day 10 字符编码和文件处理 细节整理
pycharm是文本编辑器。
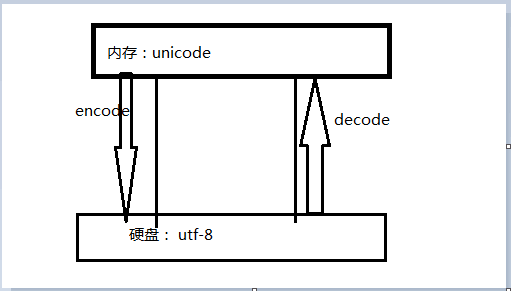
大概理解为: 输出到屏幕上的时候,是解码过的字符串,用 decode
处理的时候要编码成相应的流, encode 成你要用的格式就可以了
1 .字符编码:
字符====== (翻译过程)=======》数字。
utf-8是unicode的变种,是万国编码。
2. 文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失
因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
3. python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即执行时,才会识别python的语法,执行文件内代码,执行到name="ff",会开辟内存空间存放字符串"ff")
总结:python解释器于文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python语法)
1. 一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2. python中的数据类型字符串是由一串字符组成的(python文件执行时)
强调!!!
强调!!!!
强调!!!
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
哪些场景涉及字符编码?
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
什么是乱码
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败,用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis')
f.write('你瞅啥\n何を見て\n') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て\n'可以成功
但当我们用文件编辑器去存的时候,编辑器会帮我们做转换,保证中文也能用shiftjis存储(硬存,必然乱码),这就导致了,存文件阶段就已经发生乱码
此时当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
再或者,存文件时:
f=open('a.txt','wb')
f.write('何を見て\n'.encode('shift_jis'))
f.write('你愁啥\n'.encode('gbk'))
f.write('你看啥\n'.encode('utf-8'))
f.close()
以任何编码打开文件a.txt都会出现其余两个无法正常显示的问题
乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,而存文件时乱码,则是一种数据的损坏。
###程序的执行!!!
python test.py (我再强调一遍,执行test.py的第一步,一定是先将文件内容读入到内存中)
阶段一: 启动python解释器
阶段二: python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
阶段三: 读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="ff"
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='fly'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的'字符串',都是unicode,所以无论如何打印都不会乱码
字符编码就到这差不多就要结束了, 下面我代表组织给大家传达一下组织近期的精神。 我希望大家用心听,用心学,时间是宝贵的,我们要在最短的时间内,尽可能的学到更多更好更棒棒的东西哟! 每天进步一点点,一个星期就是一大步,不要和别人比,因为你需要战胜的只由你自己。加油 , 我们都是最棒的 !!!
总结!!!!
1 以什么编码存的就要以什么编码取出
ps:内存固定使用unicode编码,
我们可以控制的编码是往硬盘存放或者基于网络传输选择编码
2 数据是最先产生于内存中,是unicode格式,要想传输需要转成bytes格式
#unicode----->encode(utf-8)------>bytes
拿到bytes,就可以往文件内存放或者基于网络传输
#bytes------>decode(gbk)------->unicode
3 python3中字符串被识别成unicode
python3中的字符串encode得到bytes
4 了解
python2中的字符串就bytes
python2中在字符串前加u,就是unicode
以上就是字符编码的基础知识
下面我们就进入文件处理
一:文件操作的基本流程:
f = open('i.txt') #打开文件
first_line = f.readline()
print('first line:',first_line) #读一行
print('我是分隔线'.center(50,'-'))
data = f.read()# 读取剩下的所有内容,文件大时不要用
print(data) #打印读取内容
f.close() #关闭文件
#不指定打开编码,默认使用操作系统的编码,windows为gbk,linux为utf-8,与解释器编码无关
f=open('chenli.txt',encoding='gbk') #在windows中默认使用的也是gbk编码,此时不指定编码也行
f.read()
二: 文件的打开方式
文件句柄 = open('文件路径', '模式') #f=open('1.py,encoding='utf-8')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
