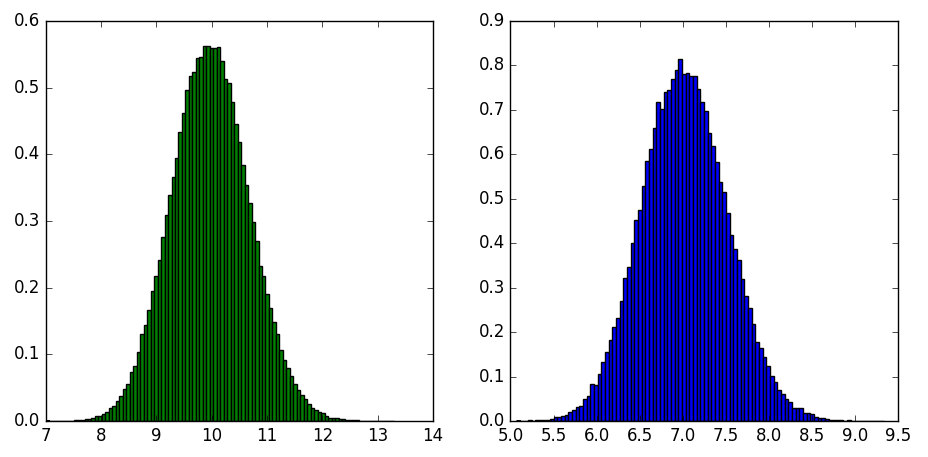
dists2l.append(dist_o2l(u, v)) dists = [numpy.linalg.norm(x) for x in rvs] print('Distances to samples, mean: {}, std: {}'.format(numpy.mean(dists), numpy.std(dists)))
print('Distances to lines, mean: {}, std: {}'.format(numpy.mean(dists2l), numpy.std(dists2l))) fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(11, 5))
ax0.hist(dists, 100, normed=1, color='g')
ax1.hist(dists2l, 100, normed=1, color='b')
pyplot.show()
结果如下:
















from __future__ import print_function
import argparse
import os
import numpy
from scipy.stats import chi
import torch.utils.data
from torch.autograd import Variable
from networks import NetG
from PIL import Image parser = argparse.ArgumentParser()
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--niter', type=int, default=10, help='how many paths')
parser.add_argument('--n_steps', type=int, default=23, help='steps to walk')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='netG_epoch_49.pth', help="trained params for G") opt = parser.parse_args()
output_dir = 'gcircle-walk'
os.system('mkdir -p {}'.format(output_dir))
print(opt) ngpu = int(opt.ngpu)
nz = int(opt.nz)
ngf = int(opt.ngf)
nc = 3 netG = NetG(ngf, nz, nc, ngpu)
netG.load_state_dict(torch.load(opt.netG, map_location=lambda storage, loc: storage))
netG.eval()
print(netG) for j in range(opt.niter):
# step 1
r = chi.rvs(df=100) # step 2
u = numpy.random.normal(0, 1, nz)
w = numpy.random.normal(0, 1, nz)
u /= numpy.linalg.norm(u)
w /= numpy.linalg.norm(w) v = w - numpy.dot(u, w) * u
