word2-寻找社交新浪微博中的目标用户
项目简述:
为了进行更加精准的营销, 利用数据挖掘相关算法, 利用开放API或自行编写爬虫获得新浪微博, 知乎等社交网络(可能需要破解验证码)中用户所发布的数据, 利用数据挖掘的相关算法进行分析, 从大规模的用户群体中, 分别找出其中具有海淘或母婴购物意向的用户
使用语言:
java
工具:
eclipse
项目过程论述:
1.收集新浪微博用户的数据
2.对这些用户数据进行分析,判断其是否具有母婴的购物意向。
3.对这些具有母婴购物意向的用户进一步分类,分成衣食住行四类。
4.给分好类之后的用户进行推荐相应的母婴商品。
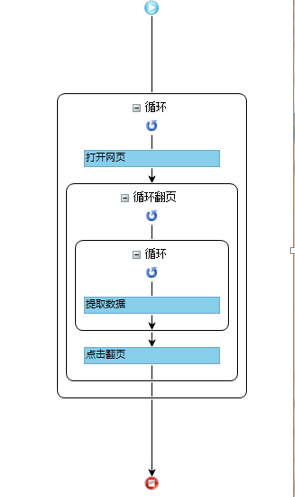
工作流程图如图所示:

----------------------------------------------------------------------------------------------
过程1-----收集新浪微博用户的数据
目的:收集每个用户至少300条微博,不足收集全部,太少则放弃。
收集工具:八爪鱼收集器
收集方法:按照关键词收集,利用新浪微博强大的搜索引擎。
收集规则:
收集结果(存放到mysql):
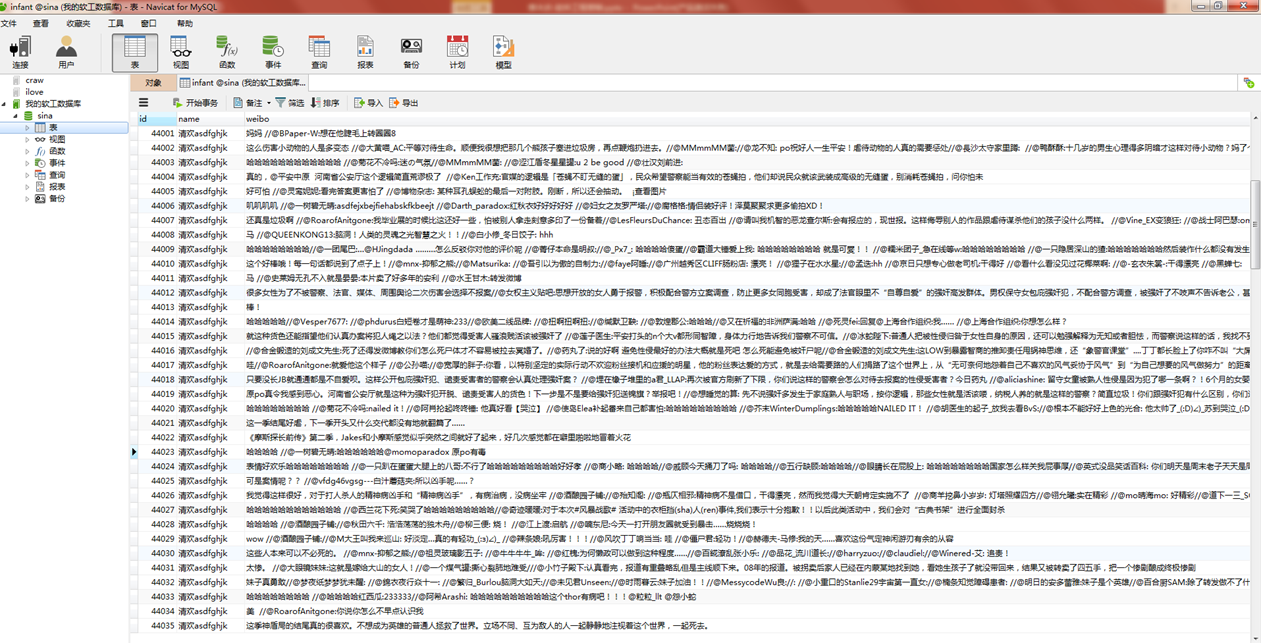
-------------------------------------------------------------------------------------------------------------------------------------------------------------
过程2-----对收集到的新浪微博用户进行分析,判断其是否具有母婴的购物意向
目的:对一个用户分析,判断是/否具有母婴购物意向
方法:使用向量空间模型的余弦相似度,即两个向量之间的夹角越小,则余弦值越大,这两个向量就越相似
实现过程:
前提:收集数据的时候收集两部分数据,一部分人工判断已知具有母婴购物意向,另一部分是未知购物意向的用户。
1.将每个用户的向量都抽象成N维向量。
方法:参考石延君的博客参考石延君的博客http://shiyanjun.cn/archives/548.html
具体如下:
1)先找出能代表这个用户微博的关键词,将这个用户的微博都存储在一个txt文件中,大致过程如下

