nova创建虚拟机源码分析系列之三 PasteDeploy
上一篇博文介绍WSGI在nova创建虚拟机过程的作用是解析URL,是以一个最简单的例子去给读者有一个印象。在openstack中URL复杂程度也大大超过上一个例子。所以openstack使用了PasteDeploy模块去解析复杂的URL。
首先看“笨办法”是如何处理不同的URL。
在WSGI简单的模型中,如果有多个URL,可以判断请求方和请求路径的然后分别处理不同的URL。
处理函数 app.py
def application(environ, start_response):
method = environ['REQUEST_METHOD'] #从环境变量中提取请求方法
path = environ['PATH_INFO'] #从环境变量中提取请求路径
if method=='GET' and path=='/': #通过判断的方法来确定处理的函数
return <h1>path = /</h1> #该函数对应的URL是 "/"
if method=='POST' and path='/signin':
return <h1>path = /signin </h1> #该函数对应URL的是 "/sigin"
服务器函数 server.py
# 从wsgiref模块导入:
from wsgiref.simple_server import make_server
# 导入我们自己编写的application函数:
from hello import application # 创建一个服务器,IP地址为空,端口是8000,处理函数是application:
httpd = make_server('', , application)
print "Serving HTTP on port 8000..."
# 开始监听HTTP请求:
httpd.serve_forever()
这种方法是简单,直接的,但也是可重复性差,不可维护的。一个restful中有可能50个以上的URL路径,如果这么写下去,那维护的人要抓狂。
所以要以一种简单清晰,可维护性好的方式去解析URL,这种方式便是使用PasteDeploy模型。
PasteDeploy的工作模式是使用一个配置文件configure.ini去解析URL。借鉴一个例子来讲解,原文 http://blog.csdn.net/li_101357/article/details/52755367
在家里水系统的模型大概如下图,以及对应的模拟路径:
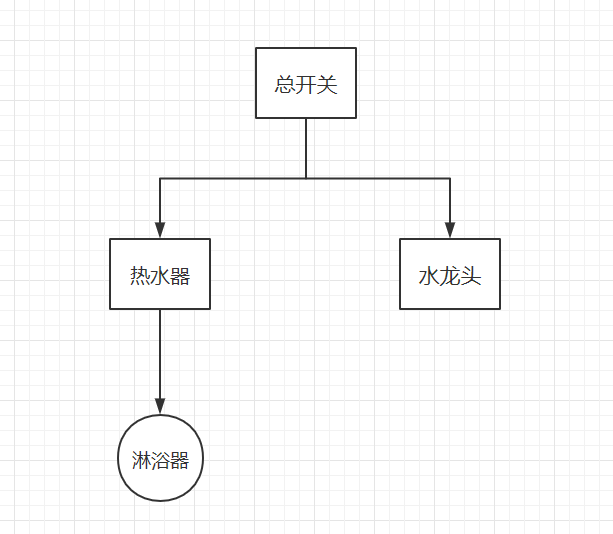
总开关 /main 淋浴器 /main/boiler/shower 水龙头 /main/tap
PasteDeploy模型中有4中部件,分别是:




对应到上例:
- app 水龙头 淋浴器
- filter 热水器
- pipeline 热水器 + 淋浴器
- composite 总开关
确定了对应的URL之后,使用PasteDeploy组件来构造解析文件configure.ini。
[composite:main]
use = egg:Paste#urlmap
/main/tap = tap
/main/boil/shower = pip_to_shower [app:tap]
paste.app_factory = tap:app_factory
in_arg = water [pipeline:pip_to_shower]
pipeline = boiler shower [filter:boiler]
paste.filter_app_factory = boiler:filter_app_factory
in_arg = water [app:shower]
paste.app_factory = shower:app_factory
in_arg = hot_water
[composite:main]
use = egg:Paste#urlmap
/main/tap = tap
/main/boil/shower = pip_to_shower
Paste#urlmap 表示,默认使用Paste.urlmap。
use = egg:Paste#urlmap 意味着直接使用来自于Paste包的urlmap的composite应用。 urlmap是特别常
见的composite应用——它使用路径前缀来映射将你的请求与其他应用对应起来。
基本含义就是说,这是Paste已经提供好的一个composite,如果你想自定义就需要另外写一个composite_factory了。
[app:tap]
paste.app_factory = tap:app_factory
in_arg = water
表示路径"/tap"的处理方法paste.app_factory存在于tap.py文件的的app_factory中,这是一个方法。
[pipeline:pip_to_shower]
pipeline = boiler shower
pipeline 主要起到组合的作用,将filter(过滤器)和app(应用)组合起来,形成一条管道。
[filter:boiler]
paste.filter_app_factory = boiler:filter_app_factory
in_arg = water
filter类似app,只不过换成了paste.filter_app_factory,filter首先执行过滤功能,然后执行app。
配置文件中将路径的处理都配置好:
