Spark源码剖析(一):如何将spark源码导入到IDEA中
由于近期准备深入研究一下Spark的核心源码,所以开了这一系列用来记录自己研究spark源码的过程!
想要读源码,那么第一步肯定导入spark源码啦(笔者使用的是IntelliJ IDEA),在网上找了一圈,尝试了好几种方法都没有成功,最终通过自己摸索出了一种非常简单的方式(只需要两步即可!)
环境要求
- IntelliJ IDEA(Community版本即可)
- maven(当然jdk是不可少的)
具体信息如下:
C:\Users\Administrator>mvn -version
Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)
Maven home: D:\java\apache-maven-3.3.9\bin\..
Java version: 1.8.0_151, vendor: Oracle Corporation
Java home: D:\java\jdk-1.8u151\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 7", version: "6.1", arch: "amd64", family: "dos"
顺便贴一下maven的settings.xml
<?xml version="1.0" encoding="UTF-8"?> <!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
--> <!--
| This is the configuration file for Maven. It can be specified at two levels:
|
| . User Level. This settings.xml file provides configuration for a single user,
| and is normally provided in ${user.home}/.m2/settings.xml.
|
| NOTE: This location can be overridden with the CLI option:
|
| -s /path/to/user/settings.xml
|
| . Global Level. This settings.xml file provides configuration for all Maven
| users on a machine (assuming they're all using the same Maven
| installation). It's normally provided in
| ${maven.conf}/settings.xml.
|
| NOTE: This location can be overridden with the CLI option:
|
| -gs /path/to/global/settings.xml
|
| The sections in this sample file are intended to give you a running start at
| getting the most out of your Maven installation. Where appropriate, the default
| values (values used when the setting is not specified) are provided.
|
|-->
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
<localRepository>D:\Mavenworkspace\m2\repository</localRepository>
-->
<localRepository>D:\java\mavenRepository</localRepository>
<!-- interactiveMode
| This will determine whether maven prompts you when it needs input. If set to false,
| maven will use a sensible default value, perhaps based on some other setting, for
| the parameter in question.
|
| Default: true
<interactiveMode>true</interactiveMode>
--> <!-- offline
| Determines whether maven should attempt to connect to the network when executing a build.
| This will have an effect on artifact downloads, artifact deployment, and others.
|
| Default: false
<offline>false</offline>
--> <!-- pluginGroups
| This is a list of additional group identifiers that will be searched when resolving plugins by their prefix, i.e.
| when invoking a command line like "mvn prefix:goal". Maven will automatically add the group identifiers
| "org.apache.maven.plugins" and "org.codehaus.mojo" if these are not already contained in the list.
|-->
<pluginGroups>
<!-- pluginGroup
| Specifies a further group identifier to use for plugin lookup.
<pluginGroup>com.your.plugins</pluginGroup>
-->
</pluginGroups> <!-- proxies
| This is a list of proxies which can be used on this machine to connect to the network.
| Unless otherwise specified (by system property or command-line switch), the first proxy
| specification in this list marked as active will be used.
|-->
<proxies>
<!-- proxy
| Specification for one proxy, to be used in connecting to the network.
|
<proxy>
<id>optional</id>
<active>true</active>
<protocol>http</protocol>
<username>proxyuser</username>
<password>proxypass</password>
<host>proxy.host.net</host>
<port></port>
<nonProxyHosts>local.net|some.host.com</nonProxyHosts>
</proxy>
-->
</proxies> <!-- servers
| This is a list of authentication profiles, keyed by the server-id used within the system.
| Authentication profiles can be used whenever maven must make a connection to a remote server.
|-->
<servers>
<!-- server
| Specifies the authentication information to use when connecting to a particular server, identified by
| a unique name within the system (referred to by the 'id' attribute below).
|
| NOTE: You should either specify username/password OR privateKey/passphrase, since these pairings are
| used together.
|
<server>
<id>deploymentRepo</id>
<username>repouser</username>
<password>repopwd</password>
</server>
--> <!-- Another sample, using keys to authenticate.
