Kosaraju算法详解
• Kosaraju算法是干什么的?
Kosaraju算法可以计算出一个有向图的强连通分量
• 什么是强连通分量?
在一个有向图中如果两个结点(结点v与结点w)在同一个环中(等价于v可通过有向路径到达w,w也可以到达v)它们两
个就是强连通的,所有互为强连通的点组成了一个集合,在一幅有向图中这种集合的数量就是这幅图的强连通分量的数量
• 怎么算??
第一步:计算出有向图 (G) 的反向图 (G反) 的逆后序排列(代码中有介绍)
第二步:在有向图 (G) 中进行标准的深度优先搜索,按照刚才计算出的逆后序排列顺序而非标准顺序,每次搜索访问的所有点即在同一强连通分量中
class Kosaraju {
private Digraph G;
private Digraph reverseG; //反向图
private Stack<Integer> reversePost; //逆后续排列保存在这
private boolean[] marked;
private int[] id; //第v个点在几个强连通分量中
private int count; //强连通分量的数量
public Kosaraju(Digraph G) {
int temp;
this.G = G;
reverseG = G.reverse();
marked = new boolean[G.V()];
id = new int[G.V()];
reversePost = new Stack<Integer>();
makeReverPost(); //算出逆后续排列
for (int i = 0; i < marked.length; i++) { //重置标记
marked[i] = false;
}
for (int i = 0; i < G.V(); i++) { //算出强连通分量
temp = reversePost.pop();
if (!marked[temp]) {
count++;
dfs(temp);
}
}
}
/*
* 下面两个函数是为了算出 逆后序排列
*/
private void makeReverPost() {
for (int i = 0; i < G.V(); i++) { //V()返回的是图G的节点数
if (!marked[i])
redfs(i);
}
}
private void redfs(int v) {
marked[v] = true;
for (Integer w: reverseG.adj(v)) { //adj(v)返回的是v指向的结点的集合
if (!marked[w])
redfs(w);
}
reversePost.push(v); //在这里把v加入栈,完了到时候再弹出来,弹出来的就是逆后续排列
}
/*
* 标准的深度优先搜索
*/
private void dfs(int v) {
marked[v] = true;
id[v] = count;
for (Integer w: G.adj(v)) {
if (!marked[w])
dfs(w);
}
}
public int count() { return count;}
}
• 为什么这样就可以算出强连通分量的数量?(稍微有些费解)
比如有这样一个图,它有五个强连通分量
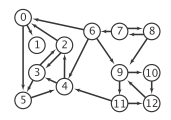
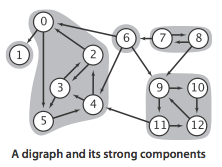
我们需要证明在26行的dfs(temp)中找到的①全是点temp的强连通点,②且是它全部的强连通点
证明时不要忘了定义:v可通过有向路径到达w,w也可以到达v,则它俩强连通
先证明②:
用反证法,就假如对一个点(点w)深度优先搜索时有一个它的强连通点(点v)没找到。
如果没找到,那就说明 点v 已经在找其他点时标记过了,
但 点v 如果已经被标记过了,因为有一条 v -> w 的有向路径,那 点w 肯定也被找过了,
那就不会对 点w 深度优先搜索了。
假设不成立 (*^ω^*)
再证明①:
对一个点(点w)深度优先搜索时找到了一个点(点v),说明有一条 w -> v 的有向路径,再证明有一条 v -> w 的路径就行了,
证明有一条 v -> w 的路径,就相当于证明图G的反向图(G反)有一条 w -> v 的有向路径,
因为 点w 和 点v 满足那个 逆后序排列,而逆后序排列是在redfs(node)结束时将node加入栈,再从栈中弹出,
那说明反向图的深度优先搜索中redfs(v)肯定在redfs(w)前就结束了,
那就是两种情况:
■ redfs(v)已经完了redfs(w)才开始
■ redfs(v)是在 redfs(w)开始之后结束之前 结束的,也就是redfs(v)是在redfs(w)内部结束的
第一种情况不可能,因为 G反 有一条 v -> w 的路径(因为G有一条 w -> v 的路径),
满足第二中情况即在 G反 中有一条 w -> v 的路径。
终于证完了。。。。。。
完整代码:
package practice; import java.util.ArrayList;
import java.util.Stack; public class TestMain {
public static void main(String[] args) {
Digraph a = new Digraph(13);
a.addEdge(0, 1);a.addEdge(0, 5);a.addEdge(2, 3);a.addEdge(2, 0);a.addEdge(3, 2);
a.addEdge(3, 5);a.addEdge(4, 3);a.addEdge(4, 2);a.addEdge(5, 4);a.addEdge(6, 0);
a.addEdge(6, 4);a.addEdge(6, 9);a.addEdge(7, 6);a.addEdge(7, 8);a.addEdge(8, 7);
a.addEdge(8, 9);a.addEdge(9, 10);a.addEdge(9, 11);a.addEdge(10, 12);a.addEdge(11, 4);
a.addEdge(11, 12);a.addEdge(12, 9); Kosaraju b = new Kosaraju(a);
System.out.println(b.count());
}
} class Kosaraju {
private Digraph G;
private Digraph reverseG; //反向图
private Stack<Integer> reversePost; //逆后续排列保存在这