# f=open(r'aaaa.py',encoding='utf-8') #x=1
# # print('+++++>1',f.read())
# # print(type(data))
# # print('+++++>2',f.read())
# # print('+++++>3',f.read())
# f.close()
# print(f)
# f.read()
# # del f
#open:
1: 会面向操作系统发起一个系统调用,操作会打开一个文件。
2:在python中会产生一个值 指向操作系统打开的那个文件,我们可以把该值赋给一个变量
#回收资源:
1:f.close()一定要做,关闭操作系统打开的文件,即回收操作系统的资源
2:del f: 没必要做,因为在python程序运行完毕后,会自动清理与该程序有关的所有内存空间。
#只读模式, 文件不存在报错
f = open('res.py',encoding='utf-8')
print(f.read())
print(f.readline(),end='')
print(f.readlines())
print(f.readable())
print(f.writable()) #False
f.close()
#文本文件:只写模式,文件不存在则创建空文件,文件存在则清空
# f=open('new.txt','w',encoding='utf-8')
# f.write('1111111\n')
# f.writelines(['22222\n','3333\n','444444\n'])
# # print(f.writable())
# f.close()
#文本文件:只追加写模式,文件不存在则创建,文件存在
# f=open('new_2','a',encoding='utf-8')
# print(f.readable())
# print(f.writable())
# f.write('33333\n')
# f.write('44444\n')
# f.writelines(['5555\n','6666\n'])
# f.close()
#rb
# f=open('aaaa.py','rb')
# print(f.read().decode('utf-8'))
# f=open('1.jpg','rb')
# data=f.read()
#wb
# f=open('2.jpg','wb')
# f.write(data)
# f=open('new_3.txt','wb')
# f.write('aaaaa\n'.encode('utf-8'))
#ab
f=open('new_3.txt','ab')
f.write('aaaaa\n'.encode('utf-8'))
#上下文管理
# with open('aaaa.py','r',encoding='utf-8') as read_f,\
# open('aaaa_new.py','w',encoding='utf-8') as write_f:
# data=read_f.read()
# write_f.write(data)
#循环取文件每一行内容
# with open('a.txt','r',encoding='utf-8') as f:
# while True:
# line=f.readline()
# if not line:break
# print(line,end='')
# lines=f.readlines() #只适用于小文件
# print(lines)
# data=f.read()
# print(type(data))
# for line in f: #推荐使用
# print(line,end='')
#文件的修改
#方式一:只适用于小文件
# import os
# with open('a.txt','r',encoding='utf-8') as read_f,\
# open('a.txt.swap','w',encoding='utf-8') as write_f:
# data=read_f.read()
# write_f.write(data.replace('alex_SB','alex_BSB'))
#
# os.remove('a.txt')
# os.rename('a.txt.swap','a.txt')
#方式二:
import os
with open('a.txt','r',encoding='utf-8') as read_f,\
open('a.txt.swap','w',encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('alex_BSB','BB_alex_SB'))
os.remove('a.txt')
os.rename('a.txt.swap','a.txt')
day 10 字符编码和文件处理 细节整理的更多相关文章
- Python-字典、集合、字符编码、文件操作整理-Day3
1.字典 1.1.为什么有字典: 有个需求,存所有人的信息 这时候列表就不能轻易的表示完全names = ['stone','liang'] 1.2.元组: 定义符号()t = (1,2,3)tupl ...
- python基础知识5---数据类型、字符编码、文件处理
阅读目录 一 引子 二 数字 三 字符串 四 列表 五 元组 六 字典 七 集合 八 数据类型总结 九 运算符 十 字符编码 十一 文件处理 十二 作业 一 引子 1 什么是数据? x=10,10 ...
- Python之字符编码与文件操作
目录 字符编码 Python2和Python3中字符串类型的差别 文件操作 文件操作的方式 文件内光标的移动 文件修改 字符编码 什么是字符编码? ''' 字符编码就是制定的一个将人类的语言的字符与二 ...