<server>
<id>siteServer</id>
<privateKey>/path/to/private/key</privateKey>
<passphrase>optional; leave empty if not used.</passphrase>
</server>
-->
</servers> <!-- mirrors
| This is a list of mirrors to be used in downloading artifacts from remote repositories.
|
| It works like this: a POM may declare a repository to use in resolving certain artifacts.
| However, this repository may have problems with heavy traffic at times, so people have mirrored
| it to several places.
|
| That repository definition will have a unique id, so we can create a mirror reference for that
| repository, to be used as an alternate download site. The mirror site will be the preferred
| server for that repository.
|-->
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>nexus-osc</id>
<mirrorOf>central</mirrorOf>
<name>Nexus osc</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror> <mirror>
<id>osc_thirdparty</id>
<mirrorOf>thirdparty</mirrorOf>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</mirror>
</mirrors> <!-- profiles
| This is a list of profiles which can be activated in a variety of ways, and which can modify
| the build process. Profiles provided in the settings.xml are intended to provide local machine-
| specific paths and repository locations which allow the build to work in the local environment.
|
| For example, if you have an integration testing plugin - like cactus - that needs to know where
| your Tomcat instance is installed, you can provide a variable here such that the variable is
| dereferenced during the build process to configure the cactus plugin.
|
| As noted above, profiles can be activated in a variety of ways. One way - the activeProfiles
| section of this document (settings.xml) - will be discussed later. Another way essentially
| relies on the detection of a system property, either matching a particular value for the property,
| or merely testing its existence. Profiles can also be activated by JDK version prefix, where a
| value of '1.4' might activate a profile when the build is executed on a JDK version of '1.4.2_07'.
| Finally, the list of active profiles can be specified directly from the command line.
|
| NOTE: For profiles defined in the settings.xml, you are restricted to specifying only artifact
| repositories, plugin repositories, and free-form properties to be used as configuration
| variables for plugins in the POM.
|
|-->
<profiles>
<!-- profile
| Specifies a set of introductions to the build process, to be activated using one or more of the
| mechanisms described above. For inheritance purposes, and to activate profiles via <activatedProfiles/>
| or the command line, profiles have to have an ID that is unique.
|
| An encouraged best practice for profile identification is to use a consistent naming convention
| for profiles, such as 'env-dev', 'env-test', 'env-production', 'user-jdcasey', 'user-brett', etc.
| This will make it more intuitive to understand what the set of introduced profiles is attempting
| to accomplish, particularly when you only have a list of profile id's for debug.
|
| This profile example uses the JDK version to trigger activation, and provides a JDK-specific repo.
<profile>
<id>jdk-1.4</id> <activation>
<jdk>1.4</jdk>
</activation> <repositories>
<repository>
<id>jdk14</id>
<name>Repository for JDK 1.4 builds</name>
<url>http://www.myhost.com/maven/jdk14</url>
<layout>default</layout>
<snapshotPolicy>always</snapshotPolicy>
</repository>
</repositories>
</profile>
-->
<profile>
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties> <repositories> <repository>
<id>nexus</id>
<name>local private nexus</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository> </repositories> <pluginRepositories> <pluginRepository>
<id>nexus</id>
<name>local private nexus</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository> </pluginRepositories>
</profile> <profile>
<id>osc</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation> <repositories> <repository>
<id>osc</id>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</repository> <repository>
<id>osc_thirdparty</id>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</repository> </repositories> <pluginRepositories> <pluginRepository>
<id>osc</id>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</pluginRepository> </pluginRepositories>
</profile> </profile> <!--
| Here is another profile, activated by the system property 'target-env' with a value of 'dev',
| which provides a specific path to the Tomcat instance. To use this, your plugin configuration
| might hypothetically look like:
|
| ...
| <plugin>
| <groupId>org.myco.myplugins</groupId>
| <artifactId>myplugin</artifactId>
|
| <configuration>
| <tomcatLocation>${tomcatPath}</tomcatLocation>
| </configuration>
| </plugin>
| ...
|
| NOTE: If you just wanted to inject this configuration whenever someone set 'target-env' to
| anything, you could just leave off the <value/> inside the activation-property.
|
<profile>
<id>env-dev</id> <activation>
<property>
<name>target-env</name>
<value>dev</value>
</property>
</activation> <properties>
<tomcatPath>/path/to/tomcat/instance</tomcatPath>
</properties>
</profile>
-->
</profiles> <!-- activeProfiles
| List of profiles that are active for all builds.
|
<activeProfiles>
<activeProfile>alwaysActiveProfile</activeProfile>
<activeProfile>anotherAlwaysActiveProfile</activeProfile>
</activeProfiles>
-->
</settings>
settings.xml
好了,一旦环境准备就绪,那就速战速决吧!