private boolean[] marked;
private int[] id; //第v个点在几个强连通分量中
private int count; //强连通分量的数量
public Kosaraju(Digraph G) {
int temp;
this.G = G;
reverseG = G.reverse();
marked = new boolean[G.V()];
id = new int[G.V()];
reversePost = new Stack<Integer>(); makeReverPost(); //算出逆后续排列 for (int i = 0; i < marked.length; i++) { //重置标记
marked[i] = false;
} for (int i = 0; i < G.V(); i++) { //算出强连通分量
temp = reversePost.pop();
if (!marked[temp]) {
count++;
dfs(temp);
}
}
}
/*
* 下面两个函数是为了算出 逆后序排列
*/
private void makeReverPost() {
for (int i = 0; i < G.V(); i++) { //V()返回的是图G的节点数
if (!marked[i])
redfs(i);
}
} private void redfs(int v) {
marked[v] = true;
for (Integer w: reverseG.adj(v)) { //adj(v)返回的是v指向的结点的集合
if (!marked[w])
redfs(w);
}
reversePost.push(v); //在这里把v加入栈,完了到时候再弹出来,弹出来的就是逆后续排列
}
/*
* 标准的深度优先搜索
*/
private void dfs(int v) {
marked[v] = true;
id[v] = count;
for (Integer w: G.adj(v)) {
if (!marked[w])
dfs(w);
}
} public int count() { return count;}
}
/*
* 图
*/
class Digraph {
private ArrayList<Integer>[] node;
private int v;
public Digraph(int v) {
node = (ArrayList<Integer>[]) new ArrayList[v];
for (int i = 0; i < v; i++)
node[i] = new ArrayList<Integer>();
this.v = v;
} public void addEdge(int v, int w) { node[v].add(w);} public Iterable<Integer> adj(int v) { return node[v];} public Digraph reverse() {
Digraph result = new Digraph(v);
for (int i = 0; i < v; i++) {
for (Integer w : adj(i))
result.addEdge(w, i);
}
return result;
} public int V() { return v;} }
Kosaraju算法详解的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- ArrayList——源码探究
摘要 ArrayList 是Java中常用的一个集合类,其继承自AbstractList并实现了List 构造器 ArrayList 提供了三个构造器,分别是 含参构造器-1 // 含参构造器-1 / ...
- [学习笔记] Splay Tree 从入门到放弃
前几天由于出行计划没有更博QwQ (其实是因为调试死活调不出来了TAT我好菜啊) 伸展树 伸展树(英语:Splay Tree)是一种二叉查找树,它能在O(log n)内完成插入.查找和删除操作.它是由 ...
- 花了一年时间开发的弯管机YBC编程软件
弯管技术广泛应用于锅炉及压力容器,空调制造,汽车,航空航天等多种行业.管型的形状复杂多变弯管工艺人员通常依据图纸输入关键点的坐标(XYZ坐标),然后生成可以由弯管机设备直接直接完成的加工指令YBC数据 ...
- S2-032代码执行
Struts 2是Struts的下一代产品,是在 struts 1和WebWork的技术基础上进行了合并的全新的Struts 2框架.其全新的Struts 2的体系结构与Struts 1的体系结构差别 ...
- hdu--1072--Nightmare(bfs回溯)
Nightmare Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total S ...
- [入门向选讲] 插头DP:从零概念到入门 (例题:HDU1693 COGS1283 BZOJ2310 BZOJ2331)
转载请注明原文地址:http://www.cnblogs.com/LadyLex/p/7326874.html 最近搞了一下插头DP的基础知识……这真的是一种很锻炼人的题型…… 每一道题的状态都不一样 ...
- .Net大局观(2).NET Core 2.0 特性介绍和使用指南
.NET Core 2.0发布日期:2017年8月14日 前言 这一篇会比较长,系统地介绍了.NET Core 2.0及生态,现状及未来计划,可以作为一门技术的概述来读,也可以作为学习路径.提纲来用. ...
- ThinkSNS积分商城系统功能详解!
积分商城含PC端.Android APP.iOS APP:在ThinkSNS PC端首页导航栏点击"拓展功能",然后选择"积分商城"进行体验:APP端则是在&q ...
- 社群系统ThinkSNS V4.5.29 APP更新发布,新增用户认证及系统消息
社群系统ThinkSNS V4版本移动端APP将于7月29日更新发布,本次更新修复部分bug,最主要是增加了移动端APP的用户认证功能,以及添加了系统消息,为V4.5.29版本发布.这两个功能PC端的 ...
- Apriori关联分析算法概述
概念 关联分析:从大规模数据集中寻找物品间的隐含关系.物品间关系又分为两种:频繁项集或关联规则,频繁项集是经常出现一块的物品集合:关联规则则暗示物品间存在很强的联系 关联评判标准:支持度和可信度.支持 ...