2)找出特征向量后,给特征向量的每一维都赋予权重,可以得到初步的N维具有权重的向量。

3)对N维向量进行归一化,直接利用libsvm的scale函数即可(可以参考libsvm的使用方法)。
2.计算未知用户向量与已知购物意向用户向量之间的余弦相似度,如果超过0.5,则认为其是相似的,则有理由认为这些未知用户是具有母婴购物意向的。
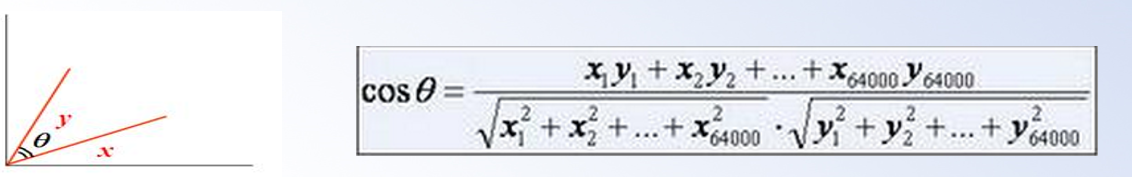
---------------------------------------------------------------------------------------------------------------------------------------------------
过程3--------对分析出来具有母婴购物意向的用户进一步分类,分成衣食住行四类
理论基础:使用libsvm来分类

训练集是预先收集好的,分成衣食住行四类的新浪微博用户,带预测集是过程1和2分析出来的具有母婴购物意向的用户。
-----------------------------------------------------------------------------------------------------------------------------------------
过程4------推荐商品

