Python: Pandas的DataFrame如何按指定list排序
本文首发于微信公众号“Python数据之道”(ID:PyDataRoad)
前言
写这篇文章的起由是有一天微信上一位朋友问到一个问题,问题大体意思概述如下:
现在有一个pandas的Series和一个python的list,想让Series按指定的list进行排序,如何实现?
这个问题的需求用流程图描述如下:
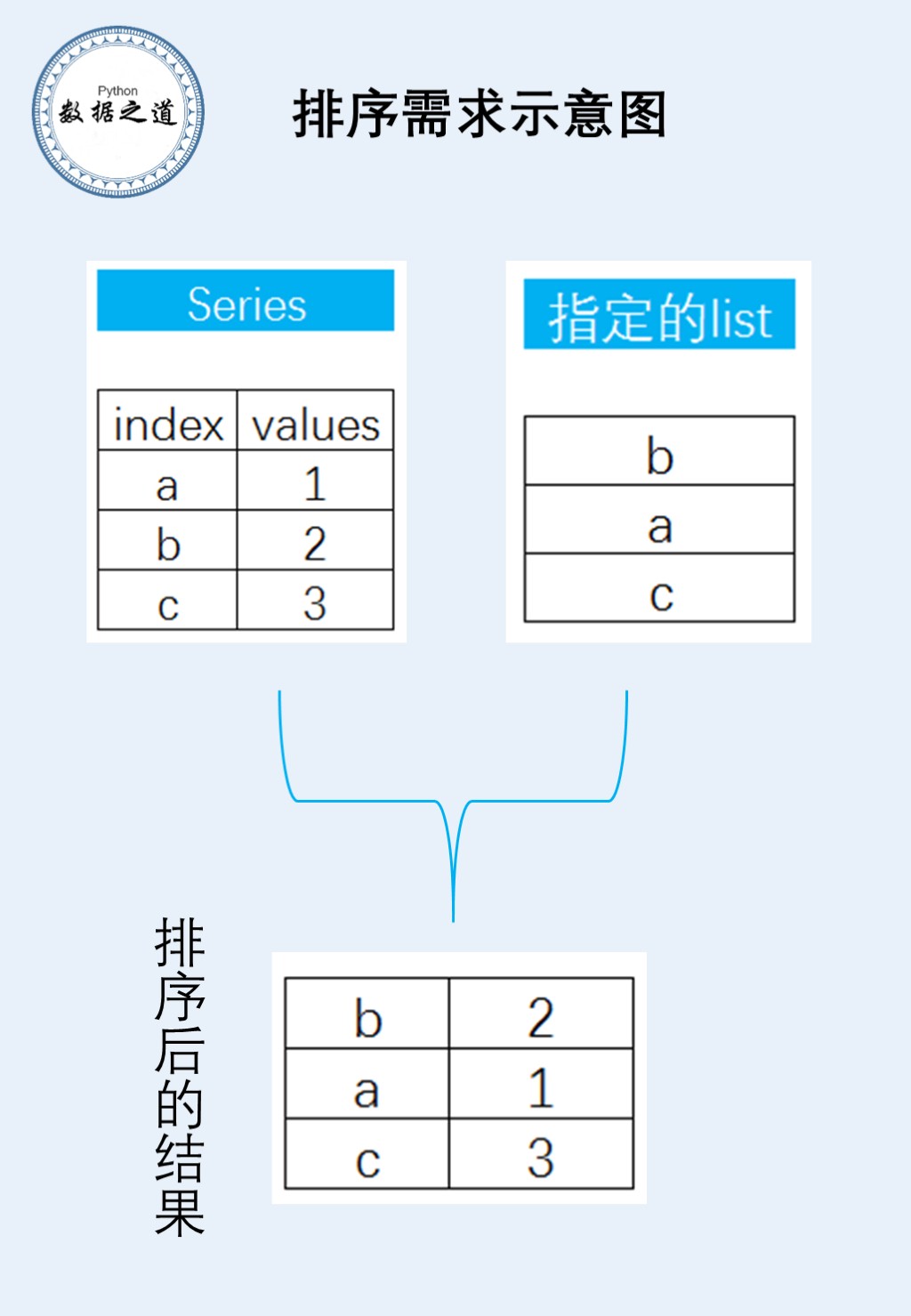
我思考了一下,这个问题解决的核心是引入pandas的数据类型“category”,从而进行排序。
在具体的分析过程中,先将pandas的Series转换成为DataFrame,然后设置数据类型,再进行排序。思路用流程图表示如下:
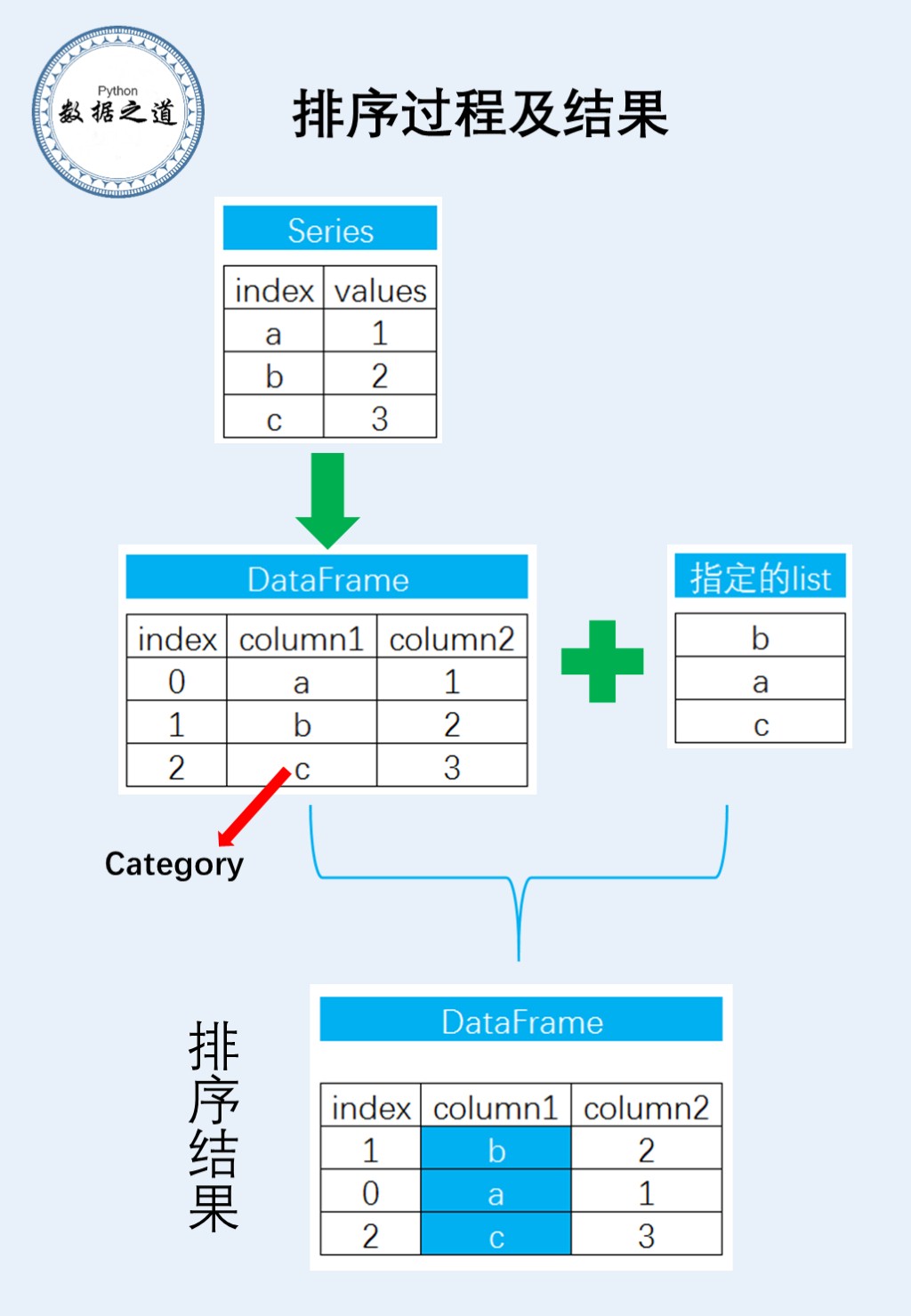
分析过程
- 引入pandas库
import pandas as pd
- 构造Series数据
s = pd.Series({'a':1,'b':2,'c':3})
s
a 1
b 2
c 3
dtype: int64
s.index
Index(['a', 'b', 'c'], dtype='object')
- 指定的list,后续按指定list的元素顺序进行排序
list_custom = ['b', 'a', 'c']
list_custom
['b', 'a', 'c']
- 将Series转换成DataFrame
df = pd.DataFrame(s)
df = df.reset_index()
df.columns = ['words', 'number']
df
| words | number | |
|---|---|---|
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
设置成“category”数据类型
# 设置成“category”数据类型
df['words'] = df['words'].astype('category')
# inplace = True,使 recorder_categories生效
df['words'].cat.reorder_categories(list_custom, inplace=True)
# inplace = True,使 df生效
df.sort_values('words', inplace=True)
df
| words | number | |
|---|---|---|
| 1 | b | 2 |
| 0 | a | 1 |
| 2 | c | 3 |
指定list元素多的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素多,怎么办?