v /= numpy.linalg.norm(v) ndimgs = []
for i in range(opt.n_steps):
t = float(i) / float(opt.n_steps)
# step 3
z = numpy.cos(t * 2 * numpy.pi) * u + numpy.sin(t * 2 * numpy.pi) * v
z *= r noise_t = z.reshape((1, nz, 1, 1))
noise_t = torch.FloatTensor(noise_t)
noisev = Variable(noise_t)
fake = netG(noisev)
timg = fake[0]
timg = timg.data timg.add_(1).div_(2)
ndimg = timg.mul(255).clamp(0, 255).byte().permute(1, 2, 0).numpy()
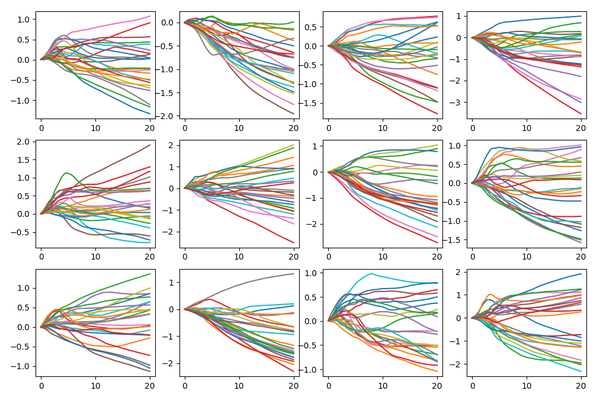
ndimgs.append(ndimg) print('exporting {} ...'.format(j))
ndimg = numpy.hstack(ndimgs) im = Image.fromarray(ndimg)
filename = os.sep.join([output_dir, 'gc-{:0>6d}.png'.format(j)])
im.save(filename)
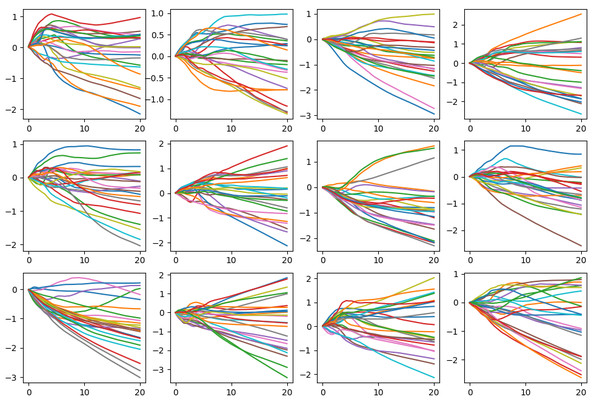
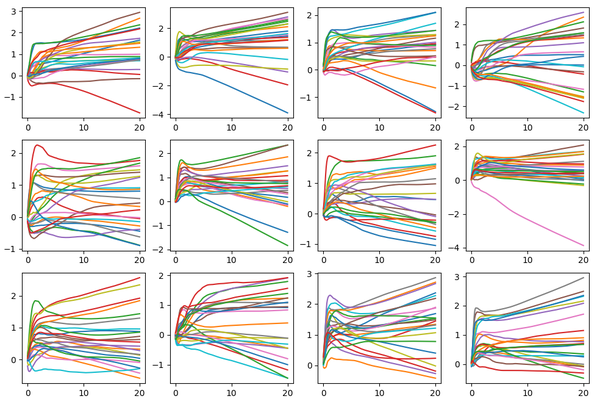
结果如下:








从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space的更多相关文章
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- Steve Lin:如何撰写一篇优秀的SIGGRAPH论文
Lin:如何撰写一篇优秀的SIGGRAPH论文" title="Steve Lin:如何撰写一篇优秀的SIGGRAPH论文"> 英文原版 PPT下载:http:// ...
- 复现ICCV 2017经典论文—PyraNet
. 过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”.这是今年 AAAI 会议上一个严峻的 ...
- ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作
编者按:你是否曾经为如何创作和编辑一篇图文并茂.排版精美的文章而烦恼?或是为缺乏艺术灵感和设计思路而痛苦?AI技术能否在艺术设计中帮助到我们?今天我们为大家介绍的这篇论文,“Automatic Gen ...
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
周末看了一下这篇论文,觉得挺难的,后来想想是ICML的论文,也就明白为什么了. 先简单记录下来,以后会继续添加内容. 主要参考了论文Web-Scale Bayesian Click-Through R ...
- Steve Lin:如何撰写一篇优秀的SIGGRAPH论文
英文原版 PPT下载:http://vdisk.weibo.com/s/z7VKRh2i3R4YO 一篇优秀的论文应该是这样的 广大的研究同仁介绍了这篇论文所包含的重要想法和所获得的结果 在论文中描 ...