- python基础(三)----字符编码以及文件处理
字符编码与文件处理 一.字符编码 由字符翻译成二进制数字的过程 字符--------(翻译过程)------->数字 这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之 ...
- JAVA支持字符编码读取文件
文件操作,在java中很常用,对于存在特定编码的文件,则需要根据字符编码进行读取,要不容易出现乱码 /** * 读取文件 * @param filePath 文件路径 */ public static ...
- python文件操作:字符编码与文件处理
一.字符编码 二.文件处理 一.字符编码 储备知识点: 1. 计算机系统分为三层: 应用程序 操作系统 计算机硬件 2. 运行python程序的三个步骤 1. 先启动python解释器 2. 再将py ...
- python学习道路(day3note)(元组,字典 ,集合,字符编码,文件操作)
1.元组()元组跟列表一样,但是不能增删改,能查.元组又叫只读列表2个方法 一个 count 一个 index2.字典{}字典是通过key来寻找value因为这里功能比较多,所以写入了一个Code里面 ...
- python-02 数据类型、字符编码、文件处理
标准数据类型 Python3 中有六个标准的数据类型: Number(数字) String(字符串) List(列表) Tuple(元组) Sets(集合) Dictionary(字典) 数字 #整型 ...
- python基础语法、数据结构、字符编码、文件处理 练习题
考试范围 '''1.python入门:编程语言相关概念2.python基础语法:变量.运算符.流程控制3.数据结构:数字.字符串.列表.元组.字典.集合4.字符编码5.文件处理''' 考试内容 1.简 ...
随机推荐
- 河南省第八届ACM省赛---引水工程
引水工程 时间限制:2000 ms | 内存限制:65535 KB 难度: 描述 南水北调工程是优化水资源配置.促进区域协调发展的基础性工程,是新中国成立以来投资额最大.涉及面最广的战略性工程,事 ...
- 初识java这个小姑娘(二)
妙解垃圾回收机制 周一,早高峰. 一段考验一个人耐力.智力.开车技术以及脾气的路. 我把车开进了一个没有红绿灯的丁字路口,然后就没有然后了. 来自三个方向的大车小车开始在不大的一块空间里开始互相斗智斗 ...
- Git基本使用命令(windows)
1. 记住一个名词repository版本库 =======================基本操作======================== git init 在需要的地方建立一个版本库(也 ...
- 关于在linux下清屏的几种技巧(转载-备忘)
原文地址:http://www.cnblogs.com/5201351/p/4208277.html 在windows的DOS操作界面里面,清屏的命令是cls,那么在linux 里面的清屏命令是什么呢 ...
- Git~GitLab当它是一个CI工具时
CI我们都知道,它是持续集成的意思,主要可以自动处理包括编译,测试,发布等一系列的过程,而GitLab也同样包含了这些功能,我们可以通过pipeline很容易的实现一个软件从编译,测试,发布的自动化过 ...
- 移动 云MAS 发短信 .net HTTP 请求
本人开发移动云MAS .net Http 请求 代码如下 using Newtonsoft.Json.Linq; using System; using System.Collections.Gen ...
- linux 开机批量启动程序
每天早上到公司第一件事打开电脑,打开我的qq.我的开发工具idea.在看看邮件,日复一日,变懒了.也变聪明了,写了以下一段脚本 文件名称:mystart.sh #!bin/bash #检验我的开发工具 ...
- js通用方法检測浏览器是否已安装指定插件(IE与非IE通用)
/* * 检測是否已安装指定插件 * * pluginName 插件名称 */ function checkPlugins(pluginName) { var np = navigator.plugi ...
- 【Jquery】之DOM操作
Questions 本篇文章主要讲解Jquery中对DOM的操作,主要内容如下: 1 内容区 1.1 .addClass() (1).addClass(className) <!DOCT ...
- Spring Boot实战之逐行释义HelloWorld
一.前言 研究Spring boot也有一小段时间了,最近会将研究东西整理一下给大家分享,大概会有10~20篇左右的博客,整个系列会以一个简单的博客系统作为基础,因为光讲理论很多东西不是特别容易理解 ...