- reorder_catgories()方法不能继续使用,因为该方法使用时要求新的categories和dataframe中的categories的元素个数和内容必须一致,只是顺序不同。
- 这种情况下,可以使用 set_categories()方法来实现。新的list可以比dataframe中元素多。
list_custom_new = ['d', 'c', 'b','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'b', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 1 | c | 3 |
| 0 | b | 2 |
| 2 | e | 1 |
指定list元素少的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素少,怎么办?
- 这种情况下,set_categories()方法还是可以使用的,只是没有的元素会以NaN表示
注意下面的list中没有元素“b”
list_custom_new = ['d', 'c','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 0 | NaN | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
总结
根据指定的list所包含元素比Dataframe中需要排序的列的元素的多或少,可以分为三种情况:
- 相等的情况下,可以使用 reorder_categories和 set_categories方法;
- list的元素比较多的情况下, 可以使用set_categories方法;
- list的元素比较少的情况下, 也可以使用set_categories方法,但list中没有的元素会在DataFrame中以NaN表示。
源代码
需要的童鞋可在微信公众号“Python数据之道”(ID:PyDataRoad)后台回复关键字获取视频,关键字如下:
“2017-025”(不含引号)
Python: Pandas的DataFrame如何按指定list排序的更多相关文章
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- python pandas.Series&&DataFrame&& set_index&reset_index
参考CookBook :http://pandas.pydata.org/pandas-docs/stable/cookbook.html Pandas set_index&reset_ind ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- python基础:如何使用python pandas将DataFrame转换为dict
之前在知乎上看到有网友提问,如何将DataFrame转换为dict,专门研究了一下,pandas在0.21.0版本中是提供了这个方法的.下面一起学习一下,通过调用help方法,该方法只需传入一个参数, ...
- python学习笔记—DataFrame和Series的排序
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> ################################### 排序 ################## ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- oracle数据据 Python+Pandas 获取Oracle数据库并加入DataFrame
import pandas as pd import sys import imp imp.reload(sys) from sqlalchemy import create_engine impor ...
- 【跟着stackoverflow学Pandas】 - Adding new column to existing DataFrame in Python pandas - Pandas 添加列
最近做一个系列博客,跟着stackoverflow学Pandas. 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stack ...
随机推荐
- html基础认识,高手别看
HTML5是一种用于在万维网上构建和呈现内容的符号言语.它是HTML规范的第五和当时版别.它是由万维网联盟(W3C)在十月发布的2014 [ 2 ] [ 4 ]和最新的多媒体支持进步言语,一起坚持它简 ...
- IDEA第二章----配置git、tomcat(热部署)、database,让你的项目跑起来
第一节:下载git客户端,整合idea 由于博主公司用的git版本管理,所以本系列都是基于git版本工具的,当然SVN与git配置类似.git同样支持安装版和解压版,支持各种操作系统,我这里下载的是W ...
- ASP.NET MVC 常用扩展点:过滤器、模型绑定等
一.过滤器(Filter) ASP.NET MVC中的每一个请求,都会分配给对应Controller(以下简称“控制器”)下的特定Action(以下简称“方法”)处理,正常情况下直接在方法里写代码就可 ...
- selenium IDE的3种下载安装方式
第一种方式: 打开firefox浏览器-----点击右上角-----附加组件----插件----搜索框输入“selenium”-----搜索的结果中下拉到页面尾部,点击“查看全部的37项结果”---进 ...
- js中面向对象编程
一.理解对象: 第一种:基于Object对象 var person = new Object(); person.name = 'My Name'; person.age = 18; person.g ...
- 利刃 MVVMLight 9:Messenger
MVVM的目标之一就是为了解耦View和ViewModel.View负责视图展示,ViewModel负责业务逻辑处理,尽量保证 View.xaml.cs中的简洁,不包含复杂的业务逻辑代码. 但是在实际 ...
- ng-options语法详解
我们先看下options的这条语句 ng-options="value.id as value.label group by value.group for value in myOptio ...
- c++ STL stack & queue
Stack 主要的方法有如下: empty() 堆栈为空则返回真 pop() 移除栈顶元素(不会返回栈顶元素的值) push() 在 ...
- poj 1056 IMMEDIATE DECODABILITY 字典树
题目链接:http://poj.org/problem?id=1056 思路: 字典树的简单应用,就是判断当前所有的单词中有木有一个是另一个的前缀,直接套用模板再在Tire定义中加一个bool类型的变 ...
- ionic之$ionicHistory
$ionicHistory 定义:当用户通过导航栏切换视图页面的时候,ionicHistory起到跟踪视图的作用,类似的浏览器的行为方式,一个ionic应用程序能够保持以前的视图,当前视图,和前视图( ...