/main/tap 路径对应的处理函数 tap ,tap是文件tap.py的app_factory方法。
/main/boil/shower 路径对应的处理函数是管道 pip_to_shower 。管道由过滤器 boiler和应用shower组成。首次经过boiler的过滤,然后调用shower函数处理。
下面完成tap、shower和filter文件。
tap.py
class Tap(object):
def __init__(self, in_arg):
self.in_arg = in_arg def __call__(self, environ, start_response):
print 'Tap'
start_response('200 ok', [('Content-Type', 'text/html')])
return "<h1> Tap! </h1>" def app_factory(global_config, in_arg):
return Tap(in_arg)
app_factory是tap对应的处理方法,返回时调用了Tap方法,Tap对应的是类Tap的__call__方法,在该方法中打印一个"Tap",然后发送报文头,最后返回一个字符串。
shower.py
class Shower(object):
def __init__(self, in_arg):
self.in_arg = in_arg def __call__(self, environ, start_response):
print 'Shower'
start_response('200 ok', [('Content Type', 'text/html')])
return "<h1> Shower! </h1>" def app_factory(global_config, in_arg):
return Shower(in_arg)
shower的分析同上
boiler.py
class Boiler(object):
def __init__(self, app, in_arg):
self.app = app
self.in_arg = in_arg def __call__(self, environ, start_response):
print 'Boiler'
return self.app(environ, start_response)
def filter_app_factory(app, global_config, in_arg):
return Boiler(app, in_arg)
filter_app_factory是boiler对应的处理方法,其中传入的参数中有一个app,返回时调用了Boiler,并传入参数app。
Boiler是类Boiler的__call__方法,首先打印了字符串"Boiler",然后返回时调用了函数app。这个app具体到本例就是调用了shower
所有的文件都准备齐全了,接下来开启WSGI服务,让程序跑起来。
server.py
from wsgiref.simple_server import make_server
from paste import httpserver
from paste.deploy import loadapp
import os if __name__ == '__main__':
configfile = 'configure.ini' #定义配置文件
appname = 'main' #composite的名称
wsgi_app = loadapp('config:%s' % os.path.abspath(configfile), appname) #载入配置文件
print "start the server listening on 8080"
server = make_server('0.0.0.0', 8080, wsgi_app)
server.serve_forever()
运行server程序。

在浏览器中请求URL http://[ip ]:8080/main/tap

在浏览器中请求URL http://[ip ]:8080/main/boiler/shower

小结:
使用PasteDeploy模块将URL解析从判断的方式转变到文件配置的方式。
使用configuer.ini文件配置了URL /main/tap 对应处理函数 app_factory和/main/boiler/shower 对应处理函数 shower.py中的app_factory。
本篇主要讲的是使用PasteDeploy模块去配置WSGI解析URL。在openstack源码中就是基于这样的模型去完成restful 的解析,处理等。当一条restful的请求如:http://192.168.252.177:5000/v2.0/token
到达服务器时,服务器处理的流程就是如上,通过配置文件查找URL处理函数,然后调用处理函数返回处理结果。
通过对简单模型的掌握,便于理解后续的复杂的内容。
本篇博文参考:http://blog.csdn.net/li_101357/article/details/52755367
nova创建虚拟机源码分析系列之三 PasteDeploy的更多相关文章
- nova创建虚拟机源码分析系列之五 nova源码分发实现
前面讲了很多nova restful的功能,无非是为本篇博文分析做铺垫.本节说明nova创建虚拟机的请求发送到openstack之后,nova是如何处理该条URL的请求,分析到处理的类. nova对于 ...