第一步:从github上下载源代码
先选择你想要阅读的spark版本,笔者这里选择的是spark1.3版本
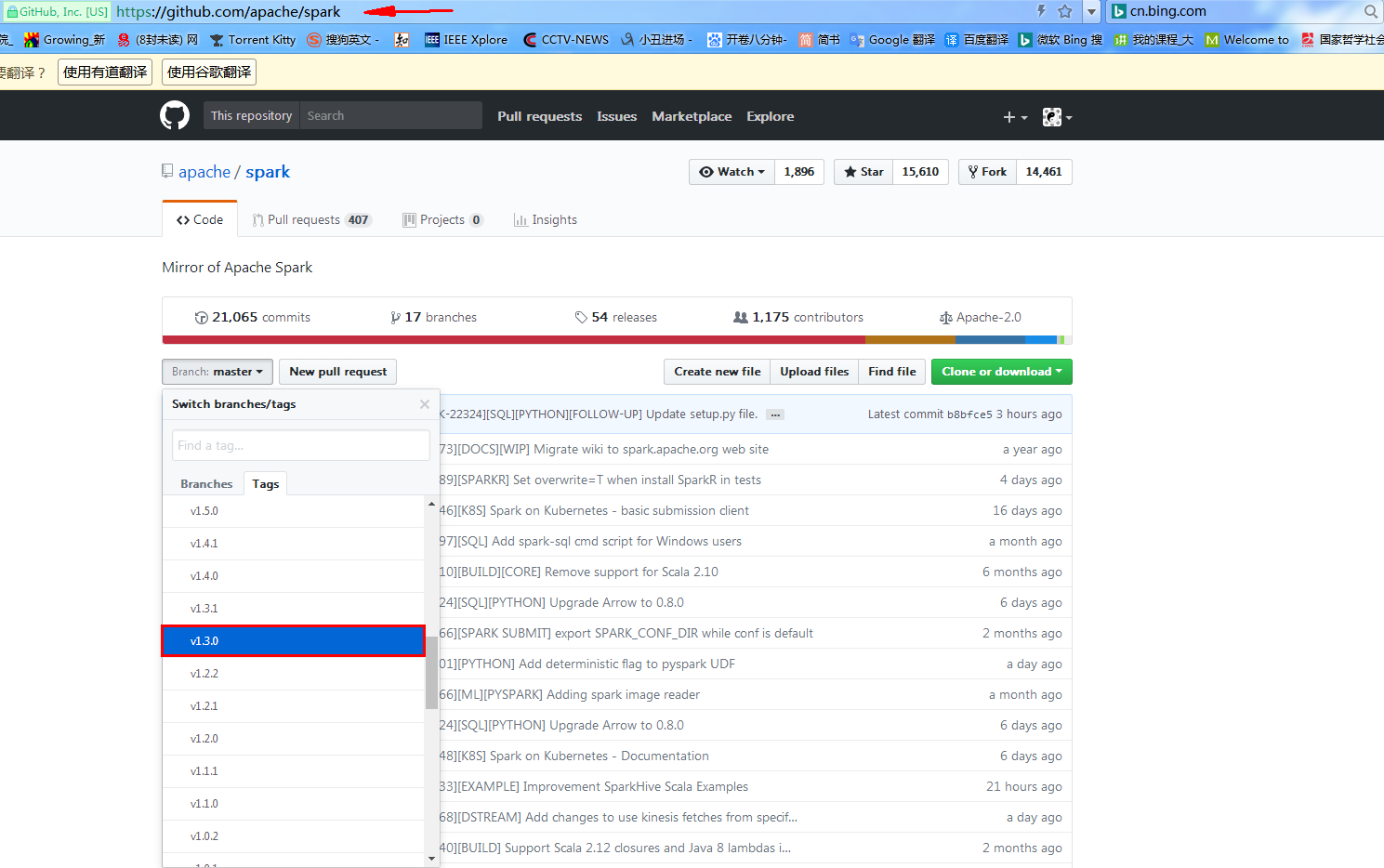
接着直接下载zip包到本地解压(当然也可以使用git拉下来啦)
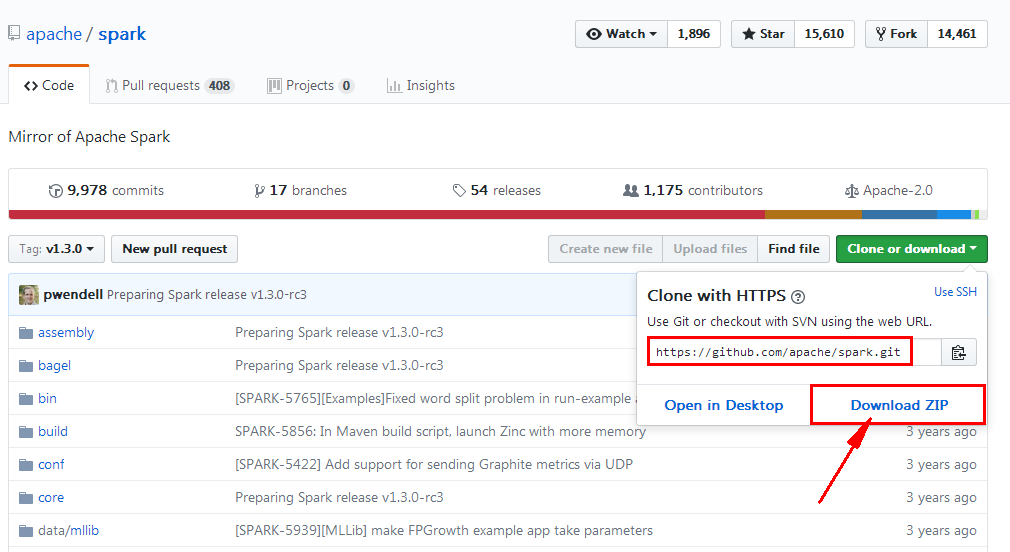
第二步:使用IDEA导入spark源码