word2-寻找社交新浪微博中的目标用户的更多相关文章
- Redis 在新浪微博中的应用
Redis 在新浪微博中的应用 Redis简介 1. 支持5种数据结构 支持strings, hashes, lists, sets, sorted setsstring是很好的存储方式,用来做计数存 ...
- 产品研发过程中UCD目标的制定与实现
摘 要:以用户为中心的设计(UCD, User-Centered Design)是保障产品具有较好用户体验(User Experience)的基本活动,其中可用性目标是有效衡量 UCD 活动最终效果的 ...
- 菜鸟-手把手教你把Acegi应用到实际项目中(11)-切换用户
在某些应用场合中,我们可能需要用到切换用户的功能,从而以另一用户的身份进行相关操作.这一点类似于在Linux系统中,用su命令切换到另一用户进行相关操作. 既然实际应用中有这种场合,那么我们 ...
- 测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇
测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇 在前面我分享了几个新浪微博的自动化脚本的实现,下面我们继续实现新的需求,功能需求如下: 1,登陆微博 2,抓取评论页内容3,用正则表 ...
- dgraph解决社交关系中的正反向查找
dgraph解决社交关系中的正反向查找 本篇介绍的是, 社交关系中的关注者与被关注者在dgraph中如何实现查找. 对dgraph的基本操作不太清楚的可以看看我之前写的博客 dgraph实现基本操作 ...
- 在 Linux 中使用超级用户权限
在你想要使用超级权限临时运行一条命令时,sudo 命令非常方便,但是当它不能如你期望的工作时,你也会遇到一些麻烦.比如说你想在某些日志文件结尾添加一些重要的信息,你可能会尝试这样做: $ echo & ...
- sql server中的孤立用户
此问题出现在数据库的移值上.移值后,数据库的登陆名和数据库用户名孤立,原数据中,用建立的用户名密码登陆可以访问数据库,但是移值后就不能访问了.而且如果您尝试向该登录帐户授予数据库访问权限,则会因该用户 ...
- linux 不在sudoers文件中、普通用户获得sudo权限
现在要让jack用户获得sudo使用权 切换到超级用户root $su root 查看/etc/sudoers权限,可以看到当前权限为440 $ ls -all /etc/sudoers -r--r- ...
- 目标用户偏好指数Target Group Index分析
目标用户偏好指数Target Group Index分析 TGI指数,全称Target Group Index,可以反映目标群体在特定研究范围内强势或者弱势. TGI指数计算公式 = 目标群体中具有某 ...
随机推荐
- 基本排序算法<二>
归并排序 归并排序,顾名思义,就是通过将两个有序的序列合并为一个大的有序的序列的方式来实现排序.合并排序是一种典型的分治算法:首先将序列分为两部分,然后对每一部分进行循环递归的排序,然后逐个将结果进行 ...
- angular页面缓存与页面刷新
angularJS学习笔记:页面缓存与页面刷新 遇到的问题 现在存在这样一个问题,登录前与登录成功后是同一个页面,只不过通过ngIf来控制哪部分显示,图像信息如下: 所以,整体工作不是很难,无非就 ...
- WARN Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect (org.apache.zookeeper.ClientCnxn)
[2017-05-19 13:32:14,933] INFO Waiting for keeper state SyncConnected (org.I0Itec.zkclient.ZkClient) ...
- 基于OWIN+DotNetOpenOAuth实现OAuth2.0
这几天时间一直在研究怎么实现自己的OAuth2服务器,对于太了解OAuth原理以及想自己从零开始实现的,我建议可以参考<Apress.Pro ASP.NET Web API Security&g ...
- Centos5搭建vsftpd服务
更换镜像源 由于centos5已经历史久远,内置的镜像源已经不能用.看: 因此,我手工更换了阿里云的源.(ps:我本来是想用网易的源,但不知为什么,这个源在安装vsftpd时提示http 404错误) ...
- Java基础知识二次学习--第三章 面向对象
第三章 面向对象 时间:2017年4月24日17:51:37~2017年4月25日13:52:34 章节:03章_01节 03章_02节 视频长度:30:11 + 21:44 内容:面向对象设计思 ...
- Java 多线程详解(五)------线程的声明周期
Java 多线程详解(一)------概念的引入:http://www.cnblogs.com/ysocean/p/6882988.html Java 多线程详解(二)------如何创建进程和线程: ...
- gradle windows 环境变量
我的电脑 -> 高级环境变量 GRADLE_HOME D:\soft\gradle-3.5 path %GRADLE_HOME%\bin
- hexo摸爬滚打之进阶教程
本文首发在我的个人博客:http://muyunyun.cn/ 写博客有三个层次,第一层次是借鉴居多的博文,第二层次是借鉴后经过消化后有一定量产出的博文,第三层次是原创好文居多的博文.在参考了大量前辈 ...
- General Thread States
对于实践中可能出现的各种General Thread States 以下列表描述了与常规查询处理关联的线程状态值,而不是更复杂的活动,例如复制. 其中许多仅用于在服务器中查找错误. after cre ...