- 国内首篇云厂商 Serverless 论文入选全球顶会:突发流量下,如何加速容器启动?
作者 | 王骜 来源 | Serverless 公众号 导读 USENIX ATC (USENIX Annual Technical Conference) 学术会议是计算机系统领域的顶级会议,入 ...
- 【深度学习 论文篇 01-1 】AlexNet论文翻译
前言:本文是我对照原论文逐字逐句翻译而来,英文水平有限,不影响阅读即可.翻译论文的确能很大程度加深我们对文章的理解,但太过耗时,不建议采用.我翻译的另一个目的就是想重拾英文,所以就硬着头皮啃了.本文只 ...
- MetaQNN : 与Google同场竞技,MIT提出基于Q-Learning的神经网络搜索 | ICLR 2017
论文提出MetaQNN,基于Q-Learning的神经网络架构搜索,将优化视觉缩小到单层上,相对于Google Brain的NAS方法着眼与整个网络进行优化,虽然准确率差了2-3%,但搜索过程要简单地 ...
随机推荐
- Java设计模式相关面试
1.接口是什么?为什么要使用接口而不是直接使用具体类? 接口用于定义 API.它定义了类必须得遵循的规则.同时,它提供了一种抽象,因为客户端只使用接口,这样可以有多重实现,如 List 接口,你可以使 ...
- 基于IWICImage的截图代码
截图方式和以前一样, 用GetDC, 保存为JPG的方式改用IWICImage接口, 在我机器上 1920*1080 大概花费70毫秒左右, 比用TJPEGImage快了一倍多(TJPEGImage需 ...
- java虚拟机概述
java 虚拟机是什么? java虚拟机是一个将字节码指令映射为对应物理操作系统指令的程序. java程序的运行需要事先安装 jdk,而在jdk内部的jre中其核心就是 jvm ...
- JAVA基础5——与String相关的系列(2)
差异点比较 String使用+直接拼接 这种情况需要分两种情况来讨论: 1. 都是确定的字符串常量之间进行的+号拼接的时候,由于在编译器就可以确定其具体值了,所以编译器在编译期的时候就会把这些常量拼接 ...
- A:点排序-poj
A:点排序 总时间限制: 1000ms 内存限制: 65536kB 描述 给定一个点的坐标(x, y),在输入的n个点中,依次计算这些点到指定点的距离,并按照距离进行从小到大排序,并且输出点的坐标 ...
- <meta http-equiv="X-UA-Compatible" content="IE=edge">的作用
X-UA-Compatible是针对ie8新加的一个设置,对于ie8之外的浏览器是不识别的. X-UA-Compatible 是针对 IE8 版本的一个特殊文件头标记,用于为 IE8 指定不同的页面渲 ...
- Linux 链接详解----动态链接库
静态库的缺点: 库函数被包含在每一个运行的进程中,会造成主存的浪费. 目标文件的size过大 每次更新一个模块都需要重新编译,更新困难,使用不方便. 动态库: 是一个目标文件,包含代码和数据,它可以在 ...
- Ceph luminous 安装配置
Ceph luminous 安装配置 #环境centos7 , Ceph V12 openstack pike 与 ceph 集成 http://www.cnblogs.com/elvi/p/7897 ...
- OpenCASCADE 参数曲线曲面面积
OpenCASCADE 参数曲线曲面面积 eryar@163.com Abstract. 本文介绍了参数曲面的第一基本公式,并应用曲面的第一基本公式,结合OpenCASCADE中计算多重积分的类,对任 ...
- weakSelf 和 strongSelf
最近在看SDWebImage源码,碰到一些比较绕的问题,理解了很久,然后在网上查了些的资料,才算是有了一些理解.在此记录一下. 源码如下: block会copy要在block中使用的实变量,而copy ...