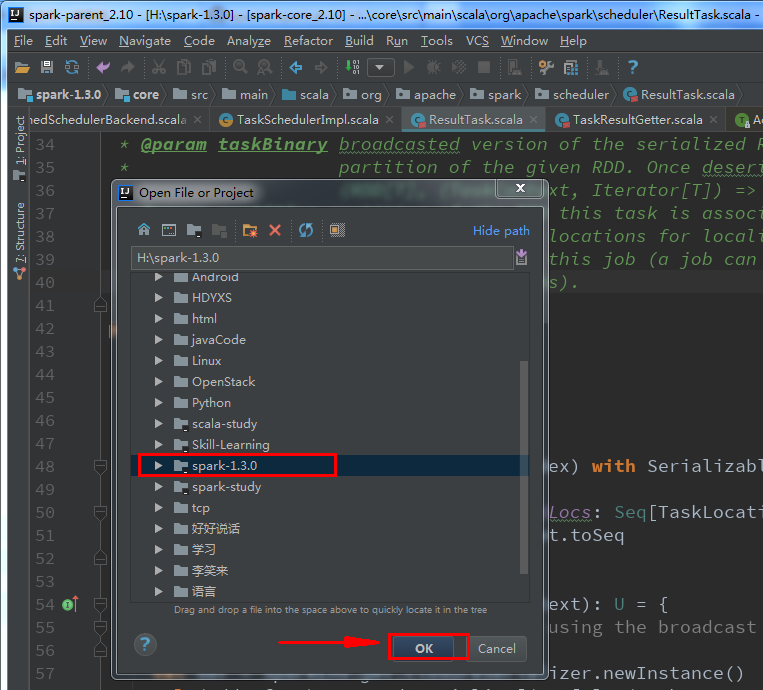
打开你的IntelliJ IDEA ,File -> Open 选中你源码解压后的文件夹即可! (不需要使用Import)
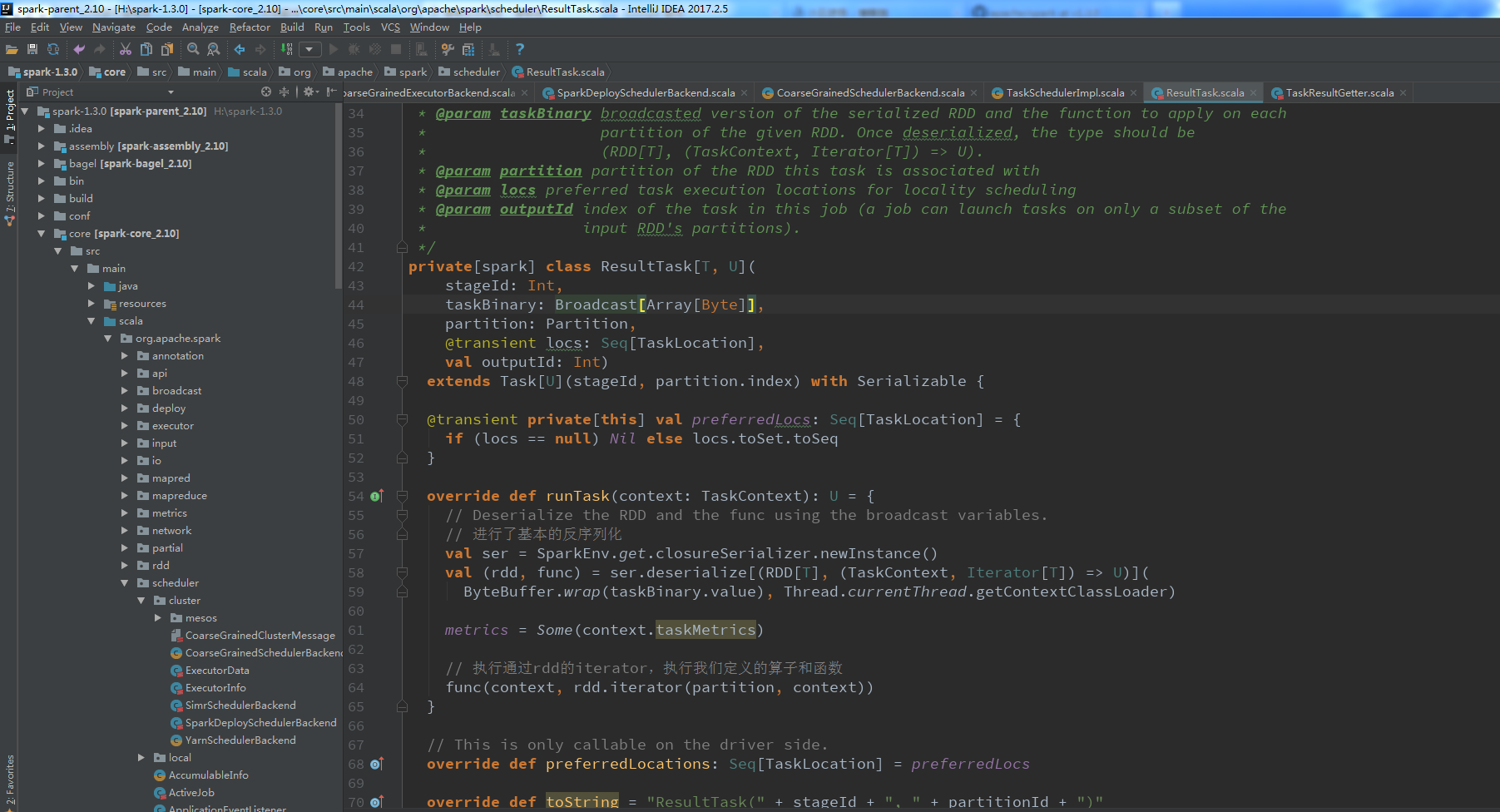
到这里基本已经大功告成!接下来只需要等待maven解决各种依赖即可(大概需要半个小时,大家耐心一点)
成功后的界面如下(提示:可以使用ctrl + N 搜索你想要阅读的类文件):
Spark源码剖析(一):如何将spark源码导入到IDEA中的更多相关文章
- Spring源码剖析9:Spring事务源码剖析
转自:http://www.linkedkeeper.com/detail/blog.action?bid=1045 声明式事务使用 Spring事务是我们日常工作中经常使用的一项技术,Spring提 ...