- nova创建虚拟机源码分析系列之一 restful api
开始学习openstack源码,源码文件多,分支不少.按照学习的方法走通一条线是最好的,而网上推荐的最多的就是nova创建虚机的过程.从这一条线入手,能够贯穿openstack核心服务.写博文仅做学习 ...
- nova创建虚拟机源码分析系列之七 传入参数转换成内部id
上一篇博文将nova创建虚机的流程推进到了/compute/api.py中的create()函数,接下来就继续分析. 在分析之前简单介绍nova组件源码的架构.以conductor组件为例: 每个组件 ...
- nova创建虚拟机源码分析系列之六 api入口create方法
openstack 版本:Newton 注:博文图片采用了很多大牛博客图片,仅作为总结学习,非商用.该图全面的说明了nova创建虚机的过程,从逻辑的角度清晰的描述了前端请求创建虚拟机之后发生的一系列反 ...
- nova创建虚拟机源码分析系列之八 compute创建虚机
/conductor/api.py _build_instance() /conductor/rpcapi.py _build_instance() 1 构造一些数据类型2 修改一些api版本信息 ...
- nova创建虚拟机源码分析系列之四 nova代码模拟
在前面的三篇博文中,介绍了restful和SWGI的实现.结合restful和WSGI配置就能够简单的实现nova服务模型的最简单的操作. 如下的内容是借鉴网上博文,因为写的很巧妙,将nova管理虚拟 ...
- nova创建虚拟机源码系列分析之二 wsgi模型
openstack nova启动时首先通过命令行或者dashborad填写创建信息,然后通过restful api的方式调用openstack服务去创建虚拟机.数据信息从客户端到达openstack服 ...
- Dubbo 源码分析系列之三 —— 架构原理
1 核心功能 首先要了解Dubbo提供的三大核心功能: Remoting:远程通讯 提供对多种NIO框架抽象封装,包括"同步转异步"和"请求-响应"模式的信息交 ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
随机推荐
- HTML Entity 字符实体
目录 1. HTML Entity 2. 字符与Entity Name的互相转换 3. 字符与Entity Number的互相转换 1. HTML Entity 1.1 介绍 在编写HTML页面时,需 ...
- JavaEE中的MVC(二)Xml配置实现IOC控制反转
毕竟我的经验有限,这篇文章要是有什么谬误,欢迎留言并指出,我们可以一起讨论讨论. 我要讲的是IOC控制反转,然后我要拿它做一件什么事?两个字:"解耦",形象点就是:表明当前类中需要 ...
- sqoop的导入导出
1.知道某列的值的增量导入(mysql------>文件) bin/sqoop import \--connect jdbc:mysql://bigdatcdh01:3306/test \--u ...
- SQL知识目录
SQL理论知识 -------理论知识总结 -------理论知识总结 -------理论知识总结 -------理论知识总结 -------理论知识总结 -------理论知识总结 -------理 ...
- 晓莲说-何不原创:java 实现二维数组冒泡排序
新手从业路-为自己回顾知识的同时,也希望和大家分享经验: 话不多说,上代码 public class 冒泡排序 { /** * @param admin * @2017.12.4 ...
- ios判断手机号是否可用
+ (BOOL)valiMobile:(NSString *)mobileNum { if (mobileNum.length != 11) { return NO; } /** * 手机号码: // ...
- 【转】three.js详解之入门篇
原文链接:https://www.cnblogs.com/shawn-xie/archive/2012/08/16/2642553.html 开场白 webGL可以让我们在canvas上实现3D效 ...
- Smarty基础用法
一.Smarty基础用法: 1.基础用法如下 include './smarty/Smarty.class.php';//引入smarty类 $smarty = new Smarty();//实例化s ...
- 【LintCode·容易】用栈模拟汉诺塔问题
用栈模拟汉诺塔问题 描述 在经典的汉诺塔问题中,有 3 个塔和 N 个可用来堆砌成塔的不同大小的盘子.要求盘子必须按照从小到大的顺序从上往下堆 (如:任意一个盘子,其必须堆在比它大的盘子上面).同时, ...
- windows平台下基于QT和OpenCV搭建图像处理平台
在之前的博客中,已经分别比较详细地阐述了"windows平台下基于VS和OpenCV"以及"Linux平台下基于QT和OpenCV"搭建图像处理框架,并 ...