- Apache Spark源码剖析
Apache Spark源码剖析(全面系统介绍Spark源码,提供分析源码的实用技巧和合理的阅读顺序,充分了解Spark的设计思想和运行机理) 许鹏 著 ISBN 978-7-121-25420- ...
- Django Rest Framework源码剖析(五)-----解析器
一.简介 解析器顾名思义就是对请求体进行解析.为什么要有解析器?原因很简单,当后台和前端进行交互的时候数据类型不一定都是表单数据或者json,当然也有其他类型的数据格式,比如xml,所以需要解析这类数 ...
- Java ArrayList源码剖析
转自: Java ArrayList源码剖析 总体介绍 ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现.除该类未实现同步外 ...
- Java HashSet和HashMap源码剖析
转自: Java HashSet和HashMap源码剖析 总体介绍 之所以把HashSet和HashMap放在一起讲解,是因为二者在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说Ha ...
- drf源码剖析系列(系列目录)
drf源码剖析系列(系列目录) 01 drf源码剖析之restful规范 02 drf源码剖析之快速了解drf 03 drf源码剖析之视图 04 drf源码剖析之版本 05 drf源码剖析之认证 06 ...
- 《Apache Spark源码剖析》
Spark Contributor,Databricks工程师连城,华为大数据平台开发部部长陈亮,网易杭州研究院副院长汪源,TalkingData首席数据科学家张夏天联袂力荐1.本书全面.系统地介绍了 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
随机推荐
- ASP.NET异常处理机制
try{ //获取并使用资源,可能出现异常}catch(DivideByZeroException de){}catch(ArithmeticException ae){}catch(Exceptio ...
- 使用Angular Router导航基础
名称 简介 Routes 路由配置,保存着那个URL对应着哪个组件,以及在哪个RouterOulet中展示组件. RouterOutlet 在HTML中标记路由内容呈现位置的占位符指令. Router ...
- 将后面的m个数移到前面
#include<iostream> #include<algorithm> #include<stdio.h> #include<numeric> u ...
- Ipython自动导入Numpy,pandas等模块
一.引言 最近在学习numpy,书上要求安装一个Ipythpn,可以自动导入Numpy,pandas等数据分析的模块,可是当我安装后,并不能自动导入numpy模块,还需要自己import.我就去查了一 ...
- WCF、WebAPI、WCFREST、WebService之间的区别和选择
转载翻译,原文:http://www.dotnet-tricks.com/Tutorial/webapi/JI2X050413-Difference-between-WCF-and-Web-API-a ...
- Android Weekly Notes Issue #286
December 3rd, 2017 Android Weekly Issue #286 本期文章包含如何通过踩坑来学习Kotlin,以及利用Kotlin的data class做MVVM状态保存,还包 ...
- FastDFS教程IV-文件服务器集群搭建
1.简介 本文主要介绍FastDFS文件服务器的集群搭建,在阅读本文之前,您需具备FastDFS文件服务器单节点安装,扩容,迁移等方面的知识.同时,您还需了解Keepalived,nginx方 ...
- JS 中对变量类型的五种判断方法
5种基本数据类型:undefined.null.boolean.unmber.string 复杂数据类型:object. object:array.function.date等 方法一:使用typeo ...
- 响应式框架Bootstrap栅格系统
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8&qu ...
- json篇
QQ:1187362408 欢迎技术交流和学习 json篇(json): TODO: 1,json:json是什么( JSON(JavaScript Object Notation) 是一种轻量